Amazon Web Services ブログ
Amazon Nova Multimodal Embeddings: エージェントティック RAG およびセマンティック検索のための最先端の埋め込みモデル
10 月 28 日、エージェンティック検索拡張生成 (RAG)およびセマンティック検索アプリケーション向けの最先端のマルチモーダル埋め込みモデルである Amazon Nova Multimodal Embeddings をご紹介します。このモデルは Amazon Bedrock でご利用いただけます。これは、テキスト、ドキュメント、画像、動画、音声を単一のモデルを通じてサポートし、極めて高い精度のクロスモーダル検索を可能にする初の統合埋め込みモデルです。
埋め込みモデルは、テキスト、画像、音声の入力を、埋め込みと呼ばれる数値表現に変換します。これらの埋め込みは、AI システムが比較、検索、分析できるように入力の意味を捉え、セマンティック検索や RAG などのユースケースを強化します。
組織は、テキスト、画像、ドキュメント、動画、音声コンテンツに分散している、増大し続ける非構造化データからインサイトを引き出すソリューションをますます求めています。例えば、組織には、製品の画像、インフォグラフィックとテキストを含むパンフレット、ユーザーがアップロードした動画クリップなどが存在する場合があります。埋め込みモデルは非構造化データから価値を引き出すことができますが、従来のモデルは通常、1 つのコンテンツタイプを処理するように特化しています。この制限により、お客様は、複雑なクロスモーダル埋め込みソリューションを構築するか、または単一のコンテンツタイプに特化したユースケースに制限せざるを得なくなります。また、この問題は、テキストと画像がインターリーブされたドキュメントや、ビジュアル、音声、テキスト要素を含む動画など、混合モーダルのコンテンツタイプにも当てはまります。これらのコンテンツタイプでは、既存のモデルでは、クロスモーダル関係を効果的に捉えることが困難です。
Nova Multimodal Embeddings は、混合モーダルコンテンツ間のクロスモーダル検索、参照画像を使った検索、ビジュアルドキュメントの取得などのユースケースにおいて、テキスト、ドキュメント、画像、動画、音声のための統合セマンティック空間をサポートします。
Amazon Nova Multimodal Embeddings のパフォーマンスの評価
幅広いベンチマークでモデルを評価した結果、次の表に示すとおり、すぐに活用できる極めて優れた精度を実現しました。
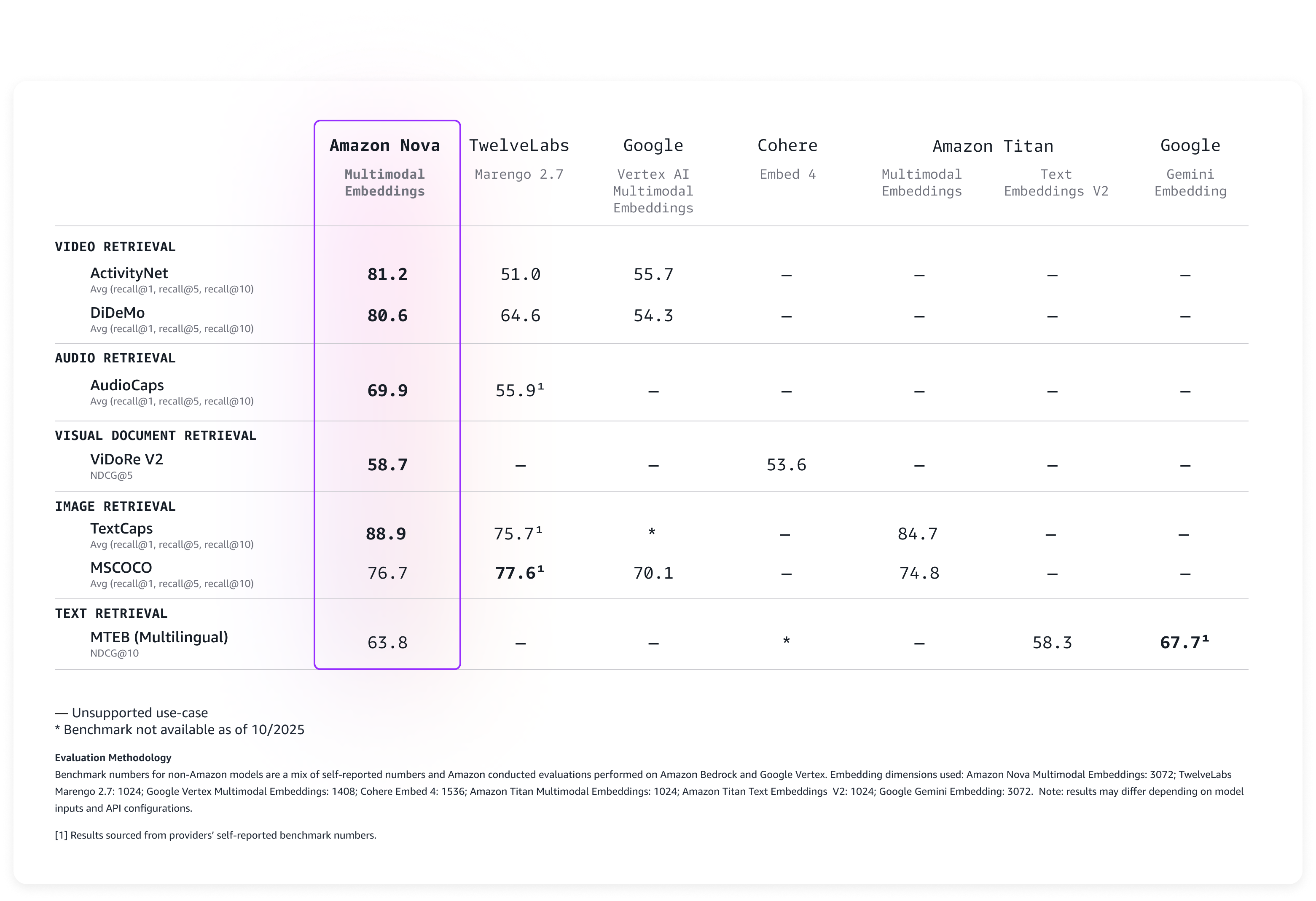
