Amazon Web Services ブログ
Amazon SageMaker, Amazon Neptune, Deep Graph Library を使って作る GNNベースのリアルタイムオンライン不正検知ソリューション
この記事は、こちらの AWS blog を翻訳したものです。
不正行為は、eコマース、ソーシャルメディア、金融サービスなど、多くの業界に深刻な影響を与えています。詐欺行為は、企業や消費者に大きな損失を与える可能性があります。アメリカの消費者は、2021年に詐欺行為によって58億ドル以上の損失を被ったと報告しており、2020年比で70%以上増加しています。不正行為者の検知には、ルールベースのフィルタ、異常検知、機械学習(ML)モデルなど、多くの技術が用いられてきました。
実世界のデータにおいて、ある要素が他の要素と強く関係することがよくあります。グラフ構造は、異常検知に有用な情報を提供することができます。たとえば次の図では、ユーザは Wi-Fi ID、物理的な場所、電話番号などの共有エンティティを介して関連づけられています。電話番号のようなユニークな値が多いエンティティは、たとえば one-hot エンコーディングしても意味がないため、従来の特徴量ベースのモデルでは利用が難しいとされています。しかし、不正検知においてはこのような関係は、ユーザが不正行為者であるかどうかの予測に役立つ可能性があります。あるユーザが既知の不正行為者と複数のエンティティを共有している場合、そのユーザは不正行為者である可能性が高くなります。
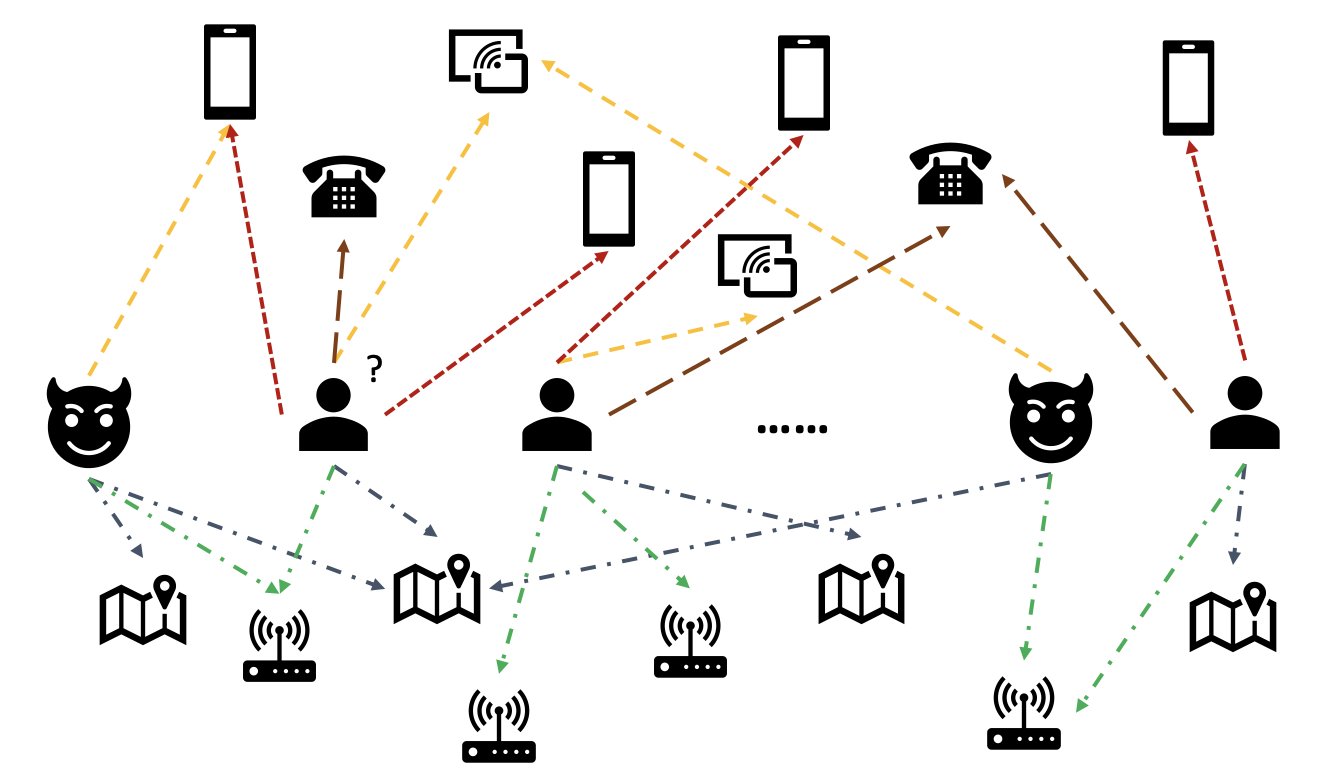
近年、グラフニューラルネットワーク(GNN) が不正検知のための手法として注目されています。GNN モデルは、グラフ構造とノードやエッジの属性(ユーザや取引の情報など)の両方を組み合わせて、悪意のあるユーザやイベントを正当なものと区別するための意味のある表現を学習することができます。この機能は、不正行為者が結託して不正を示すような特徴を隠しても、残った不正の痕跡から詐欺を検出するために極めて重要です。
現在の主な GNN ソリューションはオフラインのバッチ学習と推論モードに依存しているため、悪意のあるイベントが起こり、損失が発生した後で不正行為者を発見します。しかし、損失を防ぐためには、不正なユーザや活動をリアルタイムで検知することが重要です。特に、不正行為を防ぐチャンスが一度しかないようなビジネスケースにおける重要性は顕著です。たとえば、いくつかの e コマースプラットフォームでは、アカウント登録は誰でも行うことができるため、不正行為者は一度不正な行為を行ったアカウントを再度利用することはありません。
不正行為者をリアルタイムで予測することは重要です。しかし、そのようなソリューションの構築は困難です。GNN はまだまだ新しい技術のため、GNN モデルをバッチ処理からリアルタイム処理に変換するためのオンラインリソースは限られています。さらに、受信したイベントを GNN のリアルタイム配信 API に供給できるストリーミングデータパイプラインを構築することも困難です。著者の知る限り、この原稿を書いている時点では、GNN ベースのリアルタイム推論ソリューションのリファレンスアーキテクチャやサンプルはありません。
