Amazon Web Services ブログ
BIM データの要件定義から IDS を自動生成する: 生成 AI と AgentCore で実現するパラレル IDS ビルダー
はじめに
建設業界では、設計・施工・維持管理の各フェーズで BIM(Building Information Modeling)の活用が広がっています。一方で、実際は「BIM に必要なデータをどのように定義して、工程間で受け渡していくか」「受発注者で求める情報をどう揃えるか」という、データの要件をめぐる悩みが尽きません。発注者が思い描く BIM の姿と、実際に納品される BIM の中身が噛み合わず手戻りが発生する、というケースもあります。
この課題に対するアプローチの一つが IDS(Information Delivery Specification) です。建設分野のオープンな BIM 標準を策定する、国際的な非営利団体である buildingSMART が策定し、2024 年に v1.0 が承認された IDS は、「BIM に何が含まれているべきか」をコンピュータが解釈可能な形で定義するための仕様です。IDS があれば、納品された IFC ファイルが要件を満たしているかをツールで自動チェックできます。
本ブログでは、自然言語で書かれた BIM の要件定義書から、生成 AI が IDS を自動生成するソリューションを、実装レベルで解説します。核となる工夫は、Amazon Bedrock AgentCore Runtime と AWS Step Functions を組み合わせ、要件ごとに IDS specification を並列生成するアーキテクチャです。
なお本ブログは、1〜3 章で「なぜこの構成にしたのか」という課題とアプローチの考え方を、4 章で「どう実装したか」という詳細を扱い、5 章で適用上の考慮点に触れる構成になっています。
1. BIM 要件をどう揃えるか
BIM が業界に普及するにつれ、「納品された BIM モデルに、本当に必要なデータが入っているか」を確認する作業が、どのプロジェクトでも悩みどころになっています。例えば、以下のような課題が挙げられます。
- 受発注者間の要件ミスマッチ: 受注者が作る BIM と、発注者が求める要件が噛み合わない。納品段階で欲しい情報が入っていないと手戻りが発生する
- チェック業務の煩雑さ: 標準ルールはあるものの、完成物が仕様に沿っているかの確認を人手で行う必要があり、大規模な BIM ほど工数がかさむ
- 後工程での作り替えの難しさ: 設計時の BIM を施工や維持管理で活用しようとすると、データ要件が合わず作り替えが必要になる。そもそも「どんなデータを入れれば良いか」の定義自体が難しい
これらの課題の根底にあるのは、「BIM に必要なデータ要件を、誰もが同じ解釈で共有できる形にできていない」 ことです。Excel の要件定義書や PDF の仕様書は人間には読めますが、機械が自動で検証するには情報が構造化されていません。
2. IDS とは何か
