Amazon Web Services ブログ
Amazon ECR の利用状況とセキュリティレポートを実装する
本記事は米国時間 8 月 29 日に公開された “Implementing usage and security reporting for Amazon ECR” を翻訳したものです。
コンテナワークロードを管理する際、コンテナレジストリの一元的なオブザーバビリティを維持することはセキュリティと効率的なリソース利用のために不可欠です。Amazon Elastic Container Registry (ECR) は、イメージレベルとリポジトリレベルの両方でメトリクスを提供し、統合されたオブザーバビリティを構築する上で重要な役割を果たします。本記事では、これらのメトリクスをコスト内訳、利用状況メトリクス、セキュリティスキャン結果、および全リポジトリにわたるコンプライアンスステータスを含む、基本的で包括的なレポートに一元化する手順をご案内します。統合されたオブザーバビリティにより、利用パターンをより深く理解し、セキュリティリスクを特定し、セキュリティ要件と最適化のベストプラクティスに準拠させる必要があるリソースに優先順位を付けることが出来ます。
本記事では、サンプルコードを利用して 2 種類のレポートを生成します。1) リポジトリサマリーレポート – レジストリ内の全ての Amazon ECR リポジトリを一覧表示し、コスト、利用状況、Amazon ECR イメージスキャンで検出された OS 脆弱性の追跡と最適化に必要な属性を提供します。2) イメージレベルレポート – 特定のリポジトリ内の全てのイメージを含み、最初のレポートで発見された内容を詳しく調査するために利用可能な属性を提供します。
これらのレポートは、コスト削減のために未使用のリポジトリとイメージの特定に役立ち、最も多くまたは最も重いイメージを持つリポジトリとライフサイクルポリシーが欠けているリポジトリを強調するのに役立ちます。これらは、ストレージ利用状況、セキュリティスキャン状態、リポジトリ全体にわたる重要なセキュリティ発見事項に関する洞察を提供し、それによってより良いコスト管理、ポリシー実装、優先順位付けされたセキュリティ修復を可能にします。
ソリューション概要
このセクションでは、Amazon ECR リポジトリに関する詳細なレポートを生成するサンプルコードを実行する方法を示す実践的な例を提供します。2 種類のレポートは次のように説明されます。
リポジトリサマリー: レジストリ内のリポジトリのサマリーで、次の属性を提供します:
| 名前 | 説明 |
| repositoryName | リポジトリ名 |
| createdAt | リポジトリが作成された日付 |
| scanOnPush | リポジトリにプッシュされた後にイメージがスキャンされるかどうか |
| totalImages | リポジトリ内のイメージ / アーティファクトの総数 |
| totalSize(MB) | リポジトリ内のイメージ / アーティファクトの総サイズ (MB) |
| hasBeenPulled | リポジトリ内のいずれかのイメージが少なくとも 1 回プルされたか |
| lastRecordedPullTime | リポジトリ内のイメージが最後にプルされた日付 |
| daysSinceLastPull | リポジトリが最後のイメージプルを記録してからの日数 |
| lifecyclePolicyText | リポジトリのライフサイクルポリシーテキスト |