開発者が GNN をリアルタイム不正検出に適用できるように、この記事では、Amazon Neptune、 Amazon SageMaker、Deep Graph Library (DGL) などの AWS サービスを使って、GNN モデルを使ったリアルタイム不正検出のエンドツーエンドソリューションを構築する方法を紹介します。
ここでは、以下の 4つのタスクに焦点を当てています。
- 表形式の取引データセットを異種グラフデータセットに加工
- SageMaker を用いた GNN モデルの学習
- 学習した GNN モデルを SageMaker のエンドポイントにデプロイ
- 受信した取引データに対するリアルタイム推論
この記事は、最初の2つのタスクに焦点を当てた AWS ブログの「Amazon SageMaker と Deep Graph Library を使用して異種ネットワークの不正を検出する」における作業を拡張したものです。異種グラフ、GNN、および GNN の半教師あり学習の詳細については、そちらの記事を参照してください。
不正検知のためのフルマネージドな AWS AI サービスをお探しの企業は、偽アカウントの作成やオンライン決済詐欺など、潜在的に不正なオンライン活動を簡単に特定できる Amazon Fraud Detector も利用できます。
ソリューションの概要
このソリューションには 2つの主要なパートがあります。
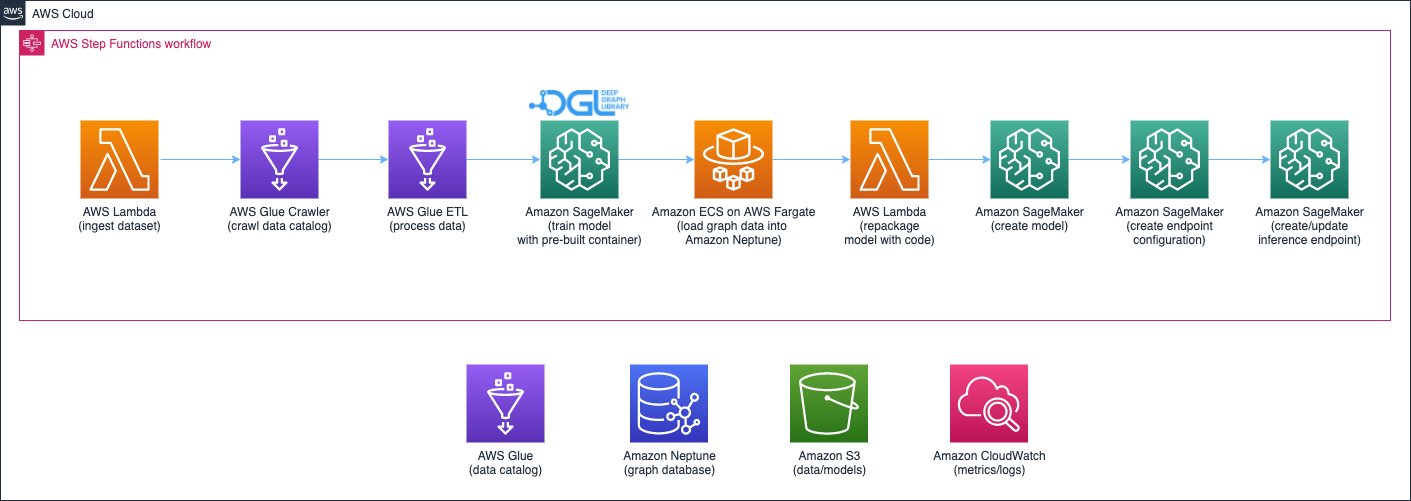
1つめは、データを処理し、GNN モデルを学習し、学習したモデルをデプロイするパイプラインです。これは、AWS Glue を使用して取引データを処理し、処理したデータを Amazon Neptune と Amazon Simple Storage Service (Amazon S3)の両方に保存しています。そして、SageMaker の学習ジョブを起動し、Amazon S3 に保存されたデータに対して GNN モデルを学習させ、取引が不正かどうかを予測します。学習したモデルは、他の生成物とともに、学習ジョブの完了時に Amazon S3 にアップロードされます。最後に、保存されたモデルは SageMaker のエンドポイントとしてデプロイされます。パイプラインは、次の図のように AWS Step Functions によってオーケストレーションされます。
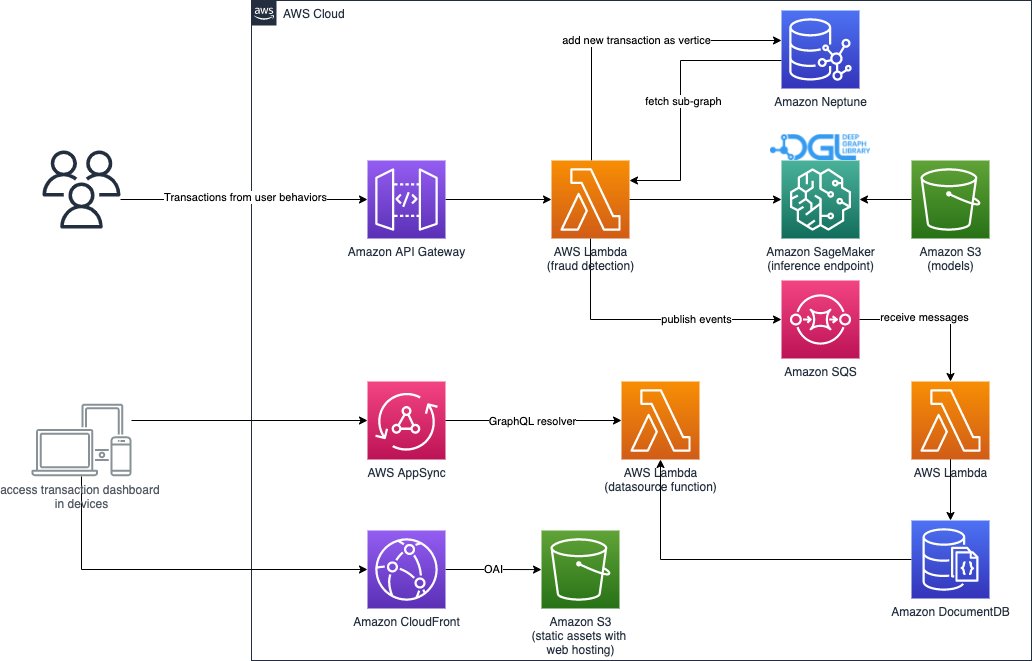
2つめは、リアルタイムの不正取引検知の部分です。これは RESTful API から始まり、Neptune のグラフデータベースにクエリし、受信した取引に関連するサブグラフを抽出します。また、ビジネス活動をシミュレートできる Web ポータルを備えており、不正な取引と正当な取引の両方を含むオンライン取引を生成することができます。Web ポータルでは、不正検出の様子をリアルタイムで可視化することができます。この部分では、Amazon CloudFront、AWS Amplify、AWS AppSync、Amazon API Gateway、Step Functions、Amazon DocumentDB を使用して、Web アプリケーションを迅速に構築しています。次の図は、リアルタイムの推論プロセスと Web ポータルを示しています。
