Amazon Web Services ブログ
電通総研、大規模 GPU 環境を約 1 ヶ月で構築 〜リアルタイム 3DCG ソリューション「UNVEIL」の戦略的アプローチ 〜
本ブログは株式会社電通総研とAmazon Web Services Japan が共同で執筆いたしました。
電通総研様が開発されたリアルタイム 3DCG ソリューション「UNVEIL」において、「1,000 名の同時接続」と「100〜500ms の低レイテンシー」という厳しい要件を、わずか約 1 ヶ月の準備期間で大規模 GPU 環境を構築し、乗り越えた事例をご紹介します。
まず、「UNVEIL」 についてご紹介します。「UNVEIL」とは電通総研様が開発されているブラウザでのリアルタイム 3DCG メタバース/仮想空間のソリューションで、現実に近い高品質な 3D 体験を、多人数同時参加で提供する商用向けサービスです。


(出展: 株式会社電通総研)
お客様の状況と課題
電通総研様は、「UNVEIL」の商用展開に向けた取り組みの一環として、2025 年 12 月に実施された社内イベントでの活用を計画されていました。同イベントでは、1,000 名の同時接続と、レスポンス 100〜500 ms 程度という要件がありました。
課題は、大規模な GPU 環境(Amazon EC2 の g4dn 系、g5 系インスタンス)を効率的に構築することでした。イベント駆動型のワークロードであるため、コスト効率を保ちながら、必要な規模の環境を短期間で立ち上げる必要がありました。
戦略1: コスト最適化のためのリージョン選択
当初はアジアパシフィック (東京) リージョンで基盤を構築されていましたが、大規模な GPU 環境を構築するにあたり、コスト効率の観点から、海外リージョンの活用を検討しました。
Amazon EC2 の料金はリージョンによって異なるため、コスト効率の良い米国東部 (バージニア北部) リージョンと米国西部 (オレゴン)リージョンが候補として浮上しました。また、リージョンに依存しないアプリケーション設計を採用されていた点も、海外リージョンを選択できた大きな理由でした。
| リージョン | g5.xlarge のオンデマンド料金 ($/Hour) ※ |
| アジアパシフィック (東京) | 1.459 |
| 米国東部 (バージニア北部) | 1.006 |
| 米国西部 (オレゴン) | 1.006 |
※ 2026 年 3 月時点の料金
戦略2: レイテンシーを考慮した実測テスト
海外リージョンを活用する際の最大の懸念は、日本からのアクセスにおけるレイテンシーでした。電通総研様は、机上の計算だけでなく、実際のアプリケーションで測定するというアプローチを採用されました。
まず 米国東部 (バージニア北部) で検証を実施しましたが、日本からのアクセスでは遅延が大きく、ユーザー体験に影響があることが判明しました。次に米国西部 (オレゴン) で検証した結果、米国東部 (バージニア北部) よりもレスポンスが改善され、目標のレイテンシー数値に抑え、視聴体験を損なわない範囲に収まることを確認できました。この結果からコスト効率とレイテンシーの両面で最適な米国西部 (オレゴン) リージョンを採用することが決定しました。
テストに向けた環境構築において、AWS の各リージョンで同一のサービスや API が提供されていたため、環境を別のリージョンへ再現することが容易でした。加えて、Amazon EKS をはじめとするマネージドサービスを活用していたことで、リージョン間の環境移行も約 1 週間で完了し、迅速な検証が可能になりました。
戦略3: 複数回の事前テストによるリスク軽減
イベント本番での失敗を避けるため、複数回のテストを実施しました。数百台規模での動作確認を実施することで、以下のような潜在的な問題を事前に発見・対処することができました:
- 数百台規模のオートスケーリング起動が問題ないことの確認 (スケール起動検証)
- Service Quota の事前確認と調整