この情報は、どのリポジトリが最も多くのイメージを持っているか、どれが最も重いか (イメージ / アーティファクトの総サイズについて) 、どれがライフサイクルポリシーを欠いているかを特定するのに役立ちます。これらの要因は、リポジトリの維持コストに大きく影響します。最後に、このレポートでは、イメージがリポジトリにプッシュされた後にスキャンされるかどうかを確認できます。コンテナスキャンを有効にすることで、組織はセキュリティリスクを大幅に削減し、コンテナ化された環境で強力なセキュリティ態勢を維持できます。
totalSize (MB) フィールドは、Amazon ECR における総ストレージコストを見積もるために利用すべきではありません。なぜなら、これにはリポジトリ内で共通のイメージレイヤーを共有する Amazon ECR の最適化の利点が含まれていないからです。このフィールドは、より多くのストレージを消費しているリポジトリに関する洞察を提供し、それゆえ最適化の候補となり得る可能性があります。
イメージレベル: リポジトリ内の全てのイメージ / アーティファクトの主要な属性を提供します。
| 名前 | 説明 |
| repositoryName | リポジトリ名 |
| imageTags | イメージのタグ |
| imagePushedAt | イメージがプッシュされた日時 |
| imageSize(MB) | イメージサイズ (MB) |
| imageScanStatus | イメージのセキュリティスキャン状態 |
| imageScanCompletedAt | イメージが最後にスキャンされた日時 |
| findingSeverityCounts | イメージ内のセキュリティ検出結果の重要度別カウント |
| lastRecordedPullTime | イメージが最後にプルされた日時 |
| daysSinceLastPull | イメージが最後にプルされてから経過した日数 |
この情報はイメージとストレージ利用量を詳細に分析するのに役立ち、コスト削減のために削減可能な未使用イメージを特定するのに役立ちます。また、この内容はより効果的なライフサイクルポリシーを実施するための知見も提供します。例えば、1/ タグ付けされていないイメージをクリーンアップする、2/ リポジトリごとに一定数のイメージを残す、または 3/ 古いイメージを削除することです。
さらに、本レポートでは Amazon ECR 基本スキャンを利用しているユーザー向けに統合されたセキュリティ検出結果データを提供し、是正措置の優先順位付けを支援します。Amazon ECR 拡張スキャンを利用しているユーザーには、Amazon Inspector を通じて利用可能なセキュリティ機能と検出結果の利用をおすすめします。
前提条件
このウォークスルーを進めるには、以下の前提条件を満たしている必要があります
- 環境にインストールされた Finch (またはその他のコンテナビルドツール)
- 環境にインストールされた AWS Command Line Interface (AWS CLI)
- このポリシーを持つ AWS Identity and Access Management (IAM) プリンシパル (ユーザーまたはロール)
- 環境にインストールされた Git
ウォークスルー
以下の手順でこのソリューションを実行します。
コンテナイメージを設定する
リポジトリをクローンし、コンテナをビルドします。
git clone https://github.com/aws-samples/amazon-ecr-cost-vulnerability-and-usage-reporting.git
cd amazon-ecr-cost-vulnerability-and-usage-reporting
finch build -t ecr-reporter:v0.1.0 .
