Amazon Web Services ブログ
Bristol-Myers Squibb が AWS Storage Gateway と Amazon S3 を使用して科学データを管理する方法
Bristol-Myers Squibb (BMS) は、革新的な医薬品を発見し、開発することで、深刻な病気の治療、管理、治療に貢献しています。AWS のサービスを多数使用して、科学データ、ラボでのワークフロー、大規模な計算を管理し、分子データ、細胞データセット、臨床データセットを分析しています。BMS のラボで生成したゲノミクスや臨床データは、飛躍的な速さで膨張しています。それだけにとどまらず、BMS では学術医療センター、医療プロバイダー、その他の共同研究者などの外部ソースからも、さまざまな臨床データを収集しています。いろいろなデータのソースがあるため、データ形式の種類は幅広くなります。
結果として、ペタバイト規模のデータセットを統合して分析するには、BMS にとってクラウドは最も便利なツールになります。オンプレミスのデータセンターからサイロ化されたデータにアクセスするのとは異なり、クラウドでは膨張しつつあるデータセットに社内の関係者によるオンデマンドでのアクセスが可能となるため、BMS での科学的革新の加速に貢献しています。現在 AWS が提供している数多くのクラウドストレージサービスの中でも、Amazon Simple Storage Service (Amazon S3) と AWS Storage Gateway は BMS で中心的な役割を果たしています。これらのサービスは、科学データを臨床データレイクに移動させ、さまざまな手法や方法を利用して数え切れないほどのライフサイエンスデータ分析プロセスを行うサポートとなっています。
Amazon S3 は、業界をリードするスケーラビリティ、データの可用性、セキュリティ、およびパフォーマンスを提供するオブジェクトストレージサービスです。Storage Gateway はハイブリッドのクラウドストレージサービスで、オンプレミスで実質的に無制限のクラウドストレージにアクセスすることが可能となります。
このブログ投稿では、私がシニアクラウドアーキテクトとして勤務する BMS が、ライフサイエンスアプリケーションで Amazon S3 と Storage Gateway をどのように使用しているかに焦点を当てています。この投稿はある程度まで、AWS re:Invent 2019 で行われたプレゼンテーションの「STG305 Build hybrid storage architectures with AWS Storage Gateway」に沿っています。これは、数ヶ月前に上司である Mohamad Shaikh 氏と共に発表したものです。 このセッションにおいてカバーしきれなかった BMS での Amazon S3 と Storage Gateway のユースケースに注目する予定です。
次は、re:Invent でのセッションの 9 分間の短い動画です。
BMS が Amazon S3 をどのように利用しているか
私たちは複数のさまざまなデータパイプラインから取得したペタバイト級の科学データを、Amazon S3 で保持しています。BMS では Amazon Athena、Amazon EMR、AWS Glue を活用して、データの統合、クエリ、分析を行っています。こうして、いろいろな研究やデータソースから重要な科学的洞察を引き出しています。
Amazon S3 が非常に成功し、BMS で広く採用された主な理由の 1 つに、AWS がアクセス管理とセキュリティに注力していることが挙げられます。この結果、組織がアクセス許可のないユーザーから何百万ものファイルを保護することが可能となりましたが、それだけでなく、複数の適正なアプリケーションやチームとの共有も行うことができます。途中で権限を与えられた関係者に対し、データ暗号化を透過的に維持できます。Amazon S3 を使うと、地理的に分散するさまざまな内部チーム、外部の科学機関、グローバルな協力体制の間で、極めてセキュアな方法でアクティブなデータ交換を促進できます。
