Amazon Web Services ブログ
Amazon Macie を用いた Amazon RDS データベースのデータ分類方法
このブログは “Enabling data classification for Amazon RDS database with Macie” を翻訳したものです。
Amazon Macie を用いて Amazon Relational Database Service (Amazon RDS) インスタンスの機密データ検出方法について、お客様からご質問をいただいています。このブログでは、AWS Database Migration Service (AWS DMS) を使って Amazon RDS からデータを抽出し、Amazon Simple Storage Service (Amazon S3) に保存し、Macie を使ってデータを分類する方法について紹介します。Macie で得られた検出結果は、適切なチームから Amazon Athena で照会できるようにもなります。
課題
Macie を使用して RDS でホストされているデータベースから機密データを見つける必要があるとします。Macie は現在、データソースとして S3 のみをサポートしています。したがって、RDS からデータを抽出して S3 に保存する必要があります。さらに、監査チームがこれらの発見を監査するためのインターフェイスが必要になります。
ソリューションの概要
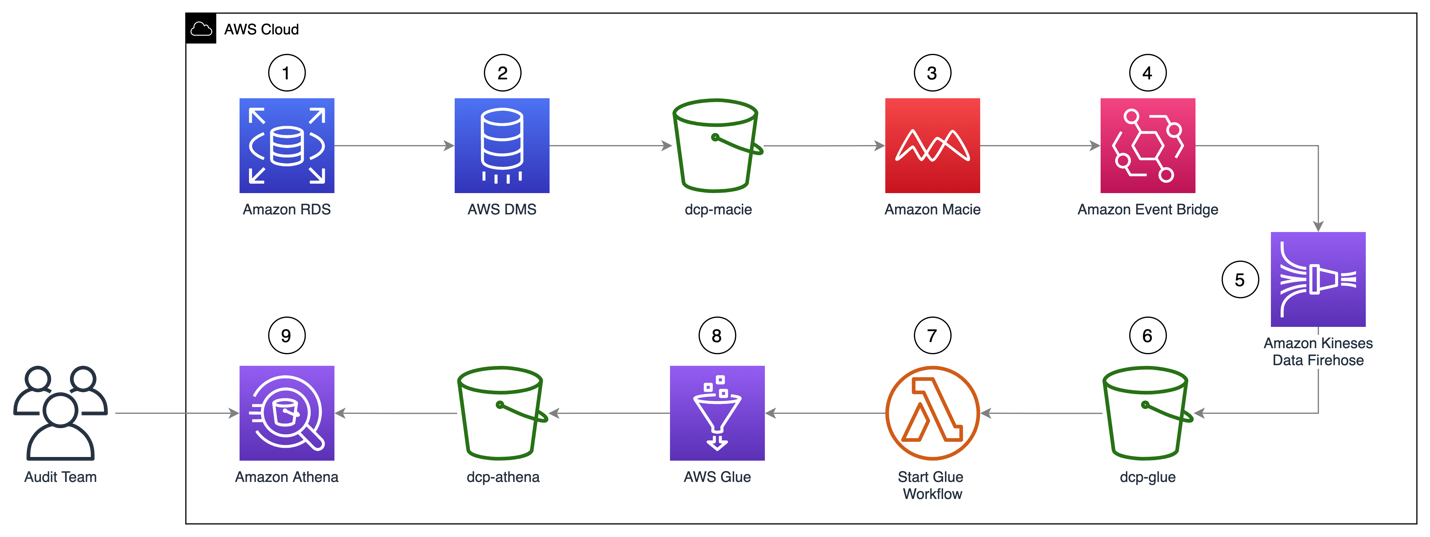
図1: ソリューションのアーキテクチャの流れ
この課題に対するソリューションのアーキテクチャ図1 は、以下のように構成されます。
- RDS 上で動作する MySQL エンジンに、Sakila のサンプルデータベースを投入します。
- DMS タスク が Sakila データベースに接続し、データを Parquet 圧縮ファイルに変換し、dcp-macie という名前のバケットにロードします。
- Macie の分類ジョブが、機械学習やパターンマッチングなどの技術を組み合わせて dcp-macie バケット内のオブジェクトを分析し、オブジェクトに機密データが含まれているかどうかを判断し、その検出結果に関する詳細なレポートを生成します。
- Amazon EventBridge は、Macie の検出結果レポート発行のイベントを Amazon Kinesis Data Firehose にルーティングします。
- Kinesis Data Firehose は、これらのレポートを dcp-glue バケットに格納します。
- S3 イベント通知は、dcp-glue バケットにオブジェクトが作成されるたびに AWS Lambda 関数をトリガーします。