このソリューションの実装と、AWS アカウントでアーキテクチャを起動できるAWS CloudFormation テンプレートは、以下の GitHubリポジトリで公開されています。
データ処理
このセクションでは、サンプルデータセットを処理し、表形式の生データを、異なる列の間に検出された関係を示す関係を持つグラフに変換する方法を簡単に説明します。
このソリューションでは、前回の記事「Amazon SageMaker と Deep Graph Library を使用して異種ネットワークの不正を検出する」と同じデータセット「IEEE-CIS fraud dataset」を使用しています。したがって、データ処理の基本原理は同じです。簡単に説明すると、不正データセットには取引テーブルとアイデンティティテーブルがあり、コンテキスト情報(例えば、取引で使用されたデバイスなど)と共に約50万件の匿名化された取引情報が記録されています。いくつかの取引データは、取引が不正であるかどうかを示す二値のラベル情報を含んでいます。我々の課題は、ラベルが含まれていない取引のうち、どれが不正で、どれが正当であるかを予測することです。
次の図は、IEEE のテーブルを異種グラフに変換する方法の一般的なプロセスを示しています。まず、各テーブルから2つの列を抽出します。1 つは常に TransactionID 列で、一意の TransactionID を 1 つのノードとして設定します。もう 1つは、ProductCD 列や id_03 列のようなカテゴリー列から選び、ここではそれぞれのカテゴリーを個別のノードとして設定しました。同じ行に TransactionID とユニークなカテゴリが現れたら、それらを1つのエッジで接続します。このようにして、表の中の2つのカラムを1つの 2部グラフに変換します。次に、これらの 2部グラフを TransactionID のノードと一緒に結合し、同じTransactionID のノードは 1つのノードにマージされます。このステップを経て、2部グラフの異種グラフが作成されます。
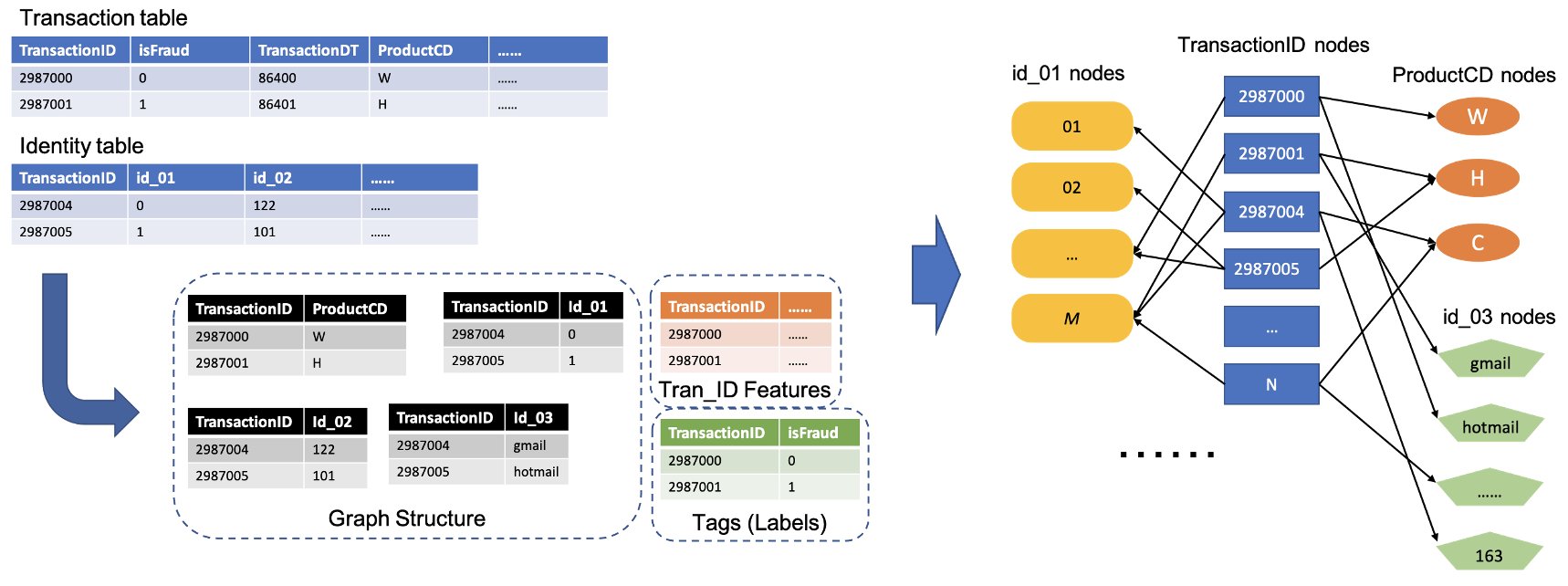
グラフの構築に使用されない残りの列については、TransactionID ノードの特徴量として結合します。isFraud の値を持つTransactionID の値は、モデル学習のためのラベルとして使用されます。この異種グラフを使って TransactionID ノードのノード分類タスクを行います。GNN を学習するためのグラフデータの準備の詳細については、前回の記事の「特徴抽出」と「グラフの作成」のセクションを参照してください。
このソリューションで使用されたコードは、src/scripts/glue-etl.py にあります。また、Jupyterノートブック src/sagemaker/01.FD_SL_Process_IEEE-CIS_Dataset.ipynbを使ってデータ処理の実験ができます。
