Amazon Web Services ブログ
BMW Group が AWS 上のエージェンティック検索でペタバイト規模のデータからインサイトを引き出す
本記事は、2026 年 1 月 30 日に公開された BMW Group unlocks insights from petabytes of data with agentic search on AWS を翻訳したものです。
ドイツのミュンヘンに本社を置く BMW Group は、15 か国の 30 か所以上の生産・組立施設で 159,000 人の従業員を雇用しています。BMW Group は自動車イノベーションのリーダーとして、データと人工知能 (AI) を活用し、デジタルトランスフォーメーションの最前線に立ち続けています。2020 年、BMW Group は Cloud Data Hub (CDH) を立ち上げました。現在、これは Data Lakehouse として運用されており、クラウド上で全社的なデータとデータソリューションを管理するための BMW Group の中央プラットフォームとなっています。これにより、全社の従業員に対し、データ駆動型アプリケーションの実装とデータインサイト生成の中心的な基盤を提供しています。
現在、CDH は 20 PB のデータを保存し、1 日平均 110 TB のデータを取り込んでいます。この膨大なデータから洞察を抽出することは、特に技術的および分析的な専門知識を持たないユーザーにとっては困難な場合があります。関連するデータソースを特定し、複雑なクエリを構築し、表形式の出力を解釈する必要があるためです。
本記事では、BMW Group が AWS Professional Services と協力して、Amazon S3 Vectors、Amazon Bedrock、Amazon Bedrock AgentCore の機能を組み合わせたエージェンティック検索ソリューションを開発した方法を説明します。このソリューションは、技術スキルに関係なく、BMW Group のユーザーが自然言語を使用して大規模なデータセットから実用的なデータインサイトを抽出できるように設計されています。
課題: データとインサイトのギャップの解消
従来のデータ分析ワークフローは複雑で時間がかかり、企業データから価値ある洞察を迅速に引き出すことを妨げる障壁となっています。プロセスはデータの発見から始まり、ユーザーは適切なデータソースを見つけるために、数十、数百、あるいは数千ものデータアセットを検索する必要があります。次に、ユーザーは SQL クエリを記述して実行する必要があり、複雑な結合や集計にはスキーマの知識が必要です。クエリ結果を生成した後、生の表形式の出力を実用的な洞察に変換するには、特定のドメイン専門知識が必要になることがよくあります。これらの課題は、特に構造化データと非構造化データを組み合わせる場合、組織がデータアセットを効果的に活用する能力を著しく制限する可能性があります。