- Start Glue Workflow という Lambda 関数が Glue Workflow を開始します。
- Glue Workflow は、JSONL から Apache Parquet ファイル形式にデータを変換し、dcp-athena バケットに配置します。この変換によりバイナリに最適化されたカラムナストレージを使用でき、データクエリ時のパフォーマンスが向上し、ストレージの使用量が最適化されます。
- Athena は、Macie が生成したデータのクエリと可視化に使用されます。
注意: 読みやすくするため、S3 バケットの命名規則では、グローバル一意性の命名要件 を満たすために使用される AWS リージョンと AWS アカウント ID を含む末尾の文字列を省略します (例:dcp-athena-us-east-123456789012 )。
また、Sakila のデータベーススキーマ は以下のテーブルを含んでいます。
- actor
- address
- category
- city
- country
- customer
ソリューションを実装する
前提条件
このソリューションを構成する前に、AWS Identity and Access Management (IAM) ユーザーに、以下のサービスに対して適切なアクセス権を付与されている必要があります。
- AWS CloudFormation
- AWS IAM
- Amazon Virtual Private Cloud (Amazon VPC)
- Amazon Elastic Compute Cloud (Amazon EC2)
- AWS Key Management Service (AWS KMS)
- AWS Secrets Manager
- AWS Lambda
- Amazon RDS
- Amazon S3
- AWS DMS
- Amazon Macie
- Amazon Kinesis Data Firehose
- Amazon EventBridge
- AWS Glue
- Amazon Athena
必要な権限が記載された IAM ポリシーはこちらで確認できます。
ステップ 1 – CloudFormation テンプレートをデプロイする
CloudFormation を使用して、図1 に示した AWS リソースを迅速かつ一貫してプロビジョニングすることができます。事前に構築されたテンプレートファイルを通して、Infrastructure-as-Code(IaC)のアプローチでインフラストラクチャを作成します。
- CloudFormation テンプレートをダウンロードします。