前回の記事のように手動でデータを処理するのではなく、このソリューションでは Step Functions と AWS Glue によってオーケストレーションされた完全自動のパイプラインを使用し、Apache Spark を介して巨大なデータセットを並列処理します。Step Functions のワークフローは、AWS Cloud Development Kit (AWS CDK) で書かれています。以下は、このワークフローを作成するためのコードスニペットです。
このワークフローでは、GNN モデル学習のためのグラフデータ構築の他に、後ほどリアルタイム推論を行うためにグラフデータを Neptune にバッチロードしています。このバッチロードプロセスは、以下のコードスニペットに示されています。
GNN モデルの学習
モデル学習用のグラフデータを Amazon S3 に保存した後、学習ジョブの実行時のみ課金される SageMaker 学習ジョブをトリガーに、BYOC(Bring Your Own Container)モードで GNN モデル学習処理を開始します。これは、モデル学習スクリプトと関連ライブラリを Docker イメージにパックし、それを使用して SageMaker 学習インスタンスを作成することができます。BYOC 方式は、学習環境のセットアップの手間を大幅に削減できる可能性があります。
src/sagemaker/02.FD_SL_Build_Training_Container_Test_Local.ipynbに、GNN モデルの学習に関する詳細が記載されています。
Dockerイメージ
Jupyterノートブックファイルの最初の部分は、学習用 Docker イメージの生成です(以下のコードスニペットを参照)。
モデルの学習には、PyTorch ベースのイメージを使用しました。Docker イメージ構築時に Deep Graph Library (DGL) などの関連ライブラリをインストールします。src/sagemaker/FD_SL_DGL/gnn_fraud_detection_dgl にある GNN モデルコードもイメージにコピーします。
取引データを異種グラフに変換するため、本ソリューションでは、異種グラフに特化して設計された Relational Graph Convolutional Network (RGCN) モデルを選択しました。RGCN モデルは異種グラフのノードに対して学習可能な埋め込みを学習することができます。そして、学習された埋め込みは、ノードラベルを予測するための全結合層の入力として使用されます。
ハイパーパラメータ
GNN を学習するためには、学習処理の前にいくつかのハイパーパラメータを定義する必要があります。たとえば、構築されるグラフのファイル名、GNN モデルの層数、学習エポック、オプティマイザ、最適化パラメータなどです。設定のサブセットについては、以下のコードを参照してください。
全てのハイパーパラメータとそのデフォルト値についての詳細は、src/sagemaker/FD_SL_DGL/gnn_fraud_detection_dgl フォルダ内の estimator_fns.py を参照してください。
SageMaker によるモデル学習