私たちは Amazon S3 のフラットな非階層構造を採用し、ソース、機密度、可視性などのさまざまな基準に基づいて、多くの S3 バケットでデータを整理しています。場合によって、そのようなバケットは、ゲノムデータセットや科学機器からのライフサイエンス画像など、数億個のオブジェクトを保持することがあります。これらのバケットのサイズは、ペタバイトに達することが多くあります。ですが、柔軟なタグ付けシステム、よく考えられた命名規則、インデックス作成機能、データ管理システムのおかげで、当社のサイエンティストはこの膨大な量のデータをすばやく検索できます。
Amazon S3 は水平方向だけでなく垂直方向にも拡張性が高いため、大量のトランザクションを同時に処理できます。BMS は、この機能がハイパフォーマンスコンピューティング (HPC) のニーズをサポートする際に使用する複数のビッグデータとクラスターソリューションにおいて特に役立つことを発見しました。他の分野と同様に、こうしたニーズは、遺伝データの研究、複雑な化合物の視覚化、科学実験装置からのデータストリームのキャプチャ、およびデータの強化において目立っています。
それでも、クラウドでペタバイトの科学データを維持することには責任が伴います。ここ BMS では、データのライフサイクル、暗号化、コンプライアンス、コストの最適化について、真剣に考えています。Amazon S3 のデフォルトの「標準」ストレージクラスは、99.999999999% (9 が 11 個) の耐久性、高い SLA、低レイテンシーでのアクセスを持ち、ギガバイトあたりの費用対効果が高いストレージ向けに設計されています。さらに、アクティブ性の低いまたはアーカイブのデータセットに他の S3 ストレージクラスを採用することで、大幅な節約を達成できます。
Amazon S3 バケットのほとんどは Amazon S3 標準にあるため、研究目的で必要なときにすぐにデータにアクセスできます。ただし、アイドルデータは業界のコンプライアンス上の理由から、長期保存用にアーカイブする必要があります。そのため、使用しなくなったデータを保存するのに費用対効果の高いソリューションとして、Amazon S3 Glacier を選択しました。私たちは、バケットのモニタリング、ライフサイクルルールの微調整、ストレージクラス間でのデータの移動に、多くの時間と労力を費やしました。後に、S3 Intelligent-Tiering を使うと、少い費用で、クラス間の移動データの管理に費やす時間を削減できることがわかりました。データを S3 Intelligent-Tiering に移行し、新しいライフサイクルポリシーを確立すると、S3 Intelligent-Tiering は使用パターンに基づいてデータ移動の処理を開始しました。
AWS Storage Gateway を使用してデータをクラウドに移動する
Bristol-Myers Squibb が使用するもう 1 つの AWS のサービスに、ハイブリッドクラウドストレージサービスである Storage Gateway があります。これで、Storage Gateway を使ってテープバックアップをクラウドに移動したり、クラウドバックアップファイル共有を使用してオンプレミスストレージを削減したり、オンプレミスアプリケーション用に AWS のデータへの低レイテンシーでのアクセスを提供したりできます。Storage Gateway は、さまざまな移行、アーカイブ、処理、災害対策のユースケースでも使用できます。
BMS では、さまざまな方法でデータをクラウドに移動しています。その後、よく知られている 3V データ概念に従ってデータ処理を行います。