ソリューション概要
BMW Group のエージェンティック検索ソリューションは、AI エージェントフレームワーク内で 3 つの補完的な検索アプローチを組み合わせることで、大規模なデータセットからインサイトを抽出するという課題に対処します。このソリューションにより、ユーザーは自然言語を使用してペタバイト規模の構造化データと非構造化データをクエリでき、クエリの特性に基づいて最適な検索戦略が自動的に選択されます。
本記事では、車両テストで報告された問題の詳細な記録を収集する製品品質システムのデータセットを使用してソリューションを紹介します。各レコードには、問題の説明、分類、技術的な詳細がドイツ語と英語の両方で含まれており、世界中の生産施設やサービスセンターから蓄積されたものです。このデータセットは、何年にもわたる品質エンジニアリングの知識を表しており、意味的に類似した問題がチームや言語によって異なる用語で記述されています。
このアーキテクチャは、それぞれ特定の検索パターン向けに設計された 3 つの専門ツールで構成されています。
- ハイブリッド検索: セマンティック検索と SQL フィルタリングを組み合わせて、概念的に類似したデータを効率的に取得します。このツールは、まずベクトルベースのセマンティック検索を実行して関連するレコードを特定し、次に SQL フィルタを適用して正確に絞り込みます。「特定の車両モデルのブレーキシステムに関するフィードバックを検索する」など、概念的な理解と構造化されたフィルタリングの両方が必要なクエリに最適です。
- 網羅的検索: AI を活用した評価を使用して、セマンティック検索だけでは用語のバリエーションにより関連する結果を見逃す可能性がある場合に、一致するすべてのレコードを包括的に分析します。このツールは SQL クエリを実行して候補レコードを取得し、次に大規模言語モデル (LLM) を使用して各結果を評価し、詳細な推論で関連性を判断します。「ブレーキ関連の問題は何件発生しましたか?」など、完全なカバレッジが不可欠な質問に特に効果的です。
- SQL クエリ: セマンティック分析が不要な場合に、正確なデータ取得のための直接的な構造化クエリ機能を提供します。このツールは、構造化されたデータフィールドに対する集計、カウント、統計分析などの純粋な分析クエリを処理します。
AI エージェントがこれらのツールを統制し、各ユーザークエリを分析して最も適切な検索戦略を決定します。エージェントは、概念的なクエリにはセマンティック検索、包括的な分析には網羅的検索、構造化された分析には直接 SQL を自動的に切り替えます。これらすべてが単一の会話型インターフェースを通じて実行されます。このインテリジェントなルーティングにより、ユーザーは基盤となる技術的な複雑さを理解したり、検索方法を手動で選択したりすることなく、関連する結果を受け取ることができます。