カスタム Docker イメージを構築したら、前処理されたデータを使って、定義したハイパーパラメータで GNN モデルを学習します。学習ジョブは、バックエンドの深層学習フレームワークとして PyTorch を使用した DGL で GNNを構築し、学習します。SageMaker では、SageMaker estimator の入力引数にカスタムDockerイメージを使って、簡単にGNN モデルを学習することができます。SageMaker 上の DGL を使った GNN の学習については、こちらのドキュメントを参照してください。
SageMaker Python SDK は Estimator を使用して SageMaker 上での学習をカプセル化し、SageMaker 互換のカスタムDockerコンテナを実行し、SageMaker Python SDK を使用することで独自の ML アルゴリズムを実行できるようにします。以下のコードスニペットは、SageMaker(ローカル環境またはクラウドインスタンス)を使用してモデルを学習する様子を示しています。
学習が完了すると、テストセットにおける GNN モデルの性能は以下のように表示されます。問題なければ RGCN モデルは、約0.87 のAUC と 95%以上の精度を得ることができます。RGCN モデルと他の ML モデルとの比較については、前回のブログ記事の結果セクションを参照してください。
モデルの学習が完了すると、SageMaker は学習済みのモデルを学習済みのノード埋め込みなどの生成物とともに ZIP ファイルに圧縮し、指定の S3 パスにアップロードします。次に、学習したモデルをリアルタイムに不正検知するためのデプロイについて説明します。
GNN モデルのデプロイ
SageMaker を使うと、学習した ML モデルのデプロイを簡単に行うことができます。ここでは、SageMaker の PyTorchModel クラスを使用して学習済みモデルをデプロイします。これは、DGL モデルがバックエンドフレームワークとして PyTorch を使用しているためです。デプロイコードは src/sagemaker/03.FD_SL_Endpoint_Deployment.ipynb に記載されています。
SageMaker では、学習済みモデルファイルやアセットの他に、カスタマイズしたモデルをデプロイするためのエントリーポイントファイルが必要です。エントリーポイントファイルは、推論エンドポイントインスタンスのメモリ内で実行・保存され、推論リクエストに応答します。今回の場合、エントリーポイントファイルは src/sagemaker/FD_SL_DGL/code フォルダにある fd_sl_deployment_entry_point.py ファイルで、大きく4つの機能を実行します。
- リクエストを受け取り、リクエストの内容を解析し、予測されるノードとその関連データを取得
- RGCN モデルの入力として、データを DGL 異種グラフに変換
- 学習された RGCN モデルによるリアルタイム推論
- 予測結果を依頼者に送信
SageMaker の仕様に従って、最初の2つの機能は input_fn メソッドで実装されています。以下のコードをご覧ください(簡単のため、解説コードを一部削除しています)。
構築された DGL グラフと特徴量は predict_fn に渡されます。predict_fn は input_fn の出力と学習済みモデルの 2 つの入力引数を取ります。以下のコードをご覧ください。
