Amazon Web Services ブログ
Amazon Managed Service for Prometheus を使用してサービスメッシュコンテナ環境をモニタリングする
この記事は Monitoring your service mesh container environment using Amazon Managed Service for Prometheus (記事公開日 : 2021 年 4 月 20 日) の翻訳です。
オブザーバビリティは、いかなるアプリケーションにとっても、システムの挙動や性能を理解する上で重要です。性能劣化や障害を検知して修復するには、多くの時間と労力を要します。これは、多くのマイクロサービスが動いていて、リクエストの処理がいくつかのサービスにまたがっているようなマルチテナント環境では、より一層困難となります。サービスメッシュは、マイクロサービス間のネットワーク通信を処理します。
そのような複雑な環境でトラブルシューティングをしていると、途方にくれてしまうこともあるでしょう。アプリケーションのトレースは性能の問題を特定するのに重要な役割を果たしますが、サービスメッシュのコンポーネントのメトリクスも重要です。Prometheus はオープンソースのシステムモニタリング・アラートのソリューションとして広く利用されています。これには、アラートを配信、グループ化、停止するためのアラートマネージャが含まれます。また、メトリクス名とキーバリューペアで識別される時系列データを持つデータモデルと、大量のラベルに渡ってメトリクスを集約する柔軟なクエリ言語を提供します。Prometheus が収集した運用メトリクスを即座にクエリし、相関付け、可視化するために、私たちは広くデプロイされている可視化ツール Grafana を使用します。
Prometheus と Grafana をデプロイすることは容易ですが、複数サーバーにスケールさせ、高可用性、スケーラブル、セキュアな環境を構築するには非常に多くのエンジニアリングの労力を要します。メモリやストレージなどのリソースを最適化し、コストを制御しクエリのレスポンスタイムを向上させるには、より多くの時間を費やさなければなりません。Prometheus サーバーのパッチ適用やアップグレードなど、環境を継続的に維持するのは大変です。Amazon Managed Service for Prometheus (AMP) と Amazon Managed Grafana (AMG) を利用することで、重要なリソースのモニタリング能力に影響を与えることなく、オンデマンドでスケール可能な Prometheus サービスを運用できます。
AMP はコンテナのインフラストラクチャとアプリケーションメトリクスのための Prometheus 互換のモニタリングサービスで、大規模なコンテナ環境を簡単かつ安全にモニタリングできます。AMP を用いることで、ワークロードの増減に応じて運用メトリクスの挿入、保存、クエリを自動でスケールできます。AMG は大規模な運用データの可視化と分析を容易にするフルマネージド型サービスです。
Envoy メトリクス
組織は Amazon Elastic Kubernetes Service (Amazon EKS) や Amazon Elastic Container Service (Amazon ECS) などのオーケストレーションエンジンを利用して、マイクロサービスの活用範囲を拡大しています。このような組織では、異なるチームが所有するアプリケーションが異なる AWS アカウント、異なる VPC 内で実行されることが多く、アプリケーション間の一貫した接続性、オブザーバビリティ、セキュリティを実現するために AWS App Mesh などのサービスメッシュに依存しています。App Mesh は Amazon ECS や Amazon EKS、Amazon Elastic Compute Cloud (Amazon EC2) インスタンス、EC2 上で自己管理される Kubernetes で利用可能なマネージド型のサービスメッシュです。App Mesh は、異なるコンピュートプラットフォーム上で動くアプリケーションを共通のメッシュに容易に接続可能にします。App Mesh は Envoy プロキシを利用してアプリケーション間通信を標準化することで 、エンドツーエンドの可視性を提供し、高可用性の実現に役立ちます。AMP と AMG は、異なるコンピュートプラットフォーム上で動く組織全体に渡るコンテナからメトリクスを取り込む、信頼できる唯一の情報源として動作しますが、Envoy メトリクスを収集することも重要です。Envoy は異なるアプリケーション間のトラフィックのルーティングに役立つ、App Mesh の必要不可欠な要素です。
本ブログ記事では、マイクロサービスの健全性や性能をモニタリングするために、Amazon EKS クラスターから AMP に App Mesh Envoy メトリクスを取り込み、AMG 上でカスタムダッシュボードを作成する手順を紹介します。
このソリューションを実装する中で、私たちは
- AMP ワークスペースを作成します
- App Mesh Controller for Kubernetes をインストールし、Pod 内に Envoy コンテナを取り込みます
- EKS クラスター内に設定した Grafana エージェントを利用して Envoy メトリクスを収集し、AMP に書き込みます
- AMG ワークスペースを作成し、AMP をデータソースに設定します
- AMG 上に Grafana ダッシュボードを作成、設定します
前提条件
本ブログ記事の手順を完了するためには、以下が必要です。
- AWS CLI version 2