アーキテクチャの詳細
次のアーキテクチャ図は、これらのコンポーネントがどのように連携してエージェンティック検索体験を提供するかを示しています。
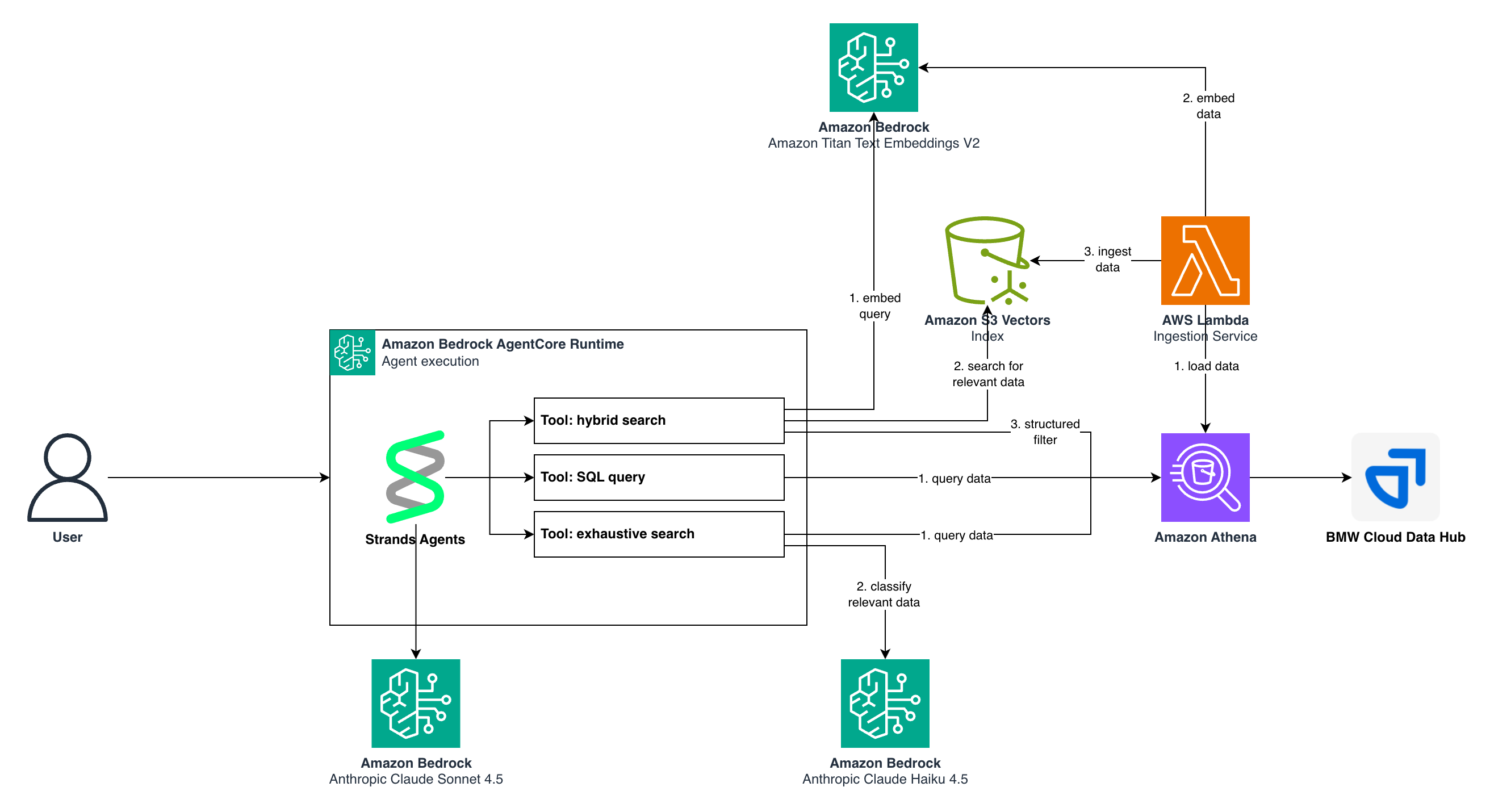
図 1. エージェンティック検索ソリューションのアーキテクチャ
コアコンポーネント
データストレージとベクトル検索
Amazon S3 Vectors (S3 Vectors) は、ベクトル埋め込みに対するセマンティック検索を可能にし、専用のベクトルデータベースインフラストラクチャを必要とせずに、数百万のデータポイントにわたる効率的な最近傍クエリをサポートします。S3 Vectors の構造化データに対しては、Amazon Athena (Athena) がサーバーレス SQL クエリ実行を提供し、元のソースデータに対するアドホック分析と構造化フィルタリングを可能にします。
LLM とエージェントの実装
Amazon Bedrock (Bedrock) は、複数の LLM でソリューションを強化します。ベクトル埋め込みの生成には Amazon Titan Text Embeddings V2 (Titan Text Embeddings) を使用し、エージェントのオーケストレーションのための主要な推論モデルとして Anthropic の Claude Sonnet 4.5 を使用し、網羅的検索におけるコスト効率の高い分類タスクには Anthropic の Claude Haiku 4.5 を使用します。AWS のオープンソースフレームワークである Strands Agents は、ツールの選択、会話フロー、モデルとのインタラクションを管理しながら、本番環境レベルの信頼性を維持して AI エージェントをオーケストレーションします。
データ取り込みとベクトルインデックスの作成
エージェンティック検索ソリューションがクエリに回答する前に、ソースデータを処理し、セマンティック検索用にインデックス化する必要があります。ここでは、AWS Lambda (Lambda) を使用してサーバーレスの取り込みパイプラインを実装し、タイトルや説明などの自由形式のテキスト属性を含む構造化データベースレコードを、検索可能なベクトル埋め込みに変換しました。
取り込みプロセスは、次のステップに従います。
- データ抽出: Lambda 関数は Amazon Athena でソースデータベーステーブルをクエリし、ドイツ語と英語の両方で問題の説明、タイトル、分類を含む製品品質レコードを取得します。
- テキスト準備: 各レコードに対して、パイプラインは意味的に関連するフィールド (クラスター名、問題タイトル、説明) を連結し、埋め込み生成に適した統一されたテキスト表現を作成します。