このコマンドは以下のパラメータでイメージをビルドします:
-t ecr-reporter:v0.1.0: イメージに名前 ecr-reporter とタグ v0.1.0 を付与します。名前とタグは任意の値に置き換え可能です。.: カレントディレクトリにある Dockerfile をビルドコンテキストとして利用します。
Docker を利用する場合、コマンド内の finch を docker に置き換え、その他のパラメータはすべて同じままにします。
リポジトリーサマリーレポートを実行する
- 以下のコマンドを実行してリポジトリサマリーレポートを生成する
LOG_VERBOSITY:DEBUG、INFO、WARNING、またはERRORを設定 (デフォルト:INFO)DECIMAL_SEPARATOR: CSV 数値フォーマットのために.または,を設定 (デフォルト:.)EXPORT_FORMAT: レポート生成に利用する区切り形式。csv、json、または parquet を設定 (デフォルト: csv)- リポジトリサマリーレポートを確認する
finch run \
-e AWS_ACCESS_KEY_ID=$(aws --profile aws-samples configure get aws_access_key_id) \
-e AWS_SECRET_ACCESS_KEY=$(aws --profile aws-samples configure get aws_secret_access_key) \
-e AWS_DEFAULT_REGION=us-east-1 \
-e AWS_SESSION_TOKEN=$(aws --profile aws-samples configure get aws_session_token) \
-v /Path:/data \
ecr-reporter:v0.1.0
このコマンドでは、aws-samples と言う名前のプロファイルを利用し、AWS リージョンは us-east-1 に設定されています。また、コンテナが停止した後もレポートをローカル環境 (この場合は /Path ) に永続化するためにボリュームを設定しています。コンテナには設定可能なパラメータがさらにあります。
コンテナを実行するための全パラメーターは、GitHub リポジトリで確認できます。
Docker を利用する際は、コマンド内の finch を docker
に置き換え、その他のパラメーターは全て同じにしてください。
指定された出力ディレクトリに、1 つの CSV ファイルが作成されます。レポートは以下のようになります:
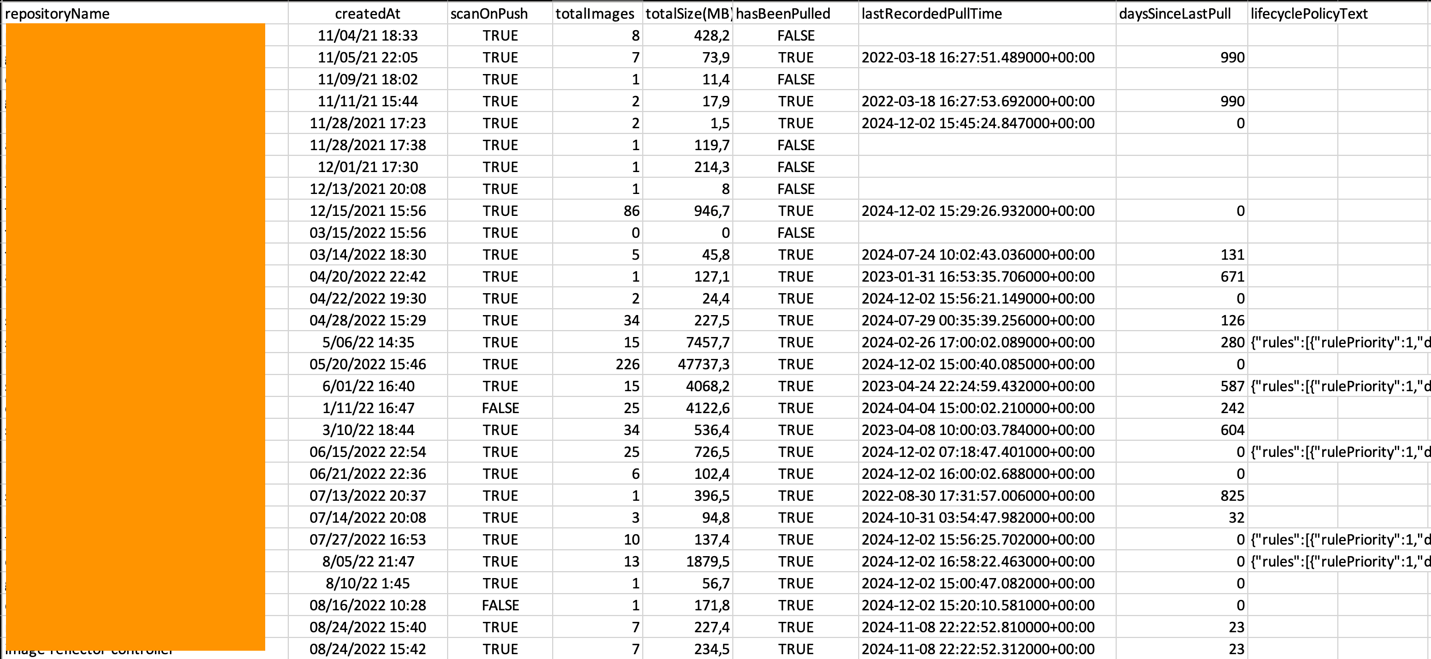 図 1: サンプルコンテンツ付きのリポジトリサマリーレポート
図 1: サンプルコンテンツ付きのリポジトリサマリーレポート
イメージレベルレポートを実行する
- リポジトリ
foobarのイメージレベルレポートを生成するには次のコマンドを実行する - イメージレベルレポートを確認する
finch run \
-e AWS_ACCESS_KEY_ID=$(aws --profile aws-samples configure get aws_access_key_id) \
-e AWS_SECRET_ACCESS_KEY=$(aws --profile aws-samples configure get aws_secret_access_key) \
-e AWS_DEFAULT_REGION=us-east-1 \
-e AWS_SESSION_TOKEN=$(aws --profile aws-samples configure get aws_session_token) \