- eksctl
- kubectl
- jq
- helm
- AWS アカウント内に設定された AMP ワークスペース。手順に関しては、AMP ユーザーガイド内の Create a workspace を参照してください。
- AWS Single Sign-On (AWS SSO)。手順に関しては、AWS SSO ユーザーガイド内の Enable AWS SSO を参照してください。

EKS クラスターを作成する
まず、サンプルアプリケーションを動かすために、App Mesh を有効にする EKS クラスターを作成します。eks-cluster-config.yaml を使用して、eksctl CLI ツールでクラスターをデプロイします。
export AMP_EKS_CLUSTER=AMP-EKS-CLUSTER
export AMP_ACCOUNT_ID=<Your Account id>
export AWS_REGION=<Your Region>
cat << EOF > eks-cluster-config.yaml
---
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: $AMP_EKS_CLUSTER
region: $AWS_REGION
version: '1.18'
iam:
withOIDC: true
serviceAccounts:
- metadata:
name: appmesh-controller
namespace: appmesh-system
labels: {aws-usage: "application"}
attachPolicyARNs:
- "arn:aws:iam::aws:policy/AWSAppMeshFullAccess"
managedNodeGroups:
- name: default-ng
minSize: 1
maxSize: 3
desiredCapacity: 2
labels: {role: mngworker}
iam:
withAddonPolicies:
certManager: true
cloudWatch: true
appMesh: true
cloudWatch:
clusterLogging:
enableTypes: ["*"]
EOF以下のコマンドを実行して、EKS クラスターを作成します。
eksctl create cluster -f eks-cluster-config.yamlこのコマンドは AMP-EKS-CLUSTER という名前の EKS クラスターと、App Mesh controller for Kubernetes によって使われる appmesh-controller という名前のサービスアカウントを作成します。
次に、以下のコマンドを実行して App Mesh controller をインストールします。
まず、カスタムリソース定義 (CRD) を設定します。
helm repo add eks https://aws.github.io/eks-charts
helm upgrade -i appmesh-controller eks/appmesh-controller \
--namespace appmesh-system \
--set region=${AWS_REGION} \
--set serviceAccount.create=false \
--set serviceAccount.name=appmesh-controllerAMP ワークスペースを作成する
AMP ワークスペースは、Envoy から収集された Prometheus メトリクスを取り込むのに利用されます。ワークスペースは、メトリクスなどの Prometheus リソース専用の、論理的かつ隔離された Prometheus サーバーです。ワークスペースは、更新、リスト、記述、削除などの管理アクティビティや、メトリクスの取り込みやクエリの認可のための、きめ細やかなアクセスコントロールをサポートします。
aws amp create-workspace --alias AMP-APPMESH --region $AWS_REGION次に、任意の手順として、VPC 内にデプロイされたリソースからマネージド型サービスに安全にアクセスするためのインターフェース VPC エンドポイントを作成します。AMP のパブリックエンドポイントを利用することも可能です。この VPC エンドポイントを利用することで、マネージド型サービスに取り込まれるデータを、インターネットを経由せずに AWS ネットワーク内で保護することが可能です。ここに示すように、AWS CLI を用いて作成できます。VPC_ID や AWS_REGION、その他の値を自身の値に置き換えてください。
export VPC_ID=<Your EKS Cluster VPC Id>
aws ec2 create-vpc-endpoint \
--vpc-id $VPC_ID \
--service-name com.amazonaws.<$AWS_REGION>.aps-workspaces \
--security-group-ids <SECURITY_GROUP_IDS> \
--vpc-endpoint-type Interface \
--subnet-ids <SUBNET_IDS>
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo add kube-state-metrics https://kubernetes.github.io/kube-state-metricsメトリクスをスクレイピングする