- 埋め込み生成: 準備されたテキストは Titan Text Embeddings に送信され、各レコードの意味的な意味を捉える 1,024 次元のベクトル埋め込みが生成されます。
- ベクトルストレージ: 埋め込みは S3 Vectors インデックス形式を使用して Amazon S3 に保存され、各ベクトルには検索操作時の取得のために対応するレコード ID がタグ付けされます。
- メタデータの永続化: 元の構造化データは S3 に残り、Athena 経由でクエリできるため、エージェンティック検索ツールは意味的類似性と SQL ベースのフィルタリングを組み合わせることができます。
このインジェストアーキテクチャはデータを増分処理するため、BMW Group は新しい製品品質問題が報告されるたびに、データセット全体を再処理することなく、ベクトルインデックスを継続的に更新できます。
ハイブリッド検索
ハイブリッド検索ツールは、セマンティック類似性と SQL フィルタリングを組み合わせることで、ユーザーが正確なビジネス制約を適用しながら、概念的に関連するレコードを見つけることを可能にします。例えば、「前四半期の F09 車両におけるブレーキシステムのフィードバックを見つける」というクエリは、セマンティックな理解 (何が「ブレーキシステムのフィードバック」に該当するか) と構造化されたフィルタリング (特定の車両モデルと時間範囲) の両方を必要とします。
仕組み: ユーザーがクエリを送信すると、エージェントは 3 つのパラメータを使用してハイブリッド検索ツールを呼び出します。 1) 検索する概念を説明するセマンティッククエリ (例:「ブレーキシステムのフィードバック」)、 2) 取得する類似レコードの数を指定する top_k 値 (例: 100)、 3) フィルタリング用のプレースホルダー {semantic_ids} を含む SQL クエリテンプレートです。その後、ツールは複数のステップからなるプロセスを実行して、関連性の高い結果を提供します。
ステップ 1 – セマンティック検索フェーズ: ツールはまず、セマンティッククエリを Titan Text Embeddings に送信してクエリベクトルを生成します。次に、このベクトルを使用して、コサイン類似度 (cosine similarity) に基づいて最も類似した top_k 件の製品品質レコードを S3 Vectors インデックスから検索します。S3 Vectors API は、クエリとのセマンティックな関連性によってランク付けされた ID のリストを返します。
入力例: 「ブレーキシステムのフィードバック」
出力例: 類似度でランク付けされた ID: [12847, 9203, 15634, 8821, … ] (ブレーキパッドの摩耗、ブレーキフルードのチェック、ブレーキ性能などに関する上位 100 件のレコード)