ここで登場するのが IDS(Information Delivery Specification) です。IDS は buildingSMART が策定する国際標準で、「BIM の IFC ファイルに何が含まれているべきか」を XML 形式で機械可読に定義 します。IDS に対応する検証ツール(IfcTester など)を使えば、IFC ファイルが IDS の要件を満たしているかを自動で判定できます。
BIM 活用が拡大するなか、発注者・設計者・施工者・維持管理者の間で BIM に求める情報を共通フォーマットで共有できる IDS の重要性は、今後さらに増していくと考えられます。
IDS の基本構造
IDS の中身は、specification と呼ばれるルールの集まりです。1 つの specification は次の 2 つの要素から構成されます。
- applicability(適用対象): どの IFC 要素に対するルールか。たとえば「IfcWall (壁) すべて」「外部に面した IfcDoor (ドア) だけ」など
- requirements(要件): 対象要素が満たすべき条件。たとえば「Pset_WallCommon の FireRating プロパティが存在する」「Uniclass の分類コードが付与されている」など
両者で使える facet(ファセット、チェック項目) は 6 種類あります。
| ファセット | 意味 |
|---|---|
| entity | IFC エンティティの種別 (IfcWall, IfcDoor など) |
| attribute | IFC 標準属性 (Name, Description, GlobalId など) |
| property | プロパティセット内のプロパティ (Pset_WallCommon の FireRating など) |
| material | 材料の定義 |
| classification | 分類コード (Uniclass, OmniClass など) |
| partOf | 親子関係 (ある要素が何の下に属しているか) |
実際の IDS ファイルは XML です。たとえば「すべての壁に、Pset_WallCommon の FireRating プロパティが必須」という specification は、次のように表現されます。
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<ids:ids xmlns:ids="http://standards.buildingsmart.org/IDS"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://standards.buildingsmart.org/IDS
http://standards.buildingsmart.org/IDS/1.0/ids.xsd">
<ids:info>
<ids:title>耐火等級を持つ壁</ids:title>
</ids:info>
<ids:specifications>
<ids:specification ifcVersion="IFC4" name="耐火等級を持つ壁">
<!-- applicability: どの要素に適用するか(すべての壁) -->
<ids:applicability maxOccurs="unbounded">