AMP は、Kubernetes クラスター内のコンテナ化されたワークロードから運用メトリクスを直接スクレイピングする訳ではありません。このタスクを実行するためには、Prometheus サーバー、AWS Distro for OpenTelemetry Collector などの OpenTelemetry エージェント、Grafana エージェントのいずれかをデプロイ、管理する必要があります。本ブログ記事では、Grafana エージェントを設定して、Envoy メトリクスを収集し、AMP と AMG を用いて分析する手順を紹介します。
AMP 用の Grafana エージェントを設定する
Grafana エージェントは、Prometheus サーバー全体を動かす代替手段であり、軽量です。なぜなら、Prometheus Exporter を検出、スクレイピングして、メトリクスを Prometheus 互換のバックエンド (この場合は AMP) に送信するのに必要な部分を残し、ストレージやクエリ、アラートエンジンを取り除いているからです。Grafana エージェントは Prometheus メトリクスと 100% 互換であり、Prometheus サービスディスカバリ、スクレイピング、write-ahead ログ、リモート書き込みメカニズムを、Prometheus プロジェクトから利用しています。また Grafana エージェントは、Grafana エージェントの Pod と同じノードで実行されているメトリクスのみを収集することで、Amazon EKS クラスター内のすべてのノードにまたがる基本的なシャーディングをサポートします。これにより、すべての Prometheus メトリクスを収集する 1 つの巨大なマシンと、複数の手動管理の Prometheus によるシャーディングのうち、どちらか一方を選択する必要がなくなります。また Grafana エージェントは、AWS Identity and Access Management (IAM)認証のための AWS 署名バージョン 4 をネイティブにサポートするため、AWS 署名バージョン 4 プロキシをサイドカーで実行する必要がなくなり、複雑さやメモリ、CPU の需要を削減します。
本ブログ記事では、AMP に Prometheus メトリクスを送るための IAM ロールを設定する手順を紹介します。EKS クラスターに Grafana エージェントをインストールし、メトリクスを AMP に転送します。
権限を設定する
Grafana エージェントは Amazon EKS クラスターで動くコンテナ化されたワークロードの運用メトリクスをスクレイピングし、長期的な保存と Grafana などのモニタリングツールによるクエリのために AMP に送信します。AMP に送信されるデータは、マネージド型サービスに対するクライアントリクエストごとに認証・認可を行うため、AWS 署名バージョン 4 アルゴリズムを用いた有効な認証情報で署名しなければなりません。
Grafana エージェントは、Amazon EKS クラスターにデプロイすることで Kubernetes サービスアカウントのアイデンティティで実行できます。サービスアカウントの IAM ロール (IRSA) を利用することで、Kubernetes サービスアカウントと IAM ロールを関連付けることができ、そのサービスアカウントを使用したすべての Pod に IAM 権限を付与できます。Prometheus メトリクスを AMP に取り込むための AWS 署名バージョン 4 を含む Grafana エージェントを IRSA を利用して安全に設定することで、最小権限の原則に従うことができます。
agent-permissions-aks シェルスクリプトを利用して以下のアクションを実行できます。YOUR_EKS_CLUSTER_NAME を自身の Amazon EKS クラスターの名前に置き換えてください。
- AMP ワークスペースへのリモート書き込み権限を持つ IAM ポリシーがアタッチされた、EKS-GrafanaAgent-AMP-ServiceAccount-Role という名前の IAM ロールを作成します
- grafana-agent 名前空間に、その IAM ロールに関連づけられた grafana-agent という名前の Kubernetes サービスアカウントを作成します
- IAM ロールと Amazon EKS クラスター内にホストされた OIDC プロバイダーの間に信頼関係を構築します
このスクリプトを実行するためには、kubectl と eksctl CLI ツールが必要です。これらは Amazon EKS クラスターにアクセスするために利用されます。
kubectl create namespace grafana-agent
export WORKSPACE=$(aws amp list-workspaces | jq -r '.workspaces[] | select(.alias=="AMP-APPMESH").workspaceId')
export ROLE_ARN=$(aws iam get-role --role-name EKS-GrafanaAgent-AMP-ServiceAccount-Role --query Role.Arn --output text)
export REGION=$AWS_REGION
export NAMESPACE="grafana-agent"