ステップ 2 – SQL フィルタリングフェーズ: セマンティック ID が SQL クエリテンプレートに注入されます。その後、Athena がこの SQL クエリを実行します。このクエリには、追加の WHERE 句、JOIN、集計、またはその他の有効な SQL 操作を含めることができ、日付、重要度レベル、車両モデルなどの構造化データ属性に基づいて結果をさらに絞り込むことができます。
入力 SQL テンプレートの例:
SELECT * FROM quality_records
WHERE record_id IN ({semantic_ids})
AND vehicle_model = ‘F09’
AND report_date >= DATE ‘2025-10-01’
実行されたクエリの例:
SELECT * FROM quality_records
WHERE record_id IN (12847, 9203, 15634, 8821, …)
AND vehicle_model = ‘F09’
AND report_date >= DATE ‘2025-10-01’
出力例:
セマンティック類似性と構造化フィルタの両方に一致する 7 件のレコード
ステップ 3 – 結果の統合: フィルタリングされた結果がエージェントに返され、エージェントは Anthropic の Claude Sonnet 4.5 を使用して自然言語の応答を合成し、関連する詳細と洞察を含むユーザーフレンドリーな形式で調査結果を提示します。
ユーザーへの出力例:
「2024 年第 4 四半期の F09 車両において、ブレーキ関連の記録が 7 件見つかりました。最も多かったのは、ブレーキパッド点検 (3 件)、ブレーキフルード交換 (2 件)、ブレーキ性能チェック (2 件) です。」
このハイブリッドアプローチにより、結果がセマンティックに関連性があり (「ブレーキシステムのフィードバック」にはブレーキパッドの摩耗、ブレーキフルードのサービスなどが含まれることを理解)、かつ正確にフィルタリングされる (F09 のみ、直近の四半期のみ) ことが保証されます。このアプローチは、自然言語理解の柔軟性と構造化クエリの精度を組み合わせることで、セマンティックに関連性があり、ビジネス要件に従って正確にフィルタリングされた結果をユーザーに提供するように設計されています。次のシーケンス図は、完全なワークフローを示しています。
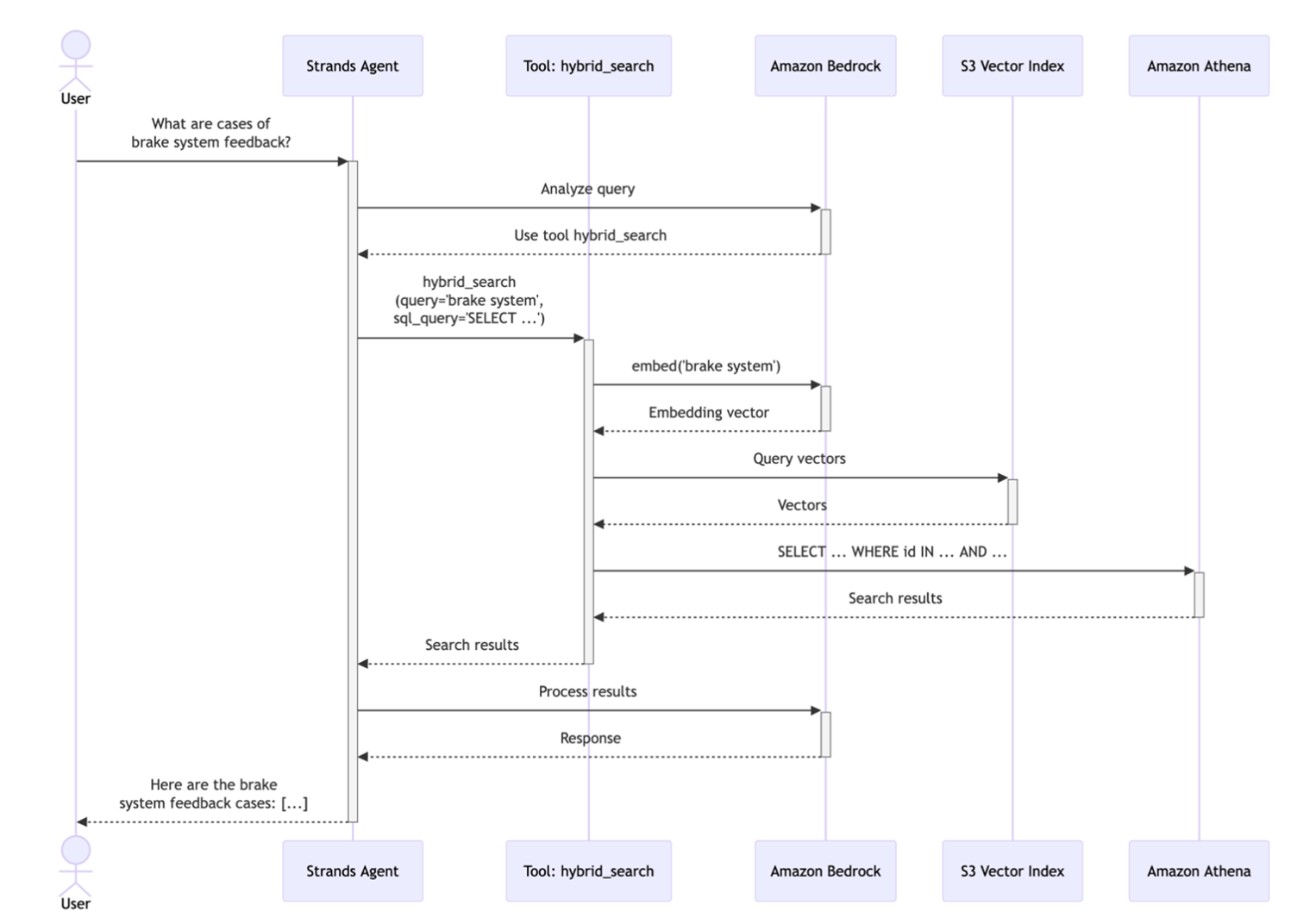
図 2. ハイブリッド検索のシーケンス図
包括的な分析のための網羅的検索