<ids:entity>
<ids:name>
<ids:simpleValue>IFCWALL</ids:simpleValue>
</ids:name>
</ids:entity>
</ids:applicability>
<!-- requirements: 満たすべき条件(FireRating プロパティが必須) -->
<ids:requirements>
<ids:property dataType="IFCLABEL">
<ids:propertySet>
<ids:simpleValue>Pset_WallCommon</ids:simpleValue>
</ids:propertySet>
<ids:baseName>
<ids:simpleValue>FireRating</ids:simpleValue>
</ids:baseName>
</ids:property>
</ids:requirements>
</ids:specification>
</ids:specifications>
</ids:ids>applicability の entity で「壁 (IFCWALL) すべて」を対象に指定し、requirements の property で「Pset_WallCommon の FireRating プロパティを要求する」という意図を表しています。
IDS 作成の難しさ
IDS の強みは明確ですが、自分たちの要件を IDS として書き起こす 作業には、いくつかの壁があります。
- IDS は XML ベースの仕様で、書くには IFC スキーマの専門知識 が必要になる(どのエンティティが何のプロパティを持つか、正確な名前は何か、など)
- 要件が自社の Excel や PDF に「全ての壁に耐火等級を指定」といった自然言語で書かれているケースが多く、そのままでは IDS にならない
- プロジェクトのフェーズやユースケースごとに必要な IDS が異なるため、量的にも無視できない数の specification を作る必要がある
つまり「IDS が使える」ことと「IDS を作れる」ことの間には、まだ距離があります。この距離を埋めるのが、本ブログのソリューションです。
IDS を用いたチェックを実施する上での課題と、それぞれに求められる仕組みを整理すると、次のようになります。
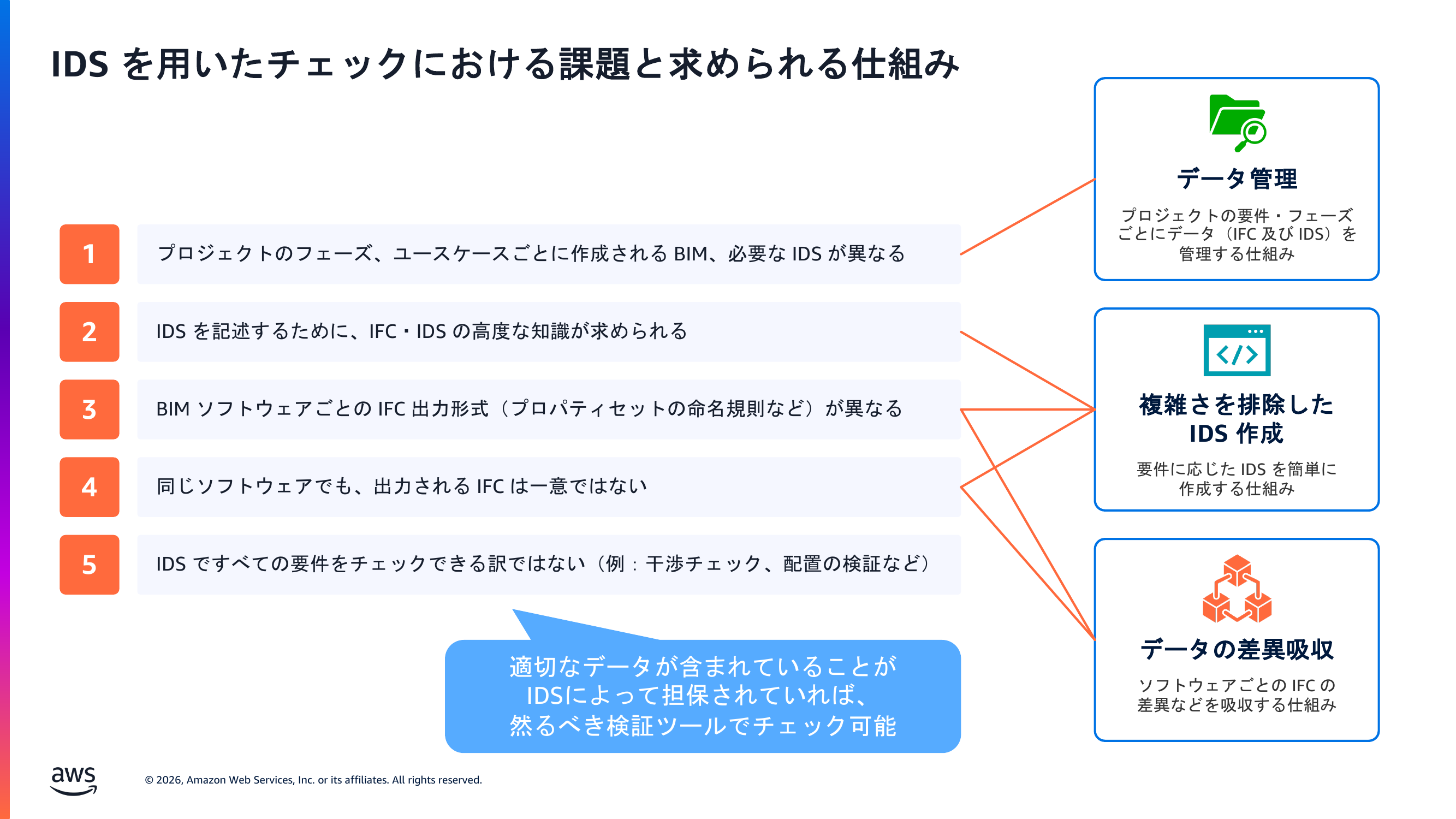
3. 課題の性質から設計を考える
具体的な AWS サービスの話に入る前に、まず「この課題をどういう考え方で解くか」を整理します。2 章までで見た IDS 作成の難しさを性質ごとに分解すると、取るべき打ち手が見えてきます。
- 要件は数十〜数百件ある → 1 件ずつ逐次で AI に処理させると、待ち時間が積み重なって現実的な時間に収まらないため、要件ごとに並列で処理する必要がある
- IDS を正しく書くには IFC スキーマの専門知識が要る → 「耐火等級」が IFC のどのプロパティ名にあたるか、といった知識を AI に与えないと正確な IDS にならない。そのため、専門知識を参照できる道具(ツール)を持った AI エージェントが適している(AI に単純なプロンプトを与えるだけでは精度が出にくい)