-e REPORT=foobar
-v /Path:/data \
ecr-reporter:v0.1.0
イメージレベルレポートを生成するには、環境変数 REPORT にリポジトリ名を設定します。コンテナを実行するための全パラメーターは GitHub リポジトリで確認できます。
Docker を利用する際は、コマンド内の finch を docker
に置き換え、その他のパラメーターは全て同じにしてください。
指定した出力ディレクトリに、このレポートを含む 1 つの CSV ファイルが作成されます。レポートは次のようになります。
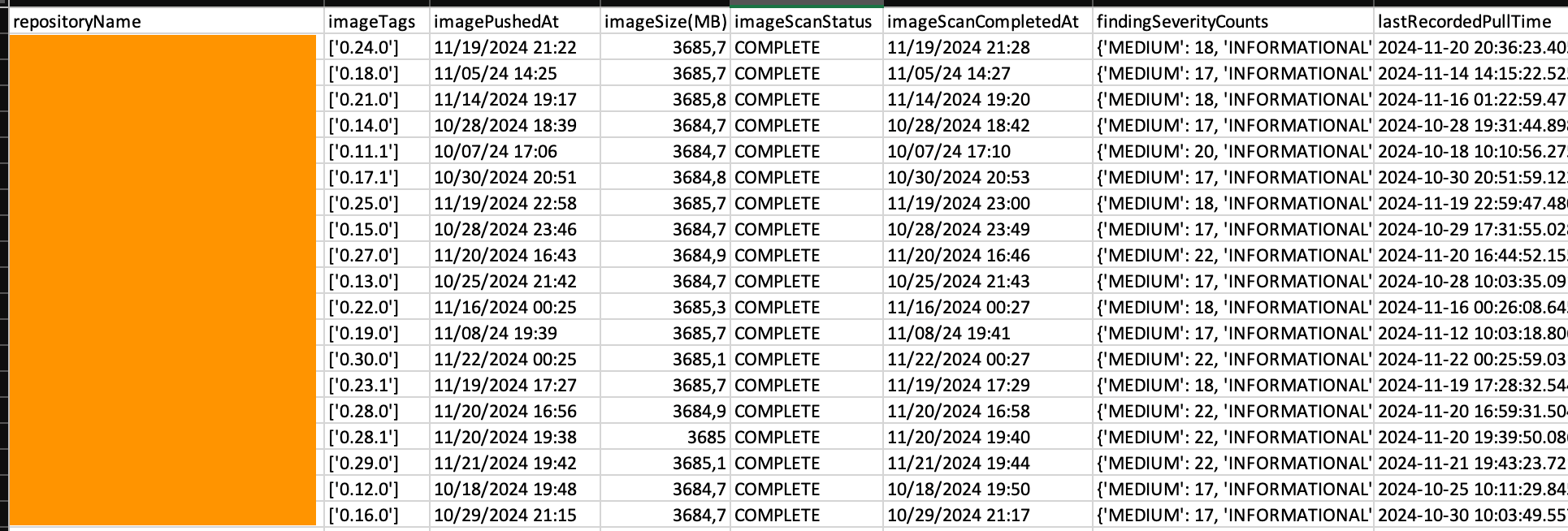 図 2: サンプルコンテンツ付きのイメージレベルレポート
図 2: サンプルコンテンツ付きのイメージレベルレポート
更なる取り組み (任意)
以下のステップは任意です。
レポート生成をスケジュールする
このコードは、AWS コンテナサービスにおいて 1) Amazon Elastic Kubernetes Service (Amazon EKS) における cron ジョブ (手順を参考に設定可能)、または 2) Amazon Elastic Container Service (Amazon ECS) でスケジュールされたタスクとして定期的に実行できます。
レポートを分析するために Amazon Athena を利用する
レポートを Amazon S3 に保存することもでき、Amazon Athena を利用してクエリを実行できます。これを行うには、特定のバケットにオブジェクトをアップロードする権限を付与するポリシーを IAM プリンシパルに設定する必要があります (ポリシー作成時にバケット名を指定してください) 。ポリシーをアタッチしたら、環境変数 AMAZON_S3_BUCKET にバケット名を設定することで各レポートを生成できます。
finch run \
-e AWS_ACCESS_KEY_ID=$(aws --profile aws-samples configure get aws_access_key_id) \
-e AWS_SECRET_ACCESS_KEY=$(aws --profile aws-samples configure get aws_secret_access_key) \
-e AWS_DEFAULT_REGION=us-east-1 \
-e AWS_SESSION_TOKEN=$(aws --profile aws-samples configure get aws_session_token)] \
-e AMAZON_S3_BUCKET=<s3 bucket name> \
-e EXPORT_FORMAT=csv \
ecr-reporter:v0.1.0
Docker を利用する際は、コマンド内の finch を docker
に置き換え、その他のパラメーターは全て同じにしてください。
レポート生成後、Athena を利用してその内容を分析できます。この例では、事前に Athena の設定が完了していることを前提としています。もし設定が完了していない場合は、このはじめにガイドに従って設定を完了し、その後戻ってきて続きを進めることができます。
- リポジトリ概要レポート用スキーマを格納するデータベース
ecr_repository_summaryを作成します。Athena クエリエディタで次のクエリを実行する - リポジトリサマリーレポートのテーブルスキーマを作成する
- 新しいテーブルをクエリしてデータを確認する
- インサイトを収集し、分析する
CREATE DATABASE IF NOT EXISTS ecr_repository_summary;