- Amazon VPC の IP アドレス設計などインフラ面での考慮事項の確認
- リージョンごとのレイテンシー特性の把握
また、大規模な GPU 環境を構築する際のキャパシティ確保の観点から、g4dn 系と g5 系の複数世代の GPU インスタンスタイプを混在させる構成を採用しました。単一のインスタンスタイプに依存せず、複数のインスタンスタイプを組み合わせることで、特定のインスタンスタイプで必要な台数が確保できない場合でも、他のインスタンスタイプで補完できる柔軟な環境を実現しました。
ソリューション概要
UNVEIL は、Amazon EKS を中心としたアーキテクチャで構成されています:
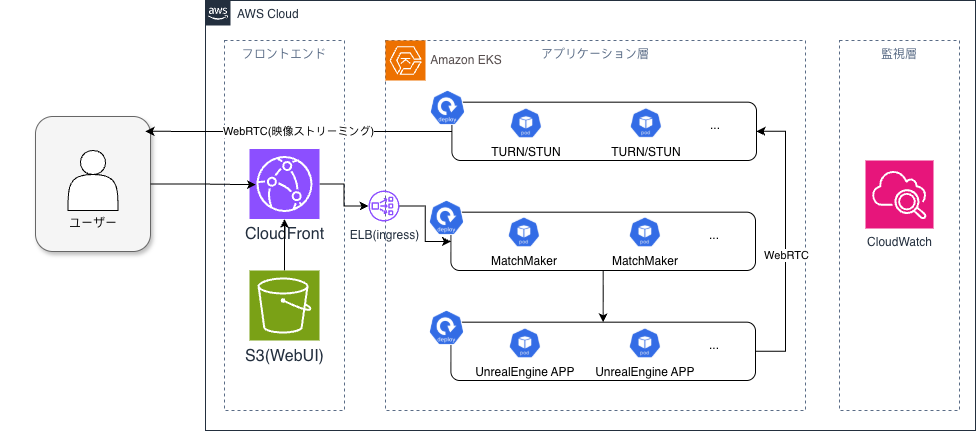
- フロントエンド: Amazon CloudFront + Amazon S3 による高速コンテンツ配信
- アプリケーション層: Amazon EKS 上で動作する MatchMaker(ユーザーと GPU サーバーを割り当てる仕組み)、GPU サーバー、TURN/STUN サーバー
- 監視層: Amazon CloudWatch による包括的な監視
ユーザーは Amazon CloudFront 経由でアクセスし、MatchMaker が利用可能な GPU サーバーに割り当て、Unreal Engine でレンダリングされた映像を WebRTC 経由で配信します。
導入効果
2025 年 12 月のイベントでは以下の成果を得ることができました:
- 最大 1,000 台規模 GPU インスタンスを稼働
- 既存の東京リージョンと比較してコスト効率の良い環境構築を実現
電通総研様からは、「1,000 人規模のスパイクアクセスに対しても、インフラをオートスケーラブルに増減できることを検証できた点が大きな成果でした。未使用時にコスト増となり得る GPU リソースを、利用人数に応じて自動的にスケールできることを確認し、品質とコストの両立の可能性を示せました。また、事前検証によりボトルネックを特定できたことも、商用化に向けた重要な学びとなりました。一方で、アプリケーション面では大規模・多人数同時利用時の考慮が十分でなく、一部挙動が不安定となる課題も確認でき、改善項目として整理できました」とのコメントをいただきました。
大規模 GPU 環境構築の学び
今回のプロジェクトから得られた重要な学びをまとめます:
1. コスト最適化のためのリージョン戦略
海外リージョンの活用により、コスト効率の良い大規模 GPU 環境を構築できます。
2. 実測ベースの意思決定
複数リージョンで実際にレイテンシーを測定し、机上の計算だけでなく実際のアプリケーションでの検証が重要です。
3. 複数回の事前テストの重要性
複数回のテストを実施し、各テストでボトルネックを特定することで、イベント本番のリスクを最小化できます。また、g4dn 系と g5 系など複数世代の GPU インスタンスタイプを混在させることで、大規模環境でのキャパシティ確保の柔軟性を高めることができます。
4. イベント当日の運用設計
イベント開始前に十分な台数を確保し、Amazon CloudWatch による包括的な監視で問題の早期発見を実現します。
まとめ
今回は、電通総研様の UNVEIL において、大規模 GPU 環境を効率的に構築するための戦略的アプローチをご紹介しました。
電通総研様の「まず試してみる」という実践的なアプローチと、事前テストで計測したデータに基づく意思決定が、短期間でのシステム構築を可能にしました。大規模な GPU 環境を構築される際は、ぜひ今回ご紹介した戦略を参考にしていただければ幸いです。
AWS では定期的に技術イベントを開催しております。ぜひご参加ください。
https://aws.amazon.com/jp/events/
執筆者
株式会社電通総研 事業開発室 姫野 智也氏、孫 辰氏
Amazon Web Services Japan: ソリューションアーキテクト 本多 和幸