Nova Multimodal Embeddings は、最大 8K トークンのコンテキスト長、最大 200 言語のテキストをサポートし、同期および非同期 API を介して入力を受け付けます。さらに、セグメンテーション (「チャンキング」とも呼ばれます) をサポートし、長文のテキスト、動画、音声コンテンツを扱いやすいセグメントにパーティショニングし、各部分の埋め込みを生成します。最後に、このモデルは 4 つの出力埋め込みディメンションを提供します。これらの埋め込みディメンションは、Matryoshka Representation Learning (MRL) を使用してトレーニングされており、精度の変動を最小限に抑えながら、低レイテンシーのエンドツーエンド検索を可能にします。
実際に新しいモデルをどのように使用できるのかを見てみましょう。
Amazon Nova Multimodal Embeddings の使用
Nova Multimodal Embeddings の開始方法は、Amazon Bedrock の他のモデルと同じパターンに従います。このモデルは、テキスト、ドキュメント、画像、動画、または音声を入力として受け入れ、セマンティック検索、類似度比較、または RAG に使用できる数値埋め込みを返します。
ここでは、AWS SDK for Python (Boto3) を使用して、さまざまなコンテンツタイプから埋め込みを作成し、後で取得できるように保存する方法を示す実用的な例を示します。簡潔にするために、埋め込みの保存と検索には、あらゆる規模のベクトルの保存とクエリをネイティブにサポートするコスト最適化ストレージである Amazon S3 Vectors を使用します。
まずは基本、すなわち、テキストを埋め込みに変換することから始めましょう。この例では、シンプルなテキスト記述を、その意味論的意味を捉えた数値表現に変換する方法を示します。これらの埋め込みは、後でドキュメント、画像、動画、音声からの埋め込みと比較することで、関連コンテンツを見つけることができます。
コードを理解しやすくするために、一度に示すのはスクリプトの一部にとどめます。完全なスクリプトはこのウォークスルーの最後に含まれています。
import json
import base64
import time
import boto3
MODEL_ID = "amazon.nova-2-multimodal-embeddings-v1:0"
EMBEDDING_DIMENSION = 3072
# Amazon Bedrock ランタイムクライアントを初期化します
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
print(f"Generating text embedding with {MODEL_ID} ...")