export REMOTE_WRITE_URL="https://aps-workspaces.$REGION.amazonaws.com/workspaces/$WORKSPACE/api/v1/remote_write"そして、grafana-agent.yaml というマニフェストファイルを作成し、Envoy メトリクスを抽出するためのスクレイピングに関する設定を行い、Grafana エージェントをデプロイします。この例では、grafana-agent という名前の DaemonSet と grafana-agent-deployment という名前の (レプリカを 1 つ持つ) Deployment をデプロイします。grafana-agent DaemonSet は、クラスター上の Pod からメトリクスを収集します。grafana-agent-deployment は、Amazon EKS コントロールプレーンなどのクラスター上で動作していないサービスからメトリクスを収集します。本記事執筆時点 (2021年4月20日) では、Fargate データプレーンは DaemonSet をサポートしていないため、このソリューションは動作しません。
cat > grafana-agent.yaml <<EOF
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
eks.amazonaws.com/role-arn: ${ROLE_ARN}
name: grafana-agent
namespace: ${NAMESPACE}
---
apiVersion: v1
data:
agent.yml: |
prometheus:
configs:
- host_filter: true
name: agent
remote_write:
- sigv4:
enabled: true
region: ${REGION}
url: ${REMOTE_WRITE_URL}
scrape_configs:
- job_name: 'appmesh-envoy'
metrics_path: /stats/prometheus
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_container_name]
action: keep
regex: '^envoy$'
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: \${1}:9901
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: namespace
- source_labels: ['app']
action: replace
target_label: service
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
job_name: kubernetes-pods
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: drop
regex: "false"
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: keep
regex: .*-metrics
source_labels:
- __meta_kubernetes_pod_container_port_name
- action: replace
regex: (https?)
replacement: \$1
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
replacement: \$1
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: (.+?)(\:\d+)?;(\d+)
replacement: \$1:\$3
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: drop
regex: ""
source_labels:
- __meta_kubernetes_pod_label_name
- action: replace
replacement: \$1
separator: /
source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_pod_label_name
target_label: job
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: pod
- action: replace
source_labels:
- __meta_kubernetes_pod_container_name
target_label: container
- action: replace
separator: ':'
source_labels:
- __meta_kubernetes_pod_name
- __meta_kubernetes_pod_container_name
- __meta_kubernetes_pod_container_port_name
target_label: instance
- action: labelmap
regex: __meta_kubernetes_pod_annotation_prometheus_io_param_(.+)
replacement: __param_\$1
- action: drop
regex: Succeeded|Failed
source_labels:
- __meta_kubernetes_pod_phase
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: false
- bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
job_name: ${NAMESPACE}/kube-state-metrics
kubernetes_sd_configs:
- namespaces:
names:
- ${NAMESPACE}
role: pod
relabel_configs:
- action: keep
regex: kube-state-metrics
source_labels:
- __meta_kubernetes_pod_label_name
- action: replace
separator: ':'
source_labels:
- __meta_kubernetes_pod_name
- __meta_kubernetes_pod_container_name
- __meta_kubernetes_pod_container_port_name
target_label: instance
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: false
- bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
job_name: ${NAMESPACE}/node-exporter
kubernetes_sd_configs:
- namespaces:
names:
- ${NAMESPACE}
role: pod
relabel_configs:
- action: keep
regex: node-exporter
source_labels:
- __meta_kubernetes_pod_label_name
- action: replace
source_labels:
- __meta_kubernetes_pod_node_name
target_label: instance
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: namespace
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: false
- bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
job_name: kube-system/kubelet
kubernetes_sd_configs:
- role: node
relabel_configs:
- replacement: kubernetes.default.svc.cluster.local:443
target_label: __address__
- replacement: https
target_label: __scheme__
- regex: (.+)
replacement: /api/v1/nodes/\${1}/proxy/metrics
source_labels:
- __meta_kubernetes_node_name
target_label: __metrics_path__
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: false
- bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
job_name: kube-system/cadvisor
kubernetes_sd_configs:
- role: node
metric_relabel_configs:
- action: drop
regex: container_([a-z_]+);
source_labels:
- __name__
- image
- action: drop
regex: container_(network_tcp_usage_total|network_udp_usage_total|tasks_state|cpu_load_average_10s)
source_labels:
- __name__
relabel_configs:
- replacement: kubernetes.default.svc.cluster.local:443
target_label: __address__
- regex: (.+)
replacement: /api/v1/nodes/\${1}/proxy/metrics/cadvisor
source_labels:
- __meta_kubernetes_node_name
target_label: __metrics_path__
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: false
global:
scrape_interval: 15s
wal_directory: /var/lib/agent/data
server:
log_level: info
kind: ConfigMap
metadata:
name: grafana-agent
namespace: ${NAMESPACE}
---
apiVersion: v1
data:
agent.yml: |
prometheus:
configs:
- host_filter: false
name: agent
remote_write:
- sigv4:
enabled: true
region: ${REGION}
url: ${REMOTE_WRITE_URL}
scrape_configs:
- bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
job_name: default/kubernetes
kubernetes_sd_configs:
- role: endpoints
metric_relabel_configs:
- action: drop
regex: apiserver_admission_controller_admission_latencies_seconds_.*
source_labels:
- __name__
- action: drop
regex: apiserver_admission_step_admission_latencies_seconds_.*
source_labels:
- __name__
relabel_configs:
- action: keep
regex: apiserver
source_labels:
- __meta_kubernetes_service_label_component
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: false
server_name: kubernetes
global:
scrape_interval: 15s
wal_directory: /var/lib/agent/data
server:
log_level: info
kind: ConfigMap
metadata:
name: grafana-agent-deployment
namespace: ${NAMESPACE}
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: grafana-agent
rules:
- apiGroups:
- ""
resources:
- nodes
- nodes/proxy
- services
- endpoints
- pods
verbs:
- get
- list
- watch
- nonResourceURLs:
- /metrics
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: grafana-agent
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: grafana-agent
subjects:
- kind: ServiceAccount
name: grafana-agent
namespace: ${NAMESPACE}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: grafana-agent
namespace: ${NAMESPACE}
spec:
minReadySeconds: 10
selector:
matchLabels:
name: grafana-agent
template:
metadata:
labels:
name: grafana-agent
spec:
containers:
- args:
- -config.file=/etc/agent/agent.yml
- -prometheus.wal-directory=/tmp/agent/data
command:
- /bin/agent
env:
- name: HOSTNAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
image: grafana/agent:v0.11.0
imagePullPolicy: IfNotPresent
name: agent
ports:
- containerPort: 80
name: http-metrics
securityContext:
privileged: true
runAsUser: 0
volumeMounts:
- mountPath: /etc/agent
name: grafana-agent
serviceAccount: grafana-agent
tolerations:
- effect: NoSchedule
operator: Exists
volumes:
- configMap:
name: grafana-agent
name: grafana-agent
updateStrategy:
type: RollingUpdate
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana-agent-deployment
namespace: ${NAMESPACE}
spec:
minReadySeconds: 10
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
name: grafana-agent-deployment
template:
metadata:
labels:
name: grafana-agent-deployment
spec:
containers:
- args:
- -config.file=/etc/agent/agent.yml
- -prometheus.wal-directory=/tmp/agent/data
command:
- /bin/agent
env:
- name: HOSTNAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
image: grafana/agent:v0.11.0
imagePullPolicy: IfNotPresent
name: agent
ports:
- containerPort: 80