リポジトリサマリーレポートの詳細を表示するには、Amazon S3 に保存されているレポートのスキーマを保持するテーブルをこのデータベース内に作成する必要があります。これを実行するには Athena クエリエディタで次のクエリを実行できます。
CREATE EXTERNAL TABLE IF NOT EXISTS `repo_summary` (
`repositoryname` string COMMENT '',
`createdat` string COMMENT '',
`scanonpush` boolean COMMENT '',
`totalimages` bigint COMMENT '',
`totalsize(mb)` double COMMENT '',
`hasbeenpulled` boolean COMMENT '',
`lastrecordedpulltime` string COMMENT '',
`dayssincelastpull` bigint COMMENT '')
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://<s3 bucket name>/'
TBLPROPERTIES ``(
'areColumnsQuoted'='false',
'classification'='csv',
'columnsOrdered'='true',
'compressionType'='none',
'delimiter'=',',
'skip.header.line.count'='1',
'typeOfData'='file'
<s3 bucket name> は、生成されたレポートを保存するために作成したバケット名に置き換えることを覚えておいてください。
このクエリを実行後、repo_summary という名前の新しいテーブルが作成されます。このテーブルをクエリすることで、生成してバケットに保存したリポジトリサマリーサポート CSV におけるデータのレコードを取得できます。
SELECT * FROM "ecr_repository_summary"."repo_summary" limit 100;
この出力は以下のようになります。
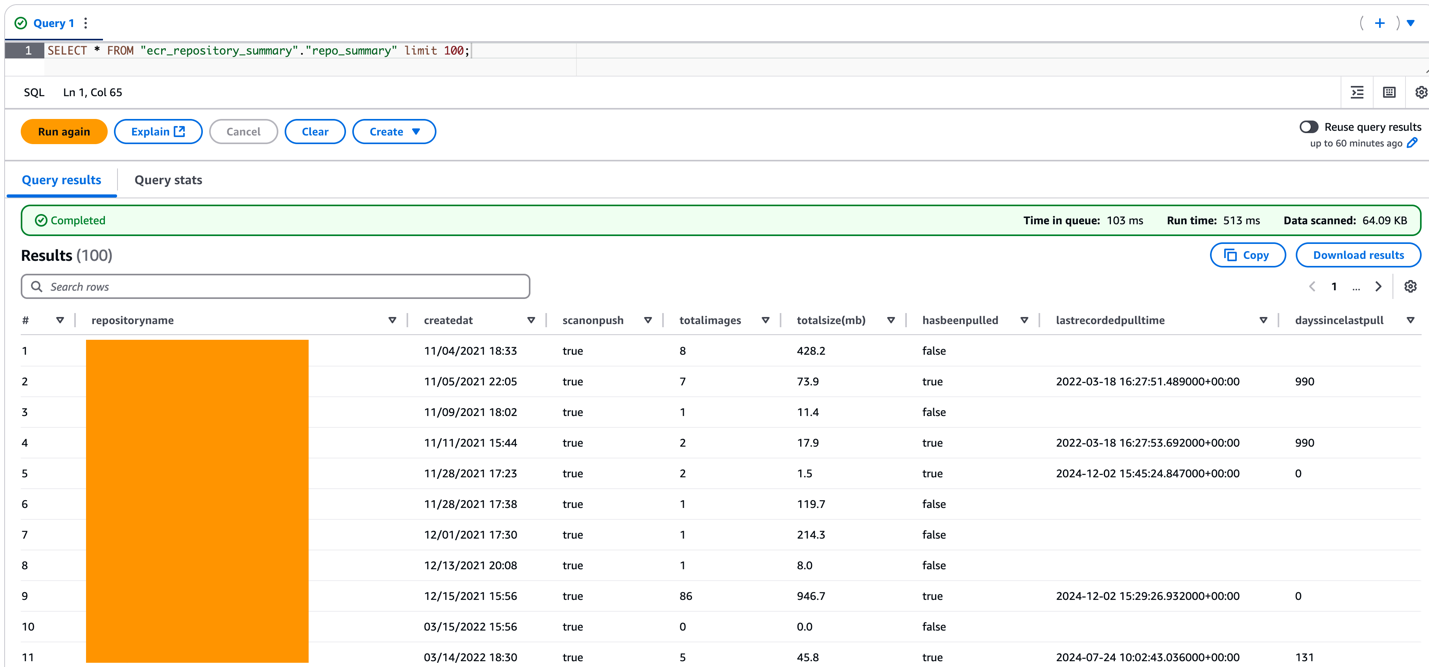 図 3: Amazon Athena を利用して SQL でリポジトリサマリーレポートを操作する
図 3: Amazon Athena を利用して SQL でリポジトリサマリーレポートを操作する
データをクエリする容易な方法ができたため、これを使用してコスト最適化、健全性、Amazon ECR リポジトリのメンテナンスに関する情報に基づいた意思決定に役立つ関連性のある洞察を得ることができます。例えば、以下のクエリを利用すると、ストレージ利用料が最も多いリポジトリを素早く特定できます。
SELECT *
FROM "ecr_repository_summary"."repo_summary"
ORDER BY "totalsize(mb)" DESC
limit 10;
あるいは、一度もプルされたことのないイメージを持つものを見つけることもできます。
SELECT *
FROM "ecr_repository_summary"."repo_summary"
WHERE hasbeenpulled = false
limit 10;
あるいは、1 年以上取得されていないものを探して、古いリソースを削除することもできます。
SELECT *
FROM "ecr_repository_summary"."repo_summary"