# 埋め込むテキスト
text = "Amazon Nova is a multimodal foundation model"
# 埋め込みを作成します
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": text},
},
}
response = bedrock_runtime.invoke_model(
body=json.dumps(request_body),
modelId=MODEL_ID,
contentType="application/json",
)
# 埋め込みを抽出します
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
print(f"Generated embedding with {len(embedding)} dimensions")次に、スクリプトと同じフォルダにある photo.jpg ファイルを使用して、同じ埋め込み空間でビジュアルコンテンツを処理します。これは、マルチモーダリティの力を示しています。Nova Multimodal Embeddings は、テキストとビジュアルの両方のコンテキストを単一の埋め込みに取り込むことができ、ドキュメントをより深く理解できるようにします。
Nova Multimodal Embeddings は、使用方法に合わせて最適化された埋め込みを生成できます。検索または取得のユースケースのためにインデックスを作成する場合、embeddingPurpose を GENERIC_INDEX に設定できます。クエリステップでは、取得する項目のタイプに応じて embeddingPurpose を設定できます。例えば、ドキュメントを取得する場合、embeddingPurpose を DOCUMENT_RETRIEVAL に設定できます。
# 画像を読み取ってエンコードします
print(f"Generating image embedding with {MODEL_ID} ...")
with open("photo.jpg", "rb") as f:
image_bytes = base64.b64encode(f.read()).decode("utf-8")
# 埋め込みを作成します
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"image": {
"format": "jpeg",
"source": {"bytes": image_bytes}
},
},
}
response = bedrock_runtime.invoke_model(
body=json.dumps(request_body),
modelId=MODEL_ID,
contentType="application/json",
)
# 埋め込みを抽出します
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
print(f"Generated embedding with {len(embedding)} dimensions")動画コンテンツの処理には、非同期 API を使用します。これは、Base64 としてエンコードされたときに 25 MB を超える動画の要件です。まず、同じ AWS リージョン内の S3 バケットにローカル動画をアップロードします。
aws s3 cp presentation.mp4 s3://my-video-bucket/videos/この例では、動画ファイルのビジュアルと音声の両方のコンポーネントから埋め込み情報を抽出する方法を示します。セグメンテーション特徴量により、長い動画が扱いやすいチャンクに分割されるため、何時間にも及ぶコンテンツを効率的に検索できます。
# Amazon S3 クライアントを初期化します
s3 = boto3.client("s3", region_name="us-east-1")
print(f"Generating video embedding with {MODEL_ID} ...")
# Amazon S3 URI
S3_VIDEO_URI = "s3://my-video-bucket/videos/presentation.mp4"
S3_EMBEDDING_DESTINATION_URI = "s3://my-embedding-destination-bucket/embeddings-output/"
# 音声付き動画の非同期埋め込みジョブを作成します
model_input = {
"taskType": "SEGMENTED_EMBEDDING",
"segmentedEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"video": {
"format": "mp4",
"embeddingMode": "AUDIO_VIDEO_COMBINED",
"source": {
"s3Location": {"uri": S3_VIDEO_URI}
},
"segmentationConfig": {
"durationSeconds": 15 # 15 秒単位のチャンクにセグメント化します
},
},
},
}
response = bedrock_runtime.start_async_invoke(
modelId=MODEL_ID,
modelInput=model_input,
outputDataConfig={
"s3OutputDataConfig": {
"s3Uri": S3_EMBEDDING_DESTINATION_URI
}
},
)
invocation_arn = response["invocationArn"]
print(f"Async job started: {invocation_arn}")
# ジョブが完了するまでポーリングします
print("\nPolling for job completion...")