perdict_fn で使用されるモデルは、エンドポイントが初めて呼び出されたときに model_fn メソッドで作成されます。model_fn は、引数 model_dir の値を使って SageMaker のモデルフォルダから保存されたモデルファイルと関連するアセットを読み込みます。以下のコードをご覧ください。
predict_fn メソッドの出力は、クラス 0 とクラス 1 のロジットを示す 2 つの数値のリストで、0 は正当、1 は不正を意味します。SageMakerはこのリストを受け取り、output_fnというインナーメソッドに渡して最終的な関数を完成させます。
GNN モデルをデプロイするには、まず GNN モデルを SageMaker の PyTorchModel クラスにラップし、エントリポイントファイルとその他のパラメータ(保存した ZIP ファイルのパス、PyTorch フレームワークのバージョン、Python のバージョン、など)を設定します。次に、インスタンス設定を使用して deploy メソッドを呼び出します。以下のコードをご覧ください。
前述の手順とコードスニペットは、Jupyter ノートブックからオンライン推論エンドポイントとして GNN モデルをデプロイする方法を示しています。しかし本番環境では、データの処理、モデルの学習、推論エンドポイントのデプロイを含むワークフロー全体について、Step Functions によってオーケストレーションされた前述の MLOps パイプラインを使用することをおすすめします。パイプライン全体は AWS CDK アプリケーションによって実装されており、異なるリージョンやアカウントで簡単に複製することができます。
リアルタイム推論
新しい取引データが到着したとき、リアルタイム予測を行うために、4つのステップを完了する必要があります。
- ノードとエッジの挿入 – TransactionID や ProductCD などの取引情報をノードとエッジとして抽出し、Neptune データベースに格納されている既存のグラフデータに新しいノードを挿入
- サブグラフ抽出 – 予測される取引ノードを中心ノードとし、GNN モデルの入力要件に従って n-hop サブグラフを抽出
- 特徴抽出 – サブグラフのノードとエッジに対して、関連する特徴を抽出
- 推論エンドポイントの呼び出し – サブグラフと特徴量をリクエストの内容にパックし、リクエストを推論エンドポイントに送信
本ソリューションでは、前ステップで説明したリアルタイム不正予測機能を実現するために、RESTful API を実装しています。リアルタイム予測については、以下の疑似コードを参照してください。完全な実装はこちらにあります。
リアルタイムで予測するためには、最初の 3つのステップでより低いレイテンシが要求されます。したがって、グラフデータベースはこれらのタスクに最適な選択であり、特にサブグラフ抽出はグラフデータベースクエリで効率的に達成できる可能性があります。擬似コードで使用している関数は、Neptune の gremlin クエリに基づいています。