name: http-metrics
securityContext:
privileged: true
runAsUser: 0
volumeMounts:
- mountPath: /etc/agent
name: grafana-agent-deployment
serviceAccount: grafana-agent
volumes:
- configMap:
name: grafana-agent-deployment
name: grafana-agent-deployment
EOF
kubectl apply -f grafana-agent.yamlgrafana-agent がデプロイされると、メトリクスを収集して指定された AMP ワークスペースに取り込みます。さて、Amazon EKS クラスター上にサンプルアプリケーションをデプロイし、メトリクスの分析を始めましょう。
サンプルアプリケーションを EKS クラスター上にデプロイする
アプリケーションをインストールして Envoy コンテナを挿入するには、先ほど作成した App Mesh Controller for Kubernetes を利用します。AWS App Mesh Controller for K8s は、Kubernetes クラスター内の App Mesh リソースを管理します。コントローラーには CRD が付属しており、Deployment や Service などのネイティブな Kubernetes オブジェクトを定義するのと全く同じように、Kubernetes API を用いてメッシュや仮想ノードなどの App Mesh コンポーネントを定義できます。これらのカスタムリソースは、コントローラーが管理する App Mesh API オブジェクトにマッピングされます。コントローラーは、これらのカスタムリソースの変化をモニタリングし、App Mesh API に反映します。
## ベースとなるアプリケーションをインストールする
git clone https://github.com/aws/aws-app-mesh-examples.git
kubectl apply -f aws-app-mesh-examples/examples/apps/djapp/1_base_application
kubectl get all -n prod ## Pod のステータスが Running であることを確認
NAME READY STATUS RESTARTS AGE
pod/dj-cb77484d7-gx9vk 1/1 Running 0 6m8s
pod/jazz-v1-6b6b6dd4fc-xxj9s 1/1 Running 0 6m8s
pod/metal-v1-584b9ccd88-kj7kf 1/1 Running 0 6m8s
## App Mesh controller をインストールし、Deployment をメッシュ化する
kubectl apply -f aws-app-mesh-examples/examples/apps/djapp/2_meshed_application/
kubectl rollout restart deployment -n prod dj jazz-v1 metal-v1
kubectl get all -n prod ## Pod ごとに 2 つずつコンテナが見えていることを確認
NAME READY STATUS RESTARTS AGE
dj-7948b69dff-z6djf 2/2 Running 0 57s
jazz-v1-7cdc4fc4fc-wzc5d 2/2 Running 0 57s
metal-v1-7f499bb988-qtx7k 2/2 Running 0 57s
## この後 Grafana で可視化するために、5 分間トラフィックを発生させる
dj_pod=`kubectl get pod -n prod --no-headers -l app=dj -o jsonpath='{.items[*].metadata.name}'`
loop_counter=0
while [ $loop_counter -le 300 ] ; do kubectl exec -n prod -it $dj_pod -c dj -- curl jazz.prod.svc.cluster.local:9080 ; echo ; loop_counter=$[$loop_counter+1] ; doneAMG ワークスペースを作成する
AMG ワークスペースの作成は簡単です。Amazon Managed Service for Grafana を始めようのブログ記事の手順に従ってください。ダッシュボードへのユーザーアクセスを付与するためには、AWS SSO を有効化する必要があります。ワークスペースを作成したら、Grafana ワークスペースへのアクセスを個人ユーザーやユーザーグループに割り当てることが可能です。デフォルトでは、ユーザーは閲覧者のユーザータイプになっています。ユーザーの役割に応じてユーザータイプを変更してください。AMP ワークスペースをデータソースに追加して、ダッシュボードの作成を開始しましょう。 この例では、ユーザの名前は grafana-admin でユーザータイプは管理者です。必要なデータソースを選択し、設定を確認し、Create workspace を選択してください。 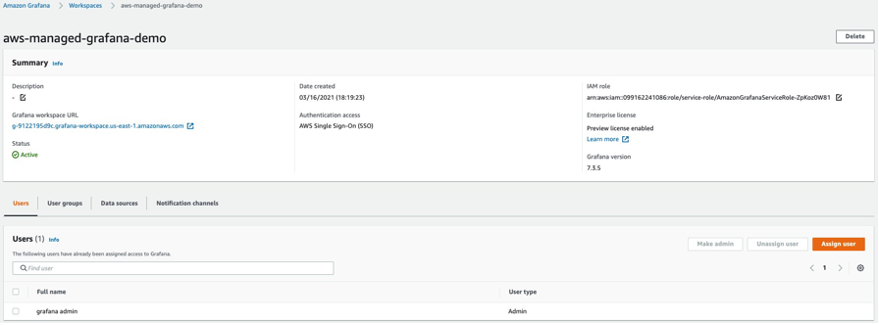
データソースとカスタムダッシュボードを設定する