while True:
job = bedrock_runtime.get_async_invoke(invocationArn=invocation_arn)
status = job["status"]
print(f"Status: {status}")
if status != "InProgress":
break
time.sleep(15)
# ジョブが正常に完了したかどうかをチェックします
if status == "Completed":
output_s3_uri = job["outputDataConfig"]["s3OutputDataConfig"]["s3Uri"]
print(f"\nSuccess! Embeddings at: {output_s3_uri}")
# S3 URI を解析してバケットとプレフィックスを取得します
s3_uri_parts = output_s3_uri[5:].split("/", 1) # プレフィックス「s3://」を削除します
bucket = s3_uri_parts[0]
prefix = s3_uri_parts[1] if len(s3_uri_parts) > 1 else ""
# AUDIO_VIDEO_COMBINED モードは、embedding-audio-video.jsonl に出力します
# output_s3_uri には既にジョブ ID が含まれているため、ファイル名を付加するだけです
embeddings_key = f"{prefix}/embedding-audio-video.jsonl".lstrip("/")
print(f"Reading embeddings from: s3://{bucket}/{embeddings_key}")
# JSONL ファイルを読み取って解析します
response = s3.get_object(Bucket=bucket, Key=embeddings_key)
content = response['Body'].read().decode('utf-8')
embeddings = []
for line in content.strip().split('\n'):
if line:
embeddings.append(json.loads(line))
print(f"\nFound {len(embeddings)} video segments:")
for i, segment in enumerate(embeddings):
print(f" Segment {i}: {segment.get('startTime', 0):.1f}s - {segment.get('endTime', 0):.1f}s")
print(f" Embedding dimension: {len(segment.get('embedding', []))}")
else:
print(f"\nJob failed: {job.get('failureMessage', 'Unknown error')}")埋め込みを生成したら、それらを効率的に保存および検索するための場所が必要です。この例では、大規模な類似性検索に必要となるインフラストラクチャを提供する Amazon S3 Vectors を使用してベクトルストアをセットアップする方法を示します。これは、意味論的に類似したコンテンツが自然にクラスター化される、検索可能なインデックスを作成するものと考えてください。インデックスに埋め込みを追加する際、メタデータを使用して元の形式とインデックスの作成対象のコンテンツを指定します。
# Amazon S3 Vectors クライアントを初期化します
s3vectors = boto3.client("s3vectors", region_name="us-east-1")
# 設定
VECTOR_BUCKET = "my-vector-store"
INDEX_NAME = "embeddings"
# ベクトルバケットとインデックスを作成します (存在していない場合)
try:
s3vectors.get_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Vector bucket {VECTOR_BUCKET} already exists")
except s3vectors.exceptions.NotFoundException:
s3vectors.create_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Created vector bucket: {VECTOR_BUCKET}")
try:
s3vectors.get_index(vectorBucketName=VECTOR_BUCKET, indexName=INDEX_NAME)
print(f"Vector index {INDEX_NAME} already exists")
except s3vectors.exceptions.NotFoundException:
s3vectors.create_index(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
dimension=EMBEDDING_DIMENSION,
dataType="float32",
distanceMetric="cosine"
)
print(f"Created index: {INDEX_NAME}")
texts = [
"Machine learning on AWS",
"Amazon Bedrock provides foundation models",
"S3 Vectors enables semantic search"
]
print(f"\nGenerating embeddings for {len(texts)} texts...")