- 生成結果にミスがあると実用にならない → スキーマに違反した IDS は検証ツールで検証出来ないため、AI 自身が出力を検証し、誤りがあれば直すループが必要になる
これらを踏まえ、次のアプローチが考えられます。
自然言語で書かれた要件一覧を構造化し、要件ごとに専門知識を持った AI エージェントが並列で IDS specification を生成し、検証済みの結果を 1 つの IDS ファイルにまとめる。
機能の流れだけを抜き出すと、次のようなステップになります。具体的にどの AWS サービスで実現するかは 4 章で詳述します。
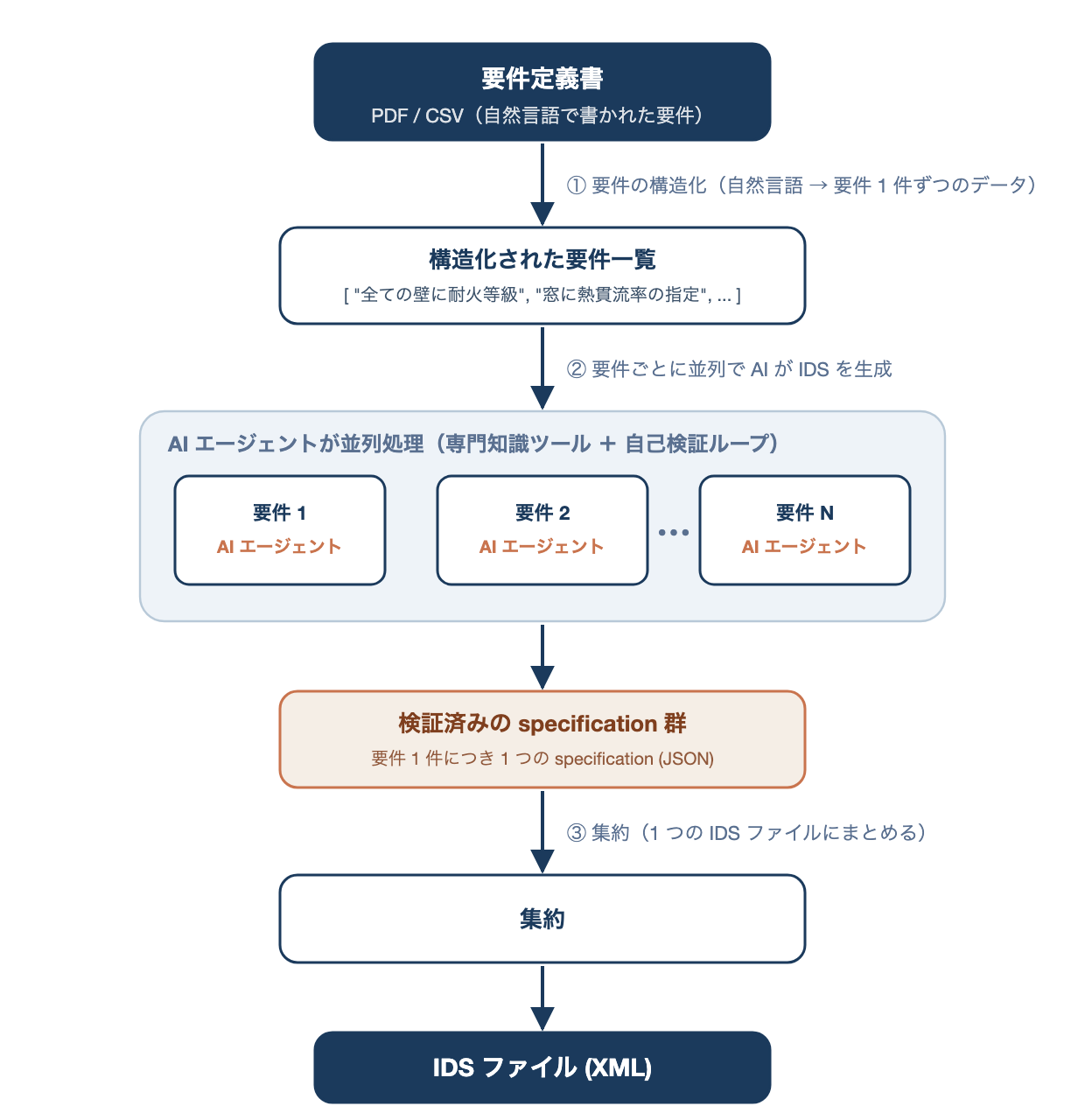
このアプローチのポイントは、「専門知識の付与(ツール)」「並列処理」「自己検証」という 3 つの仕組みを組み合わせ、人手では負担の大きい IDS 作成を自動化している点にあります。次章では、これを AWS 上でどう実装したかを見ていきます。
4. AWS 上での実装
ここからは、3 章のアプローチを AWS 上で具体的にどう実現したかを解説します。まず全体のアーキテクチャを示し、その後で実装上のポイントになる 3 点、すなわち「IDS 生成エージェントをどう書くか」「AgentCore でどう動かすか」「要件ごとに並列実行するオーケストレーション」を順に見ていきます。
4.1 アーキテクチャ全体像
3 章で説明した流れを、次のような構成で実装しています。
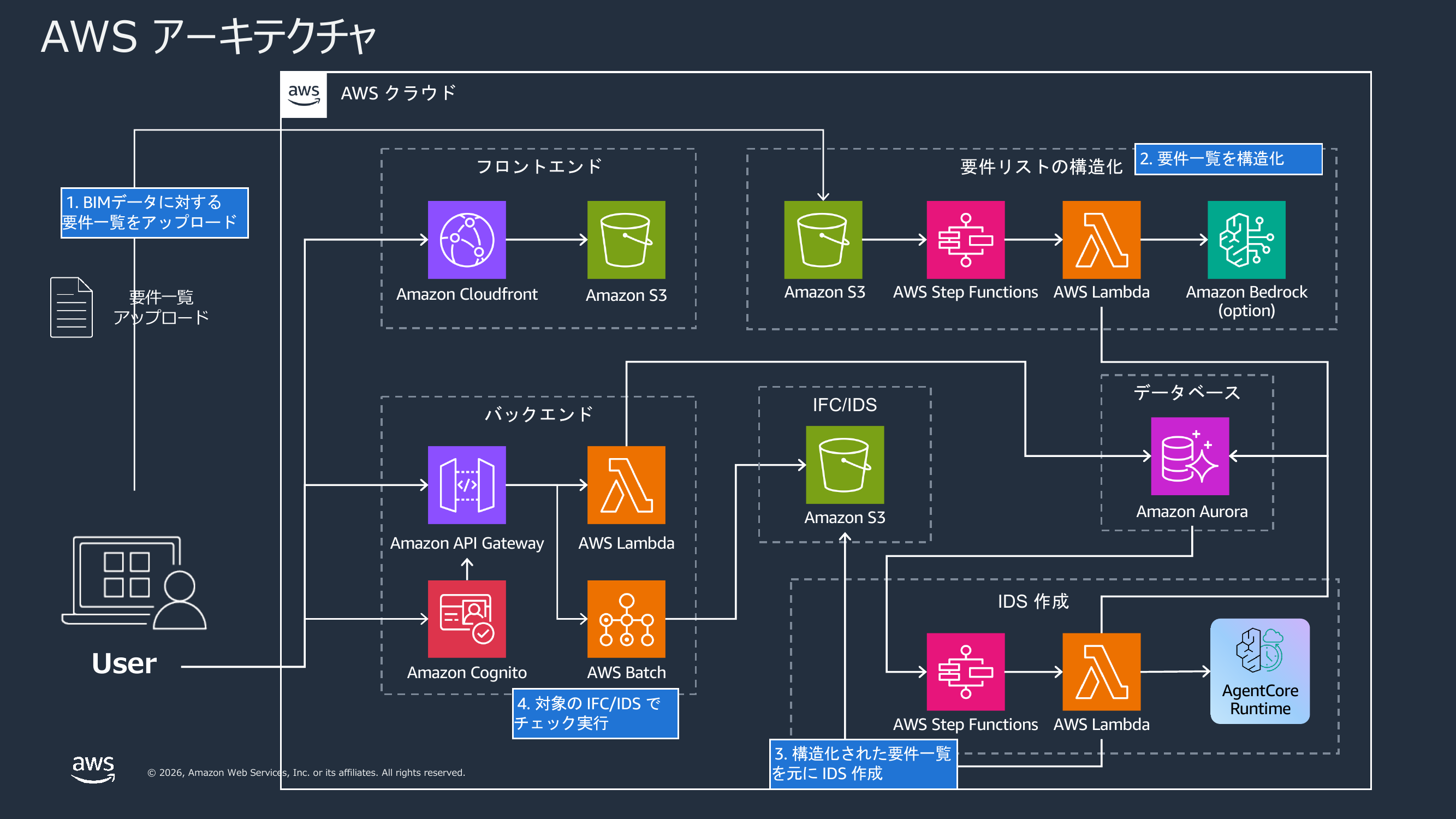
処理は大きく 3 つのフローに分かれます。要件の構造化と IDS 生成(3 章の①〜③)に加えて、生成した IDS で IFC を検証するフローも実装しています。
(1) 要件構造化フロー
- ユーザーがフロントエンドから要件定義書をアップロード
- 構造化用 AWS Lambda が Amazon S3 から要件定義書を取得し、生成 AI で要件を抽出・構造化
- 構造化された要件一覧を Amazon Aurora に保存
(2) IDS 生成フロー
- ユーザーが IDS 生成を実行すると、Step Functions の IDS 生成ワークフローが呼び出される
- Step Functions が「(1) 要件構造化フロー」で構造化された要件一覧を受け取り、要件 1 件ごとに並列で Amazon Bedrock AgentCore Runtime を起動
- 各 AgentCore Runtime が生成した specification を Aurora に保存
- 全要件の処理完了後、集約用 Lambda が specification を 1 つの IDS ファイルにまとめて S3 に保存
- ユーザーは生成された IDS ファイルを確認する
(3) 検証フロー
- ユーザーがチェック対象の IFC ファイルと、生成済みの IDS を指定して検証を実行
- 検証処理を AWS Batch 上で起動し、IFC ファイルが IDS の要件を満たしているかを判定(IfcTester を利用)
- 検証結果をユーザーに返し、要件を満たす/満たさない要素を一覧で確認