AMP をデータソースに設定するには、Data sources のセクションで Configure in Grafana を選択し、ブラウザ上で Grafana ワークスペースを起動してください。Grafana ワークスペースの URL をブラウザに入力することでも起動できます。Amazon Managed Service for Grafana を始めようのブログ記事の指示に従い、データソースに先ほど作成した AMP ワークスペースを指定してください。 
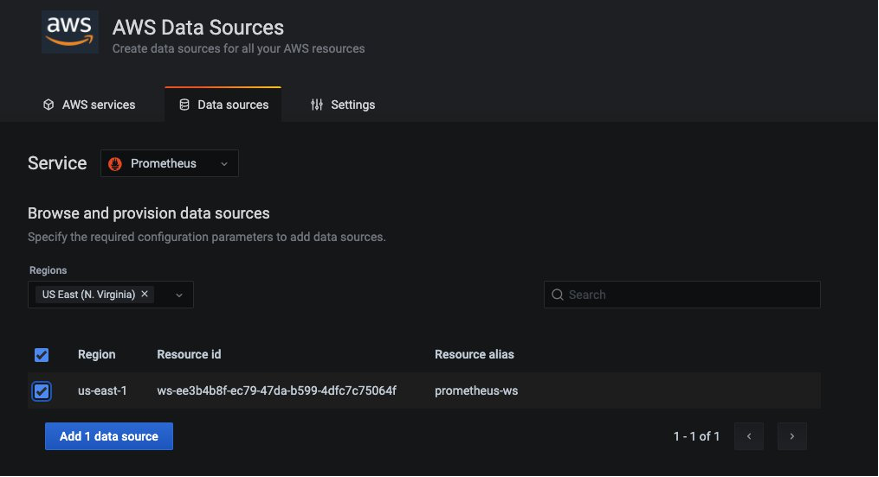 データソースを設定した後は、カスタムダッシュボードをインポートし Envoy メトリクスを分析します。(下図に示すように) Import を選択し、ID
データソースを設定した後は、カスタムダッシュボードをインポートし Envoy メトリクスを分析します。(下図に示すように) Import を選択し、ID 11022 を入力してください。Envoy Global ダッシュボードがインポートされ、Envoy メトリクスの分析を開始できます。 

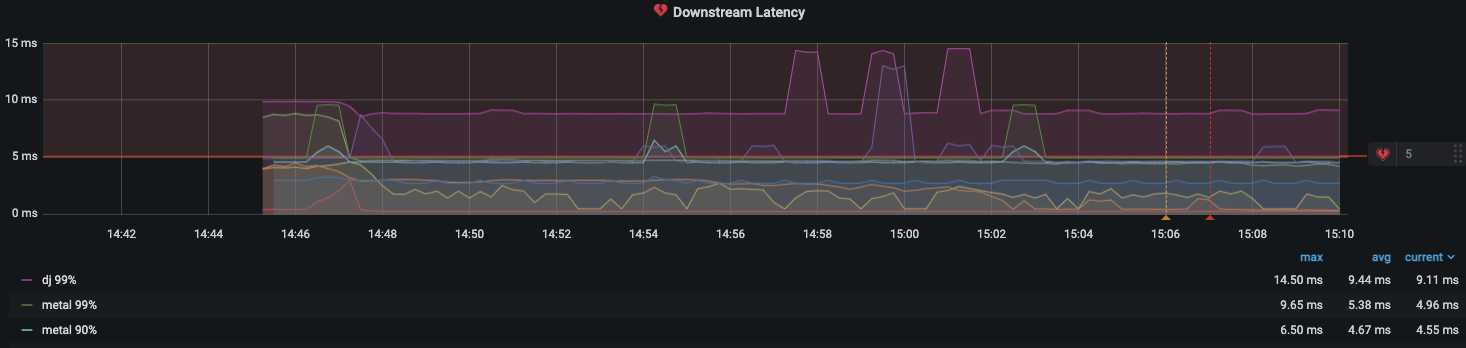
 スクリーンショットから見て取れるように、ダウンストリームのレイテンシー、接続数、レスポンスコードなどの Envoy メトリクスを可視化できます。フィルターを使って、特定の Envoy メトリクスに掘り下げることもできます。
スクリーンショットから見て取れるように、ダウンストリームのレイテンシー、接続数、レスポンスコードなどの Envoy メトリクスを可視化できます。フィルターを使って、特定の Envoy メトリクスに掘り下げることもできます。
AMG でアラートを設定する
メトリクスが閾値を上回ったときに Grafana アラートを設定することができます。AMG では、アラートがダッシュボード内でどのくらいの頻度で評価され、通知するかを設定できます。現在、AMG は Amazon SNS、Opsgenie、Slack、PagerDuty、VictorOp の通知タイプをサポートします。アラートルールを作成する前に、通知チャンネルを作成する必要があります。 この例では、通知チャンネルとして Amazon SNS を設定します。トピックへの通知を正しく発行するためには、SNS トピック名は grafana で始まる必要があります。 以下のコマンドを使って grafana-notification という名前の SNS トピックを作成し、email アドレスをサブスクライブします。
aws sns create-topic --name grafana-notification
aws sns subscribe --topic-arn arn:aws:sns:<region>:<account-id>:grafana-notification --protocol email --notification-endpoint <email-id>Grafana ダッシュボードから新しい通知チャンネルを追加します。

grafana-notification という名前の新しい通知チャンネルを設定します。Type には、ドロップダウンから AWS SNS を選択します。Topic には、今作成した SNS トピックの ARN を使用します。Auth Provider には、AWS SDK Default を選択します。
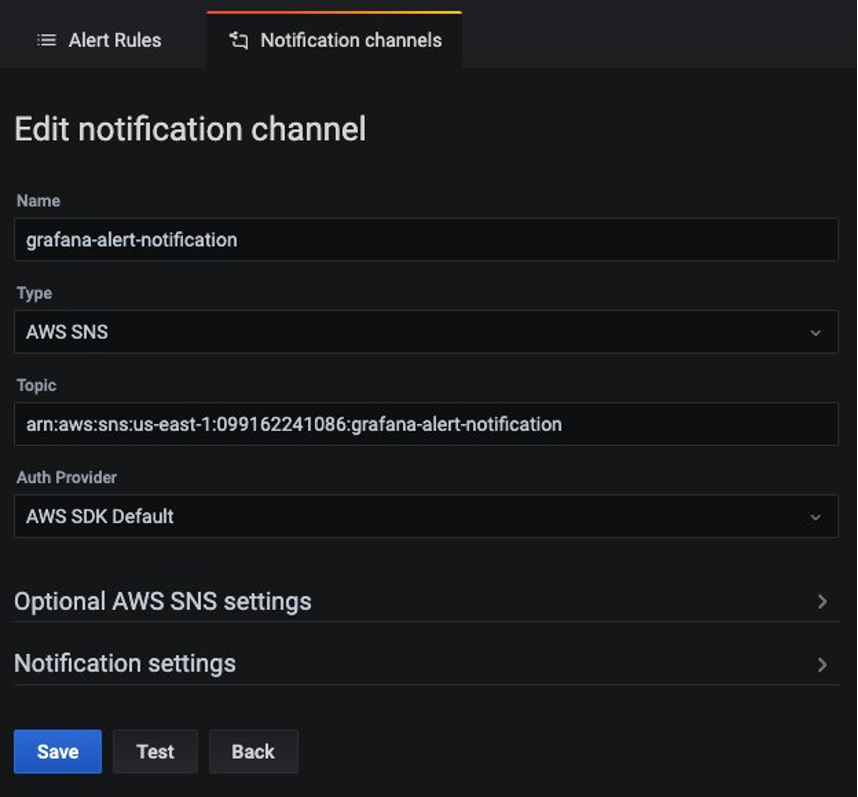
そして、1 分間でダウンストリームのレイテンシーが 5 ミリ秒を上回った場合にアラートを設定します。ダッシュボード内のドロップダウンから Downstream latency を選択し、Edit を選択します。グラフパネルの Alert タブで、どのくらいの頻度でアラートルールが評価されるべきか、そしてアラートが状態を変更し通知を作成するための条件を設定します。
以下の設定では、ダウンストリームのレイテンシーが閾値を上回った場合にアラートが作成され、grafana-alert-notification チャンネルから SNS トピックに通知が送信されます。

まとめ
本ブログ記事では、EKS 上で動くアプリケーションをデプロイし、アプリケーションを App Mesh と統合し、Grafana エージェントを利用して Prometheus メトリクスをスクレイピングし、AMP に送信し、AMG で可視化しました。AMP と AMG はフルマネージド型かつサーバレスのモニタリングサービスなので、モニタリング環境の管理を AWS に任せて、ビジネスを変革するアプリケーションに時間を費やすことができます。AMP は、Prometheus サーバーや ADOT、Grafana エージェントなどのいかなる Prometheus 互換のコレクターと併せて利用することで、Amazon ECS や AWS 上で自己管理される Kubernetes、オンプレミスのインフラストラクチャなど、他のコンテナ環境からもメトリクスを収集できます。
参考文献
- Using Amazon Managed Service for Prometheus to monitor EC2 environments
- Setting up cross-region metrics collection for Amazon Managed Prometheus workspaces
- Configuring Grafana Agent for Amazon Managed Service for Prometheus
- Setting up Grafana on EC2 to query metrics from Amazon Managed Service for Prometheus
- Using Service Meshes in AWS