# Amazon Nova を使用して各テキストの埋め込みを生成します
vectors = []
for text in texts:
response = bedrock_runtime.invoke_model(
body=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": text}
}
}),
modelId=MODEL_ID,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
vectors.append({
"key": f"text:{text[:50]}", # 一意の識別子
"data": {"float32": embedding},
"metadata": {"type": "text", "content": text}
})
print(f" ✓ Generated embedding for: {text}")
# 1 回の呼び出しで、保存するすべてのベクトルを追加します
s3vectors.put_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
vectors=vectors
)
print(f"\nSuccessfully added {len(vectors)} vectors to the store in one put_vectors call!")この最後の例では、単一のクエリでさまざまなコンテンツタイプを検索し、テキスト、画像、動画、音声のいずれから生成されたかにかかわらず、最も類似したコンテンツを見つける機能を示します。距離スコアは、結果が元のクエリとどの程度関連しているのかを理解するのに役立ちます。
# クエリするテキスト
query_text = "foundation models"
print(f"\nGenerating embeddings for query '{query_text}' ...")
# 埋め込みを生成します
response = bedrock_runtime.invoke_model(
body=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": query_text}
}
}),
modelId=MODEL_ID,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response["body"].read())
query_embedding = response_body["embeddings"][0]["embedding"]
print(f"Searching for similar embeddings...\n")
# 最も類似した上位 5 つのベクトルを検索します
response = s3vectors.query_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
queryVector={"float32": query_embedding},
topK=5,
returnDistance=True,
returnMetadata=True
)
# 結果を表示します
print(f"Found {len(response['vectors'])} results:\n")
for i, result in enumerate(response["vectors"], 1):
print(f"{i}. {result['key']}")
print(f" Distance: {result['distance']:.4f}")
if result.get("metadata"):
print(f" Metadata: {result['metadata']}")
print()クロスモーダル検索は、マルチモーダル埋め込みの重要な利点の 1 つです。クロスモーダル検索を使用すると、テキストでクエリして、関連する画像を見つけることができます。また、テキストの説明を使用して動画を検索したり、特定のトピックに一致する音声クリップを見つけたり、ビジュアルとテキストのコンテンツに基づいてドキュメントを検出したりすることもできます。ご参考までに、これまでの例をすべてまとめた完全なスクリプトをこちらに示します:
import json
import base64
import time
import boto3
MODEL_ID = "amazon.nova-2-multimodal-embeddings-v1:0"
EMBEDDING_DIMENSION = 3072
# Amazon Bedrock ランタイムクライアントを初期化します
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
print(f"Generating text embedding with {MODEL_ID} ...")
# 埋め込むテキスト
text = "Amazon Nova is a multimodal foundation model"
# 埋め込みを作成します
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": text},
},
}
response = bedrock_runtime.invoke_model(
body=json.dumps(request_body),
modelId=MODEL_ID,
contentType="application/json",
)
# 埋め込みを抽出します
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
print(f"Generated embedding with {len(embedding)} dimensions")
# 画像を読み取ってエンコードします
print(f"Generating image embedding with {MODEL_ID} ...")
with open("photo.jpg", "rb") as f:
image_bytes = base64.b64encode(f.read()).decode("utf-8")
# 埋め込みを作成します
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"image": {
"format": "jpeg",
"source": {"bytes": image_bytes}
},
},
}
response = bedrock_runtime.invoke_model(
body=json.dumps(request_body),
modelId=MODEL_ID,
contentType="application/json",
)
# 埋め込みを抽出します
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
print(f"Generated embedding with {len(embedding)} dimensions")
# Amazon S3 クライアントを初期化します
s3 = boto3.client("s3", region_name="us-east-1")
print(f"Generating video embedding with {MODEL_ID} ...")
# Amazon S3 URI
S3_VIDEO_URI = "s3://my-video-bucket/videos/presentation.mp4"
# Amazon S3 出力バケットと場所
S3_EMBEDDING_DESTINATION_URI = "s3://my-video-bucket/embeddings-output/"
# 音声付き動画の非同期埋め込みジョブを作成します
model_input = {
"taskType": "SEGMENTED_EMBEDDING",
"segmentedEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"video": {
"format": "mp4",
"embeddingMode": "AUDIO_VIDEO_COMBINED",
"source": {
"s3Location": {"uri": S3_VIDEO_URI}
},
"segmentationConfig": {
"durationSeconds": 15 # 15 秒単位のチャンクにセグメント化します
},
},
},
}
response = bedrock_runtime.start_async_invoke(
modelId=MODEL_ID,
modelInput=model_input,
outputDataConfig={
"s3OutputDataConfig": {
"s3Uri": S3_EMBEDDING_DESTINATION_URI
}
},
)
invocation_arn = response["invocationArn"]
print(f"Async job started: {invocation_arn}")
# ジョブが完了するまでポーリングします
print("\nPolling for job completion...")