ここで出てきた「Amazon Bedrock AgentCore Runtime」は、2025 年に GA した、AI エージェントをデプロイ・実行するための AWS のサーバーレス環境です。Strands Agents、LangGraph、CrewAI など任意のフレームワークで書いたエージェントを、セッションごとに専用 microVM(分離された CPU・メモリ・ファイルシステム)で動かせるため、セッション間でデータが混ざりません。リアルタイムの対話だけでなく、最大 8 時間の長時間処理にも対応します。本実装では Strands Agents で書いた IDS 生成エージェントを AgentCore Runtime 上で実行しています。
4.2 IDS 生成エージェントの構造
3 章で挙げた「専門知識の付与」と「自己検証」を担うのが、この IDS 生成エージェントです。Strands Agents(AWS がオープンソースで公開しているエージェントフレームワーク)で記述し、Claude Sonnet 4.5 をモデルとして使用しています。エージェントには以下の 4 つのツールを与えています。
- schema_instruction_tool: IDS の TypeScript インタフェース定義、スキーマ制約などを返す
- ifc_knowledge_tool: IFC のエンティティ / プロパティ / 分類を検索するためのツール。たとえばエージェントが「wall」と検索すれば
IfcWallが、「耐火等級」と検索すればFireRatingがヒットする(=「専門知識の付与」を担うツール) - example_tool: 条件に応じたサンプルの Specification(25 件の実例)を返す。Few-Shot 学習の材料として、エージェントがプロンプトに取り込む
- validation_tool: 生成した仕様を jsonschema で検証し、エラーを AI にフィードバックする。エージェントは自己修正して再生成できる(=「自己検証ループ」を担うツール)
エージェントの本体は、Strands で記述されており、次のようなシンプルな書き方で定義できます。
# ids_generator_agent.py(抜粋・簡略化)
from bedrock_agentcore.runtime import BedrockAgentCoreApp
from strands import Agent
from strands.models import BedrockModel
from tools import (
schema_instruction_tool,
ifc_knowledge_tool,
example_tool,
validation_tool,
)
app = BedrockAgentCoreApp()
agent = Agent(
model=BedrockModel(
model_id="us.anthropic.claude-sonnet-4-5-20250929-v1:0",
temperature=0.3,
),
tools=[
schema_instruction_tool,
ifc_knowledge_tool,