ハイブリッド検索は意味的に類似したレコードを見つけることに優れていますが、一部のクエリでは完全なカバレッジを確保するために、一致するすべてのレコードの包括的な分析が必要です。「F00 モデルでブレーキ関連の問題は何件発生しましたか?」のような質問では、用語のバリエーション (例:「ブレーキ」、「ブレーキシステム」、「ブレーキパッド」、「ABS」) によってセマンティック検索が関連するケースを見逃す可能性があるため、網羅的な評価が必要です。網羅的検索ツールは、SQL ベースの候補取得と AI による関連性分類を組み合わせることで、この課題に対処します。
網羅的検索ワークフローは、エージェントがクエリに対して類似性ベースの検索ではなく包括的なカバレッジが必要であると判断したときに開始されます。このツールは 2 つのパラメータを受け取ります。データベースから候補レコードを取得する SQL SELECT クエリと、関連性のある結果を構成するものを定義する検索問題の説明です。
候補の取得: エージェントは、用語の不一致を避けるため、セマンティックな概念ではなく構造化されたフィルタのみを使用して SQL クエリを生成します。たとえば、「ブレーキ関連の問題」のようなセマンティックな用語でフィルタリングする代わりに、クエリは正確なカラム値を使用します:
SELECT * FROM quality_records
WHERE vehicle_model = ‘F00’
これにより、LLM がデータセットから正しい用語を推測することに依存せずに、構造化された条件に一致するすべてのレコード (潜在的に数千の候補) を取得できます。このツールには再試行メカニズムが含まれています。Athena がエラー (無効なカラム名、構文エラー、またはその他の SQL エラー) を返した場合、エラーメッセージがエージェントに返され、修正されたクエリを再生成できます。これにより、ハルシネーションによる SQL が暗黙的に失敗するのを防ぎ、エージェントが実際のスキーマ情報に基づいて自己修正できるようサポートします。
バッチ処理による LLM 分類: すべての候補を一度に処理するのではなく、このツールは効率的な処理のために候補を 20 件のレコードのバッチに分割します。各バッチはマークダウンテーブルとしてフォーマットされ、Bedrock 経由で小型の LLM (Anthropic の Claude Haiku 4.5) に送信されます。モデルは各レコードを検索問題に照らして評価し、関連性があるかどうかを判断し、その判断に対する簡潔な根拠を提供します。20 という数は、モデル呼び出しの回数と コンテキストの劣化 (コンテキストウィンドウ内のトークン数が増加すると、そのコンテキストから情報を正確に想起するモデルの能力が低下する) の間の良いトレードオフであることがわかりました。バッチは並列処理され、総処理時間が大幅に短縮されます。この並列化により、分類タスクに小型で高速なモデルを使用してコスト効率を維持しながら、数千のレコードを数秒で評価できます。