while True:
job = bedrock_runtime.get_async_invoke(invocationArn=invocation_arn)
status = job["status"]
print(f"Status: {status}")
if status != "InProgress":
break
time.sleep(15)
# ジョブが正常に完了したかどうかをチェックします
if status == "Completed":
output_s3_uri = job["outputDataConfig"]["s3OutputDataConfig"]["s3Uri"]
print(f"\nSuccess! Embeddings at: {output_s3_uri}")
# S3 URI を解析してバケットとプレフィックスを取得します
s3_uri_parts = output_s3_uri[5:].split("/", 1) # プレフィックス「s3://」を削除します
bucket = s3_uri_parts[0]
prefix = s3_uri_parts[1] if len(s3_uri_parts) > 1 else ""
# AUDIO_VIDEO_COMBINED モードは、embedding-audio-video.jsonl に出力します
# output_s3_uri には既にジョブ ID が含まれているため、ファイル名を付加するだけです
embeddings_key = f"{prefix}/embedding-audio-video.jsonl".lstrip("/")
print(f"Reading embeddings from: s3://{bucket}/{embeddings_key}")
# JSONL ファイルを読み取って解析します
response = s3.get_object(Bucket=bucket, Key=embeddings_key)
content = response['Body'].read().decode('utf-8')
embeddings = []
for line in content.strip().split('\n'):
if line:
embeddings.append(json.loads(line))
print(f"\nFound {len(embeddings)} video segments:")
for i, segment in enumerate(embeddings):
print(f" Segment {i}: {segment.get('startTime', 0):.1f}s - {segment.get('endTime', 0):.1f}s")
print(f" Embedding dimension: {len(segment.get('embedding', []))}")
else:
print(f"\nJob failed: {job.get('failureMessage', 'Unknown error')}")
# Amazon S3 Vectors クライアントを初期化します
s3vectors = boto3.client("s3vectors", region_name="us-east-1")
# 設定
VECTOR_BUCKET = "my-vector-store"
INDEX_NAME = "embeddings"
# ベクトルバケットとインデックスを作成します (存在していない場合)
try:
s3vectors.get_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Vector bucket {VECTOR_BUCKET} already exists")
except s3vectors.exceptions.NotFoundException:
s3vectors.create_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Created vector bucket: {VECTOR_BUCKET}")
try:
s3vectors.get_index(vectorBucketName=VECTOR_BUCKET, indexName=INDEX_NAME)
print(f"Vector index {INDEX_NAME} already exists")
except s3vectors.exceptions.NotFoundException:
s3vectors.create_index(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
dimension=EMBEDDING_DIMENSION,
dataType="float32",
distanceMetric="cosine"
)
print(f"Created index: {INDEX_NAME}")
texts = [
"Machine learning on AWS",
"Amazon Bedrock provides foundation models",
"S3 Vectors enables semantic search"
]
print(f"\nGenerating embeddings for {len(texts)} texts...")
# Amazon Nova を使用して各テキストの埋め込みを生成します
vectors = []
for text in texts:
response = bedrock_runtime.invoke_model(
body=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": text}
}
}),
modelId=MODEL_ID,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
vectors.append({
"key": f"text:{text[:50]}", # 一意の識別子
"data": {"float32": embedding},
"metadata": {"type": "text", "content": text}
})
print(f" ✓ Generated embedding for: {text}")
# 1 回の呼び出しで、保存するすべてのベクトルを追加します
s3vectors.put_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
vectors=vectors
)
print(f"\nSuccessfully added {len(vectors)} vectors to the store in one put_vectors call!")