- CloudFormation コンソールにアクセスします。
- 左メニューの スタックを選択します。
- スタックの作成 を選択し、新しいリソースを使用(標準) を選びます。
- ステップ 1 – テンプレートの指定 で、テンプレートファイルのアップロード を選択し、ファイルの選択 を選択して、先ほどダウンロードした template.yaml ファイルを選択します。
- Step 2 – スタックの詳細を指定 で、スタック名にお好みの名前を入力します。また、現在のアカウントに RDS のサービスロールが存在しない場合は、CreateRDSServiceRole というパラメータで作成するなど、必要に応じてパラメータを調整することも可能です。
- Step 3 – スタックオプションの設定で、次へ を選択します。
- Step 4 – レビュー で、AWS CloudFormationによって IAM リソースがカスタム名で作成される場合があることを承認します にチェックを入れ、スタックの作成 を選択します。
- スタックのステータスが CREATE_COMPLETE になるのを待ちます。
注意: プロビジョニングの完了まで、10 分程度かかると予想されます。
ステップ 2 – DMS タスクの実行
Amazon RDS インスタンスからデータを抽出するために、AWS DMS タスクを実行する必要があります。これにより、Macie は S3 バケットの Parquet 形式のデータを利用できるようになります。
- AWS DMS コンソールにアクセスします。
- 左メニューで、データベース移行タスク を選択します。
- rdstos3task という タスク識別子 を選択します。
- アクション を選択します。
- 開始/再開 オプションを選択します。
ステータスが ロード完了 に変わるとタスクが終了し、ターゲットバケット (dcp-macie) に移行されたデータが確認できるようになります。
各フォルダ内には、LOAD00000001.parquet のような名前のパーケットファイルが見えます。これで、S3 にエクスポートしたデータベースのコンテンツに機密データがあるかどうか、Macie を使って確認することができます。
ステップ 3 – Amazon Macie で分類ジョブを実行する
次に、S3 バケットの内容を評価できるように、データ分類ジョブを作成する必要があります。作成したジョブは一度だけ実行され、S3 バケットのコンテンツ全体を評価し、データ間で PII を識別できるかどうかを判断します。前述の通り、このジョブでは Macie で利用可能なマネージド識別子のみを使用します。また、独自のカスタム識別子を追加することも可能です。
- Macie のコンソールにアクセスします。