WHERE dayssincelastpull > 365
ORDER BY dayssincelastpull DESC
limit 10;
言い換えれば、このデータで好きなだけ創造性を発揮できるということです!この手順では、CSV 出力形式を利用しました。Parquet や JSON の利用も同様ですが、若干の変更が必要になる場合があります (本記事の範囲外です)。
クリーンアップ
レポートを Amazon S3 に保存し、Amazon Athena を利用して分析する場合、AWS アカウントに課金されます。もし、あなたが不要な課金が発生しないようにクリーンアップすることを決めたなら、このデプロイ中に作成された全ての AWS リソースを削除してください。
- Amazon S3 バケットとコンテンツを削除する
- Athena リソースをクリーンアップする
- IAM ユーザーやロールにアタッチされた IAM ポリシーをデタッチする
aws s3 rb s3://<bucket name> --force
# Delete Athena table using AWS CLI
aws athena start-query-execution \
--query-string "DROP TABLE IF EXISTS \`ecr_repository_summary\`.\`repo_summary\`;" \
--result-configuration OutputLocation= s3://<s3 bucket name>/
# Delete Athena database using AWS CLI
aws athena start-query-execution \
--query-string "DROP DATABASE IF EXISTS \`ecr_repository_summary\`;" \
--result-configuration OutputLocation= s3://<s3 bucket name>/
aws iam detach-user-policy --user-name <user name> --policy-arn <policy ARN>
aws iam detach-role-policy --role-name <role name> --policy-arn <policy ARN>
おわりに
パフォーマンスとイノベーションを維持しながら AWS コストを最適化することは、効果的なオブザーバビリティによって実現可能です。Amazon ECR に関するインサイトを活用することで、組織はコンテナ運用を強化するデータドリブンな意思決定を行うことができます。リポジトリに関する詳細な可視性 (コスト内訳、利用状況メトリクス、セキュリティスキャン結果、コンプライアンス状況など) により、チームはイノベーションを加速させながらコンテナインフラストラクチャを合理化する準備が整います。
本記事で提供されているサンプルコードを利用することで、Amazon ECR リポジトリに関するインサイトを提供するだけでなく、それぞれのイメージの詳細まで深く掘り下げることができる包括的なレポートを生成できます。これらのレポートにより、コスト効率性、効率的なリソース利用、セキュリティの強化を目的として Amazon ECR の利用状況を積極的にレビューし、最適化することが可能になります。ぜひ、サンプルコードをお試しいただき、フィードバックをお寄せください。皆様のご意見は、AWS コンテナコミュニティにより良いサービスを提供するための改善と強化に役立ちます。
ご質問、機能リクエスト、プロジェクトの貢献については GitHub リポジトリをご覧ください。