結果の集約: すべてのバッチが完了した後、ツールは関連する結果を集約し、各レコードに LLM の判断根拠を含む _reason_for_match フィールドを追加して充実させます。この透明性により、ユーザーは特定のレコードが含まれた理由を理解でき、LLM を活用したフィルタリングへの信頼を構築できます。
網羅的検索アプローチは、関連するケースを見逃すとビジネス上の意思決定に影響を与える可能性がある重要なクエリに対して、完全なカバレッジを提供します。SQL の構造化されたフィルタリングと LLM のセマンティック理解を組み合わせることで、このツールはどちらのアプローチ単独では実現できない精度と再現率の両方を達成します。次のシーケンス図は、完全なワークフローを示しています。
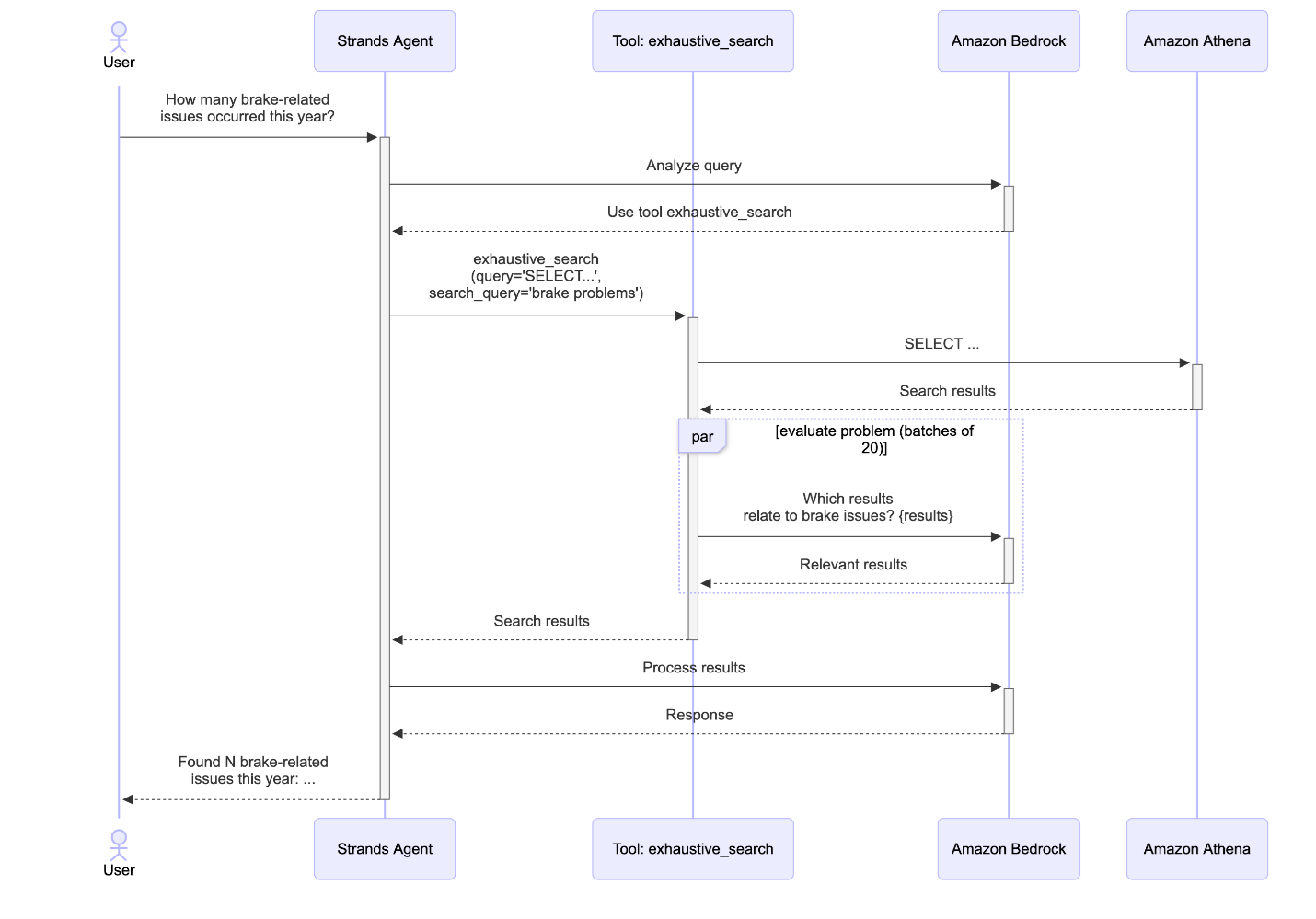
図 3. 全探索のシーケンス図
主なメリットと成果
構造化データと非構造化データへの統一的なアプローチ
ハイブリッド検索、網羅的検索、SQL クエリの組み合わせにより、このソリューションは単一の会話型インターフェース内で構造化データと非構造化データの両方をシームレスに処理できます。ユーザーは、概念的な理解を必要とする質問 (「類似のブレーキシステムのフィードバックを見つける」)、正確なフィルタリング (「前四半期のブレーキ問題の数を数える」)、または包括的な分析 (「安全関連のすべてのインシデントを評価する」) を、ツールを切り替えたりクエリを再構成したりすることなく行うことができます。エージェントのインテリジェントなツール選択により、各クエリタイプが最も適切な方法で処理され、一貫した自然言語のユーザーエクスペリエンスを維持しながら正確な結果を提供します。
コスト効率の高いサーバーレスアーキテクチャ
サーバーレス AWS サービスで完全に構築されているため、ソリューションコンポーネントは使用していないときはゼロにスケールし、コンピューティングリソースはオンデマンドで割り当てられ、実際の使用量に対してのみ料金が発生します。サーバーレスアーキテクチャにより、従来のインフラストラクチャの運用オーバーヘッドや固定コストなしに、AI を活用した高度なデータ分析プラットフォームを開発できます。
まとめ
このエージェンティック検索ソリューションは、AWS の生成 AI サービスがユーザーとデータのインタラクション方法をどのように変革できるかを実証しています。ユーザーとインサイトの間の従来の障壁を軽減することで、このアプローチにより、エンタープライズアプリケーションに必要な精度とスケールを維持しながら、すべてのユーザーがデータインサイトを生成できるようになります。組織が生成するデータ量が増加し続ける中、このようなソリューションは、エンタープライズデータ資産の価値を最大限に引き出すために不可欠なものとなっています。 AWS で AI を活用したデータソリューションの構築について詳しく知りたい方は、生成 AI リソースをご覧ください。