- 左側にあるメニュー内にある S3 バケット オプション を選択します。DMS タスクからの出力データを含む dcp-macie という S3 バケットを選択します。バケット名が表示されない場合は、1分ほど待って Refresh アイコンを選択する必要があるかもしれません。
- ジョブを作成 を選択します。
- 次へ を選択して続行します。
- 以下のスコープでジョブを作成します。
- 機密データ検出オプション: ワンタイムジョブ
- サンプリング深度: 100%
- 他の設定は全てデフォルト値のままにします。
- 次へ を選択して続行します。
- 次へ をもう一度選択して、カスタムデータ識別子 のセクションをスキップします。
- ジョブに名前と説明を付けます。
- 次へ を選択して続行します。
- 作成したジョブの詳細を確認し、送信 を選択します。
ジョブが正常に作成されたことを示す緑のバナーが表示されます。ジョブが完了するまでに最大 15 分ほどかかり、ステータスは active から complete に変更されます。ジョブの調査結果を開くには、ジョブのチェックボックスを選択し、結果を表示 を選択し、検出結果を表示 を選択します。
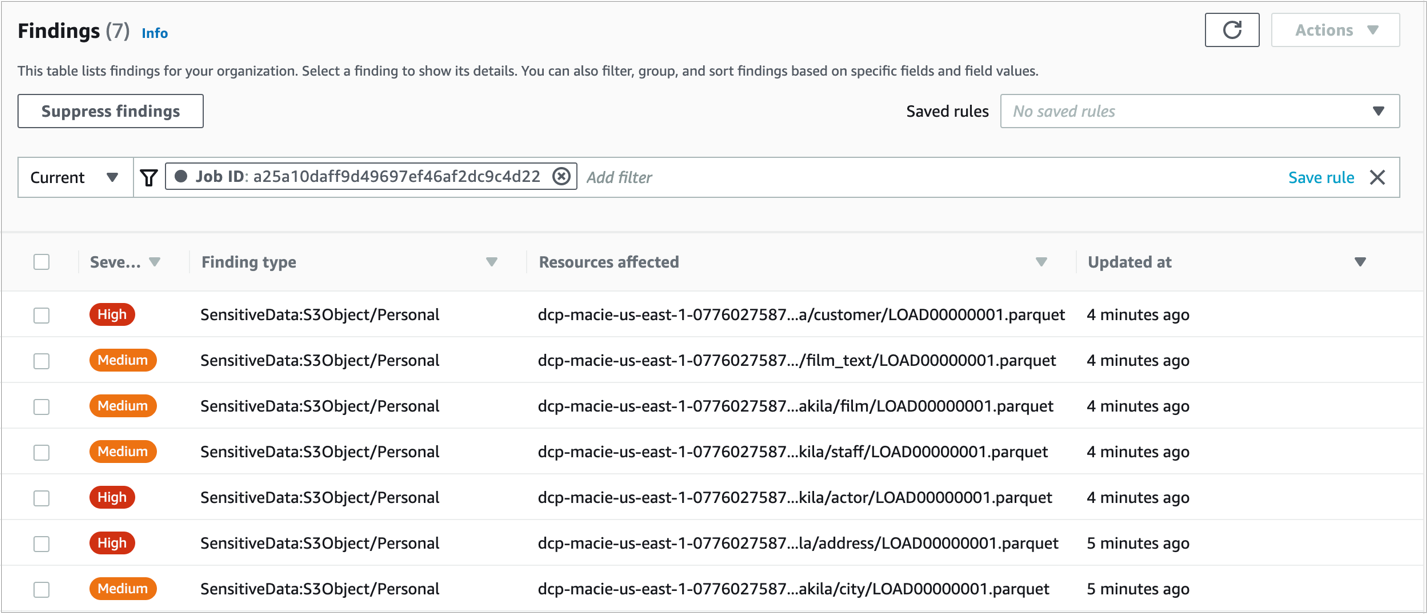
図2: Macie の検出結果の画面
注意: 詳細を見るためには検出結果画面にあるチェックボックスを選択します。
ステップ 4 – Amazon Athena で分類ジョブの結果へのクエリ実行のセットアップをする
- Athena コンソールにアクセスし、Query エディタを開きます。
- 初めて Athena を使用する場合、“Before you run your first query, you need to set up a query result location in Amazon S3. Learn more.” とメッセージが表示されます。このメッセージとともに表示されるリンクを選択します。
- 設定ウインドウで 選択する を選び、Athena のクエリ結果を格納する dcp-asset と名付けられたバケットを選択します。
- (Optional) クエリ結果を暗号化して保存するには、「クエリ結果を暗号化する」のボックスをチェックし、希望の暗号化方式を選択します。Amazon S3 の暗号化タイプの詳細については、暗号化を使用してデータを保護するを参照してください。
- 保存 を選択します。
ステップ 5 – Amazon Athena で Amazon Macie の検出結果をクエリする
Amazon Macie と AWS Glue 間のデータの流れが完了するまで、数分かかる場合があります。完了後、Athena のコンソールでデータベース dcp 内のテーブル dcp_athena が表示されます。