- データの多様性 (データはさまざまな形式を取ります)
- データ速度 (データは頻繁に変更か更新されます)
- データの正確性 (データの品質が低い、または不明な場合があります)
こうしたハイブリッドファイルストレージのユースケースでは、パイプラインがデータを Amazon S3 に効率的に転送する Storage Gateway の機能に依存していることがよくあります。また、次の図に示すように、S3 バケットの表示をファイルシステムとして示す Storage Gateway の機能も利用しています。これにより、アプリケーションを再び設計せずに、クラウドに移行しつつ、オンプレミスでレガシーアプリケーションも使用し続けることができます。
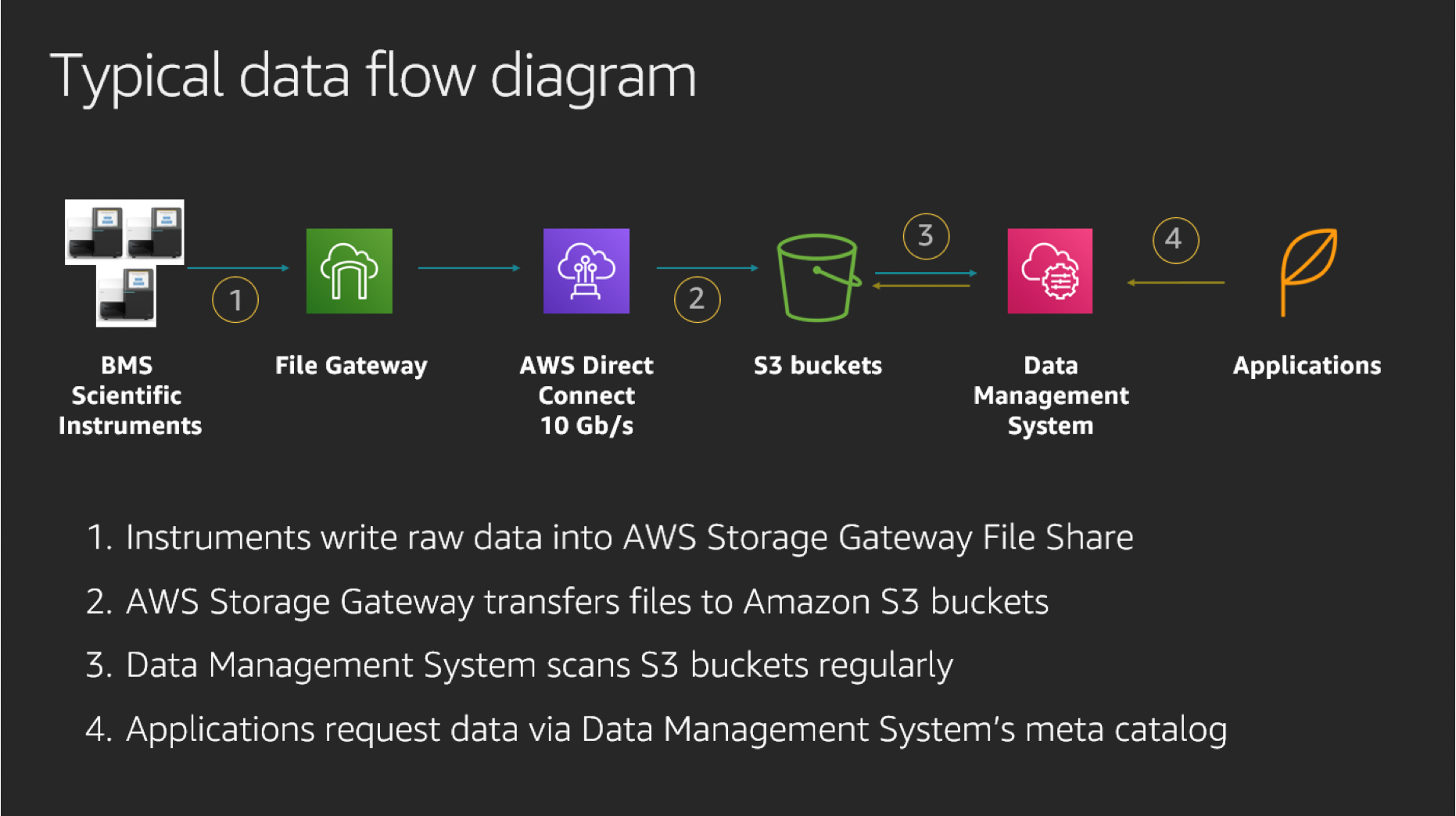
この図は、Storage Gateway ファイル共有に転送された科学機器からの未処理データを、S3 が対応するバケットにプッシュする方法を示しています。このデータは 10 GB/s の帯域幅で、AWS Direct Connect (DX) を介して Amazon S3 に移動します。データが S3 に到着すると、データ管理システムがメタデータタグでインデックス付け、登録、強化します。その後、データは社内のさまざまな HPC や科学アプリケーションで処理できるようになります。
次のアーキテクチャ図は、大規模な画像データセットの管理を扱う複雑なプロジェクトのニーズに対して、BMS がこの典型的なアーキテクチャパターンをどのように組み込むかを表しています。このプロジェクトでは、Storage Gateway が他のいくつかの AWS のサービスとともに S3 へのデータフローの中心で、BMS に完全なソリューションを提供しています。

ラボで作成した科学的データセットは、一般的なストレージプロトコルを使用してローカル NAS ストレージに一時的に書き込まれます。これは多くの場合、ライセンスに関する留意事項があり、S3 に直接データを書き込むことができないためです。初期データの取り込みには、AWS Snowballを使ってレガシーデータセットを移動します。これは、一度に数百テラバイトのデータをアップロードしようとする場合に効果的なアプローチです。他のデータも DX ラインを介して、継続して統合されます。各地理的位置にある複数の Storage Gateway アプライアンス (仮想およびハードウェア) は、自動化した非同期フローの新しいデータを Amazon S3 にコピーします。
次に、Amazon S3 バケットを内部データ管理システムがスキャンし、データレイクに統合する前に技術的なメタデータで強化します。これらの画像はさまざまな形式で届くため、サードパーティの API 呼び出しを使って標準の JPEG または TIFF 形式に変換します。ドメイン固有のアプリケーションから派生した追加のタグ付け、分析、分析情報も追加で獲得します。このデータの視覚化には、GPU ベースの EC2 インスタンスで実行する ML ベースのアルゴリズムを必要とすることがよくあります。
Storage Gateway は Amazon EC2 にあるお客様のデータセンターの仮想マシンとして、またはオンプレミスにインストールしたハードウェアアプライアンスのいずれかとしてデプロイ可能です。オンプレミスのゲートウェイを実装することで、Amazon S3 に保存したデータに低レイテンシーでアクセスできます。