# クエリするテキスト
query_text = "foundation models"
print(f"\nGenerating embeddings for query '{query_text}' ...")
# 埋め込みを生成します
response = bedrock_runtime.invoke_model(
body=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": query_text}
}
}),
modelId=MODEL_ID,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response["body"].read())
query_embedding = response_body["embeddings"][0]["embedding"]
print(f"Searching for similar embeddings...\n")
# 最も類似した上位 5 つのベクトルを検索します
response = s3vectors.query_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
queryVector={"float32": query_embedding},
topK=5,
returnDistance=True,
returnMetadata=True
)
# 結果を表示します
print(f"Found {len(response['vectors'])} results:\n")
for i, result in enumerate(response["vectors"], 1):
print(f"{i}. {result['key']}")
print(f" Distance: {result['distance']:.4f}")
if result.get("metadata"):
print(f" Metadata: {result['metadata']}")
print()本番アプリケーションでは、埋め込みは任意のベクトルデータベースに保存できます。Amazon OpenSearch Service は、リリース時に Nova Multimodal Embeddings とのネイティブ統合を提供しているため、スケーラブルな検索アプリケーションを簡単に構築できます。前の例で示したように、Amazon S3 Vectors を使用すると、アプリケーションデータを使用して埋め込みを簡単に保存およびクエリできます。
知っておくべきこと
Nova Multimodal Embeddings は、3,072、1,024、384、256 の 4 つの出力ディメンションオプションを提供します。ディメンションが大きいほど詳細な表現が得られますが、より多くのストレージと計算が必要になります。ディメンションが小さいほど、検索パフォーマンスとリソース効率の実用的なバランスを実現できます。この柔軟性は、特定のアプリケーションとコスト要件に合わせて最適化するのに役立ちます。
このモデルは、かなり長いコンテキストを処理できます。テキスト入力では、一度に最大 8,192 トークンを処理できます。動画と音声の入力は最大 30 秒のセグメントをサポートし、モデルはより長いファイルをセグメント化できます。このセグメンテーション機能は、特に大容量のメディアファイルを扱う際に役立ちます。モデルはファイルを扱いやすいサイズに分割し、各セグメントの埋め込みを作成します。
このモデルには、Amazon Bedrock に組み込まれた責任ある AI の機能が含まれています。埋め込み用に送信されたコンテンツは、Amazon Bedrock のコンテンツセーフティフィルターを通過します。また、モデルには、バイアスを低減するための公平性対策が含まれています。
コード例で説明されているように、このモデルは同期 API と非同期 API の両方を通じて呼び出すことができます。同期 API は、検索インターフェイスでのユーザークエリの処理など、即時の応答が必要なリアルタイムアプリケーションに適しています。非同期 API は、レイテンシーの影響が小さいワークロードをより効率的に処理するため、動画などの大容量コンテンツの処理に適しています。
利用可能なリージョンと料金
Amazon Nova Multimodal Embeddings は、米国東部 (バージニア北部) の AWS リージョンの Amazon Bedrock で本日よりご利用いただけます。料金の詳細については、Amazon Bedrock の料金ページにアクセスしてください。
詳しくは、包括的なドキュメントについては「Amazon Nova ユーザーガイド」、実用的なコード例については GitHub の Amazon Nova モデルクックブックをご覧ください。
Amazon Q Developer や Kiro などの AI を利用したアシスタントをソフトウェア開発に使用している場合は、AI アシスタントが AWS のサービスやリソースとインタラクションするのに役立つように AWS API MCP サーバーをセットアップしたり、最新のドキュメント、コードサンプル、AWS API と CloudFormation リソースのリージョンレベルの可用性に関するナレッジを提供するために AWS Knowledge MCP サーバーをセットアップしたりできます。
今すぐ Nova Multimodal Embeddings を使用してマルチモーダル AI を利用したアプリケーションの構築を開始し、AWS re:Post for Amazon Bedrock または通常の AWS サポートの連絡先を通じてフィードバックをぜひお寄せください。
– Danilo
原文はこちらです。