次に、テーブル dcp_athena の隣にある3つのドットを選択し、データプレビューを見るために テーブルのプレビュー オプションを選択するか、独自のカスタムクエリを実行します。
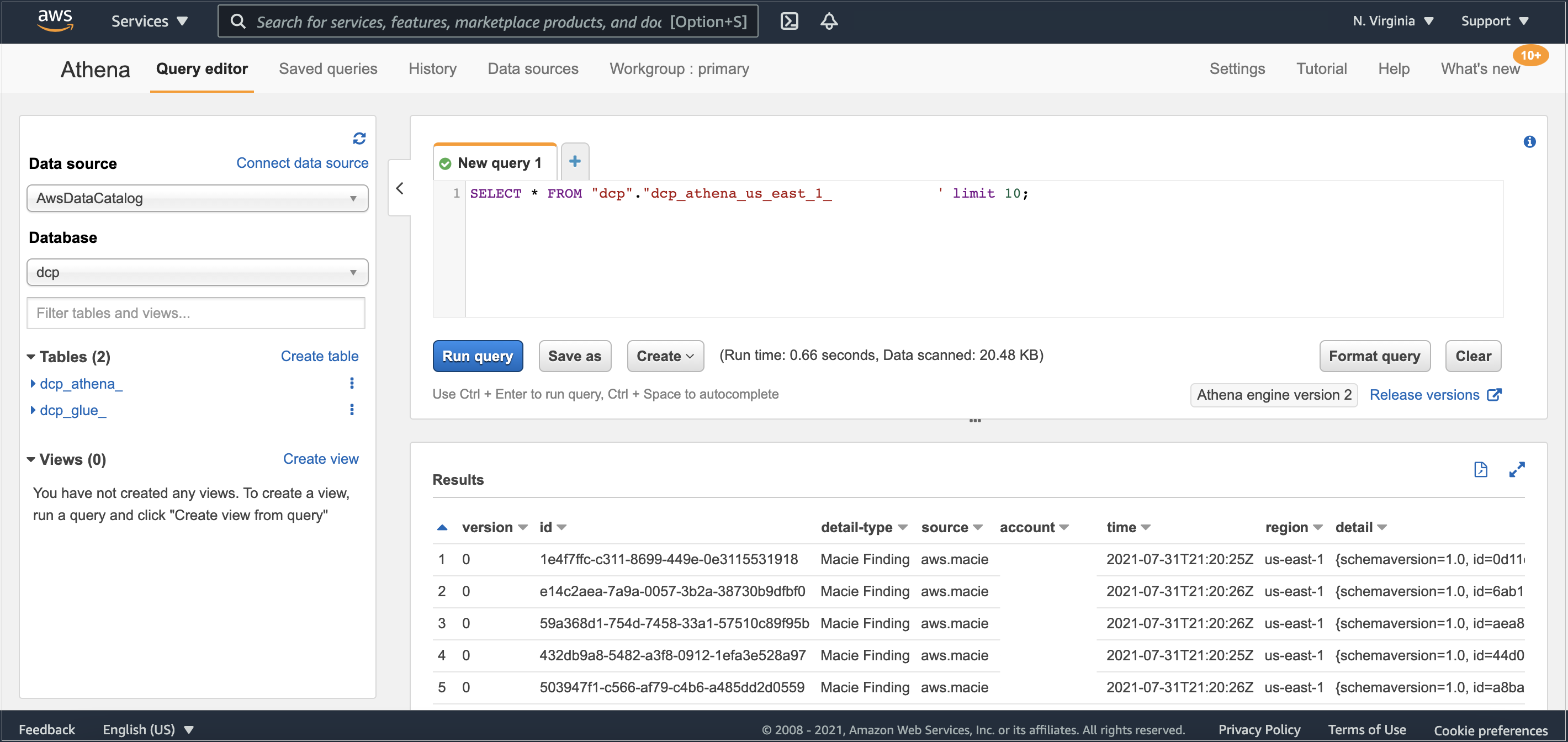
図3: Athena でテーブルプレビューを確認
環境が大きくなるにつれ、Top 10 Performance Tuning Tips for Amazon Athena を参考に、データのパーティショニングを適用し、必要に応じてより大きなファイルにデータを統合することができます。
クリーンアップ
終了後、作成したソリューションをクリーンアップし、不要な支出を避けるために、以下のステップを実行します。
- Amazon S3 コンソールに移動します。
- 以下にリストされた各バケットに移動して、そのオブジェクトを全て削除します。
- dcp-assets
- dcp-athena
- dcp-glue
- dcp-macie
- CloudFormation のコンソールへ移動する。
- 左側メニューの スタックを選択する。
- ステップ 1 – CloudFormation テンプレートをデプロイする で作成したスタックを選択します。
- 削除 を選択し、ポップアップウインドウの スタックの削除 を選択します。
まとめ
このブログでは、RDS でホストされた MySQL データベースにおいて、Macie のマネージドデータ識別子で Personally Identifiable Information(PII)、および機密情報として定義されたその他のデータを検出する方法を紹介しました。このソリューションは、RDS または EC2 上でホストされているかどうかにかかわらず、PostgreSQL、SQL Server、または Oracle などの他のリレーショナルデータベースで使用することができます。Amazon DynamoDB を使用している場合は、 Detecting sensitive data in DynamoDB with Macie も参考になると思います。データを分類することで、そのデータを使用する際の適切なデータ保護とハンドリングのコントロールを管理者に知らせることができます。
このブログに関するフィードバックがある場合は、英語版ブログ下部にあるコメント欄で送信してください。
AWS Security のハウツーコンテンツ、ニュース、機能アナウンスをより知りたい場合は、 Twitter でフォローしてください。
翻訳はソリューションアーキテクトの佐藤 航大が担当しました。原文はこちらです。