GNN を用いたリアルタイム不正検知に関する注意点として、GNN の推論モードがあります。リアルタイム推論を実現するためには、GNN モデルの推論をトランスダクティブモードからインダクティブモードに変換する必要があります。トランスダクティブ推論モードの GNN モデルは、新しく現れたノードやエッジに対して予測を行うことができませんが、インダクティブモードでは、GNN モデルは新しいノードやエッジを扱うことができます。トランスダクティブモードとインダクティブモードの違いのデモを次の図に示します。
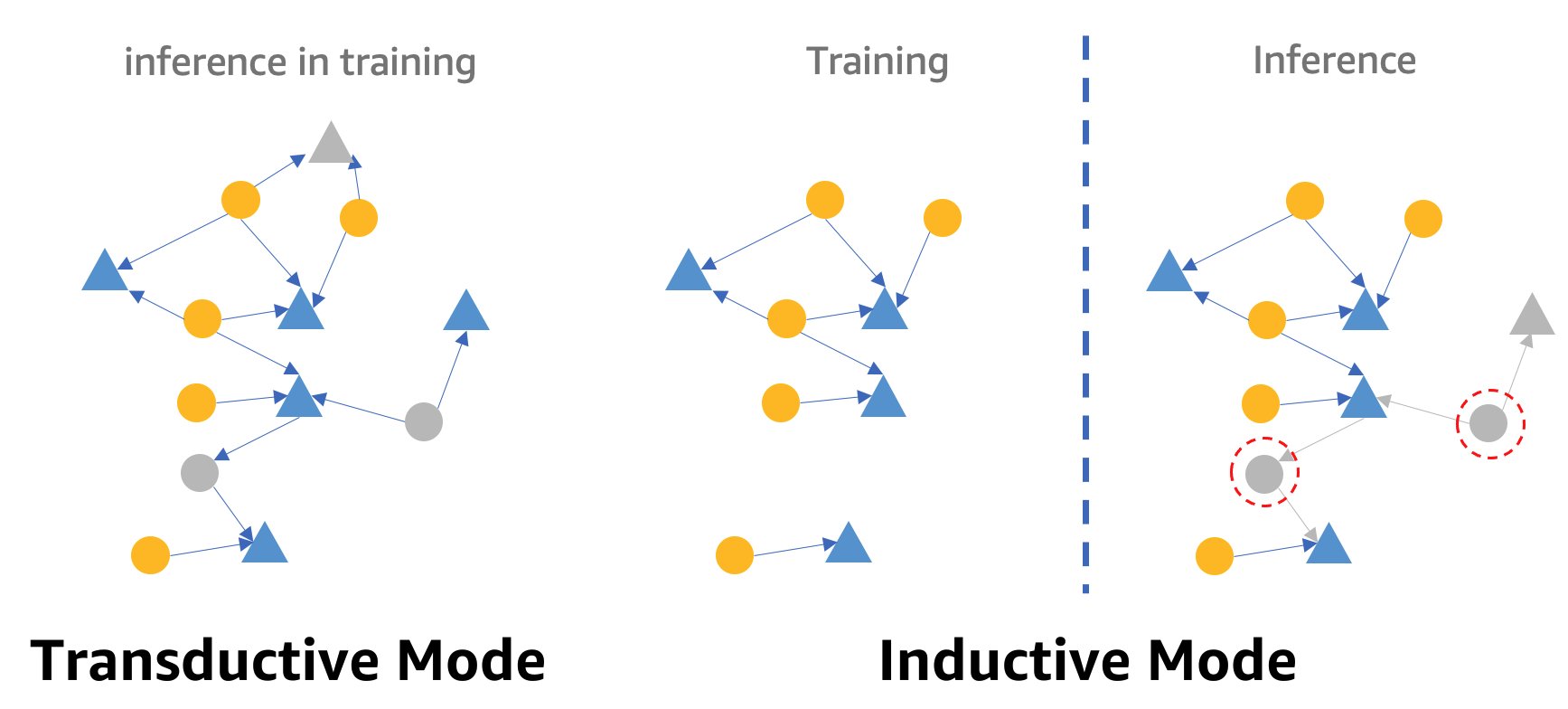
トランスダクティブモードの学習では、予測対象となる(ラベル付けされていない)ノードおよびエッジと、ラベル付けされているノードおよびエッジが混在しています。モデルは推論を行う前に予測対象のノードとエッジを識別し、学習の間に推論されるでしょう。インダクティブモードでは、モデルは学習グラフで学習しますが、未知のノード(右の赤い点線丸のノード)をその隣接ノード(右の灰色の三角形のノード。同様に未知かもしれない)を使って予測する必要があります。
我々の RGCN モデルはトランスダクティブモードで学習・テストされます。学習時にはすべてのノードにアクセスでき、IP アドレスやカードの種類など、特徴のないノードについても埋め込みを学習します。テスト段階では、RGCN モデルはこれらの埋め込みをノードの特徴として使い、テストセット内のノードを予測します。しかし、リアルタイム推論を行う際に新たに追加された、特徴を持たないノードの中には、学習グラフに存在しなかったため埋め込みを持たないものもあります。この問題を解決する一つの方法として、同じノードタイプに含まれる全ての埋め込み値の平均値を新しいノードに割り当てるという方法があります。本ソリューションでは、この方法を採用しています。
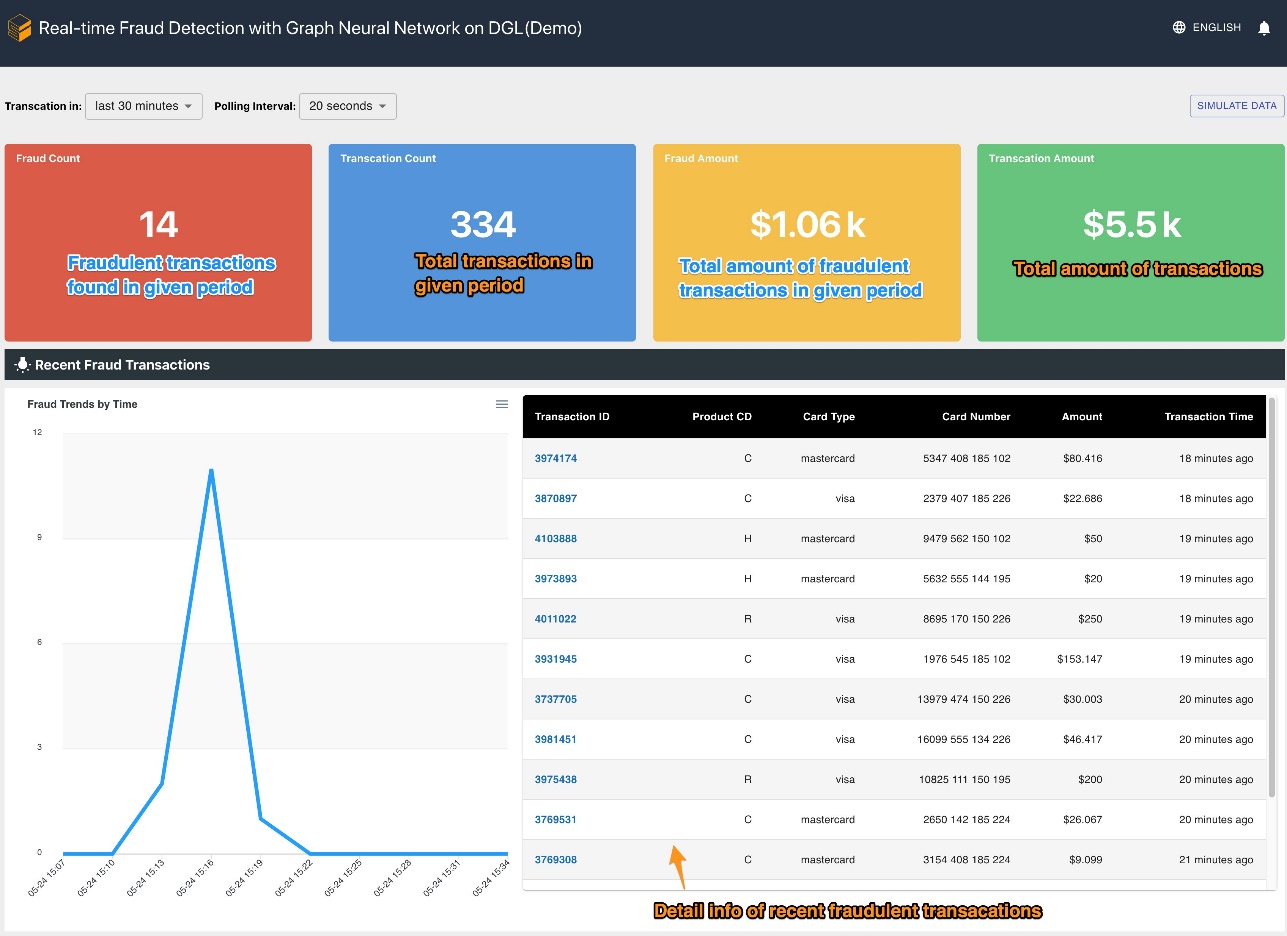
また、本ソリューションは、事業者の視点からリアルタイムの不正予測を行うための Web ポータル(以下のスクリーンショット参照)を提供しています。シミュレーションされたオンライン取引を生成し、検出された不正取引情報をリアルタイムで可視化することができます。
リソースの削除
ソリューションを試し終わったら、課金を避けるためにリソースを削除してください。
まとめ
この記事では、SageMaker、Neptune、および DGL を使用して、GNN ベースのリアルタイム不正検出ソリューションを構築する方法を紹介しました。このソリューションには、3つの大きな利点があります。
- 予測精度と AUC メトリクスの面で優れた性能を発揮
- ストリーミング MLOps パイプラインと SageMaker エンドポイントを使ってリアルタイム推論を実現
- 提供される CloudFormation テンプレートで全体のデプロイプロセスを自動化し、関心のある開発者が自分のアカウント内のカスタムデータでこのソリューションを簡単にテスト可能
このソリューションの詳細については、GitHub リポジトリを参照してください。
このソリューションをデプロイした後は、GNN モデルを変更しないまま、独自のデータ形式に合わせてデータ処理コードをカスタマイズし、リアルタイム推論機構を変更することをおすすめします。本ソリューションでは、レイテンシーの最適化対応をせずにリアルタイム推論を 4つのステップに分割しました。これらの 4つのステップでデモデータセットで予測結果を得るには数秒かかります。Neptune グラフデータのスキーマ設計とサブグラフや特徴抽出のクエリーを最適化することで、推論レイテンシを大幅に削減できると考えています。