Storage Gateway のハードウェアアプライアンスの完全な所有権と低レイテンシーは、BMS では特に有効であることがわかりました。Amazon S3 から初めてデータにアクセスする場合、データの取得に遅延があります。ただし、そのデータをその後取得する際は、ファイルがまだ存在し、ストレージキャッシュから提供されている限り、より高速となります。ハードウェアアプライアンスには、5 TB または 12 TB の使用可能なオールフラッシュキャッシュの 2 つのサイズがあります。アプライアンスのアクティベーションプロセス中、プロビジョニングソフトウェアはキャッシュ SSD に適した RAID 保護を自動的に設定するため、セットアップのプロセスが簡単でシームレスとなります。5 TB のアプライアンスで開始する場合、必要に応じて後に 12 TB のアプライアンスに拡張可能です。
Storage Gateway を使用して学んだこと
Storage Gateway を使用して学んだ教訓は主に 3 つあります。
- ネットワーク設定、プロキシ、およびファイアウォール設定に細心の注意を払う。
- 本番に入る前に、実際の科学機器の性能をテストする。
- 複数の Storage Gateway 間で同じ Amazon S3 バケットを共有する際は注意する。
Storage Gateway のデータ転送が低速となるのは、独自のネットワーク設定が原因であることがよくあります。最適な方法で微調整するには時間がかかり、システム管理者の専門知識が必要となる場合があります。多くの科学機器には異なる I/O パターンがあるので、実際の実験装置でテストを実施することも強くお勧めします。そうすれば、新しいデータフローパイプラインが、数日間は測定を行うような大量の書き込みや長時間の使用に耐えられるようになります。私たちの経験から、DX を Storage Gateway ハードウェアアプライアンスで使用することをお勧めします。Storage Gateway の効率的なデータ転送と DX の安定したネットワーク接続により、ユーザーエクスペリエンスが向上するからです。最後になりましたが、複数の Storage Gateway 間でデータセットを共有する際には、特別な注意が必要です。
複数の Storage Gateway 間で同じ Amazon S3 バケットを共有する
複数の Storage Gateway 間で同じ Amazon S3 バケットを共有する場合、注意を払う必要があるのはなぜでしょうか? Storage Gateway「A」は Storage Gateway「B」を介して行った Amazon S3 の変更を認識せず、Storage Gateway「A」を更新するには RefreshCache API 呼び出しが必要であることを考えてください。 RefreshCache プロセスは、データセットのサイズに応じて数分または数時間かかります。複数の Storage Gateway が同じ S3 バケットに書き込むのを防ぐためのシンプルですが効果的なソリューションでは、次のような S3 アクセスポリシーを使用しています。

こちらのポリシーの例では、DeleteObject および PutObject アクション (UserID が「TestUser」であるユーザーを除くすべてのユーザーのアクション) を拒否しています。
まとめ
BMS では長年 Amazon S3 と Storage Gateway を使用し、数百テラバイトの科学データをローカルの施設から AWS クラウドに毎日移動しています。AWS のサービスは効率的で信頼性と費用対効果が高く、多くの場合、ハードウェアインフラストラクチャへの依存を減らしながら、柔軟性と拡張性を高めます。
AWS Storage のポートフォリオは他にも多くの優れた製品で構成されており、BMS でも広く使用しています。近日公開される次のブログ投稿では、さまざまな EBS ボリュームタイプで Storage Gateway の I/O パフォーマンスを測定し、コスト削減手法のいくつかを解説します。私たちの経験を皆さまと共有することで、次回のライフサイエンスプロジェクトの科学データ管理のお役に立てれば幸いです。最後までお読みいただき、ありがとうございました。ご質問がある場合は、コメント欄に書き込んでください。