example_tool,
validation_tool,
],
system_prompt=SYSTEM_PROMPT,
)
@app.entrypoint
async def agent_invocation(payload):
user_message = payload.get("prompt")
result = await agent.invoke_async(user_message)
return result.message
if __name__ == "__main__":
app.run()システムプロンプトには「出力は必ず純粋な JSON のみ」「markdown コードブロックや説明文を混ぜない」「IFC 用語は ifc_knowledge_tool で必ず検証する」といった細かい指示を含めており、出力の一貫性を担保しています。また、プロンプトで validation_tool を必ず最後に呼んでから返すよう指示することで、スキーマ違反の specification が保存されるリスクを防いでいます。
4.3 AgentCore Runtime へのデプロイ
Strands で書いたエージェントを AWS 上で動かすには、通常であれば Amazon ECS や Lambda のコンテナイメージを組み、Amazon API Gateway を前段に置いて…と手順が多くなります。AgentCore Runtime を使うと、こうしたデプロイ周りの作業が非常に簡単になります。AWS が提供する AgentCore Starter Toolkit(pip で導入できる CLI ツール)を使えば、ローカルでの開発・テストから本番デプロイまでを、次のようなコマンドで実現できます。
# ローカル開発 (ホットリロード付き)
agentcore dev
# ローカルテスト
agentcore invoke --dev "All walls must have a fire rating"
# 本番デプロイ
agentcore configure --entrypoint ids_generator_agent.py
agentcore launch4.4 Step Functions Map で IDS specification を並列生成する
ここが本実装の中心です。3 章で述べたとおり、BIM の要件定義書には、1 件のプロジェクトで数十〜数百件の要件が含まれることも珍しくありません。これを逐次で処理すると、AI 呼び出しの待ち時間が積み重なり、現実的な応答時間に収まりません。
そこで本実装では、Step Functions の Map ステート を使い、要件ごとに AgentCore Runtime を並列で呼び出します。Map ステートは「配列の各要素に対して同じ処理を実行する」ための制御で、並列度を制限したり、各要素のエラーを個別にハンドリングしたりできます。
処理フローを図にすると次のようになります。要件一覧を受け取った Map ステートが要件を 1 件ずつ並列レーンに割り当て、各レーンで AgentCore のエージェントが IDS を生成し、すべて出揃ったところで集約 Lambda が 1 つの IDS ファイルにまとめます。