本記事の翻訳は機械学習ソリューションアーキテクトの大渕が担当しました。
著者について
 Jian Zhang は応用科学者であり、機械学習を使用して、不正検出、装飾画像の生成など、さまざまな問題を顧客が解決するのを支援しています。彼はグラフベースの機械学習、特にグラフ ニューラル ネットワークを使った、中国、米国、シンガポールの顧客向けソリューションの開発に成功しています。 AWS のグラフ機能の啓蒙者として、Zhang は GNN、Deep Graph Library (DGL)、Amazon Neptune、およびその他の AWS サービスに関する多くの公開プレゼンテーションを行っています。
Jian Zhang は応用科学者であり、機械学習を使用して、不正検出、装飾画像の生成など、さまざまな問題を顧客が解決するのを支援しています。彼はグラフベースの機械学習、特にグラフ ニューラル ネットワークを使った、中国、米国、シンガポールの顧客向けソリューションの開発に成功しています。 AWS のグラフ機能の啓蒙者として、Zhang は GNN、Deep Graph Library (DGL)、Amazon Neptune、およびその他の AWS サービスに関する多くの公開プレゼンテーションを行っています。
 Mengxin Zhu は、AWS のソリューション アーキテクトのマネージャーであり、再利用可能な AWS ソリューションの設計と開発に重点を置いています。彼は長年ソフトウェア開発に携わっており、さまざまな規模のいくつかのスタートアップ チームを担当してきました。彼はまた、オープンソース ソフトウェアのサポーターであり、Eclipse コミッターでした。
Mengxin Zhu は、AWS のソリューション アーキテクトのマネージャーであり、再利用可能な AWS ソリューションの設計と開発に重点を置いています。彼は長年ソフトウェア開発に携わっており、さまざまな規模のいくつかのスタートアップ チームを担当してきました。彼はまた、オープンソース ソフトウェアのサポーターであり、Eclipse コミッターでした。
 Haozhu Wang は、Amazon ML Solutions Lab のリサーチサイエンティストであり、強化学習の分野を共同でリードしています。彼は、グラフ学習、自然言語処理、強化学習、および AutoML に関する最新の研究を使用して、顧客が高度な機械学習ソリューションを構築するのを支援しています。 また、ミシガン大学で電気およびコンピューター エンジニアリングの博士号を取得しました。
Haozhu Wang は、Amazon ML Solutions Lab のリサーチサイエンティストであり、強化学習の分野を共同でリードしています。彼は、グラフ学習、自然言語処理、強化学習、および AutoML に関する最新の研究を使用して、顧客が高度な機械学習ソリューションを構築するのを支援しています。 また、ミシガン大学で電気およびコンピューター エンジニアリングの博士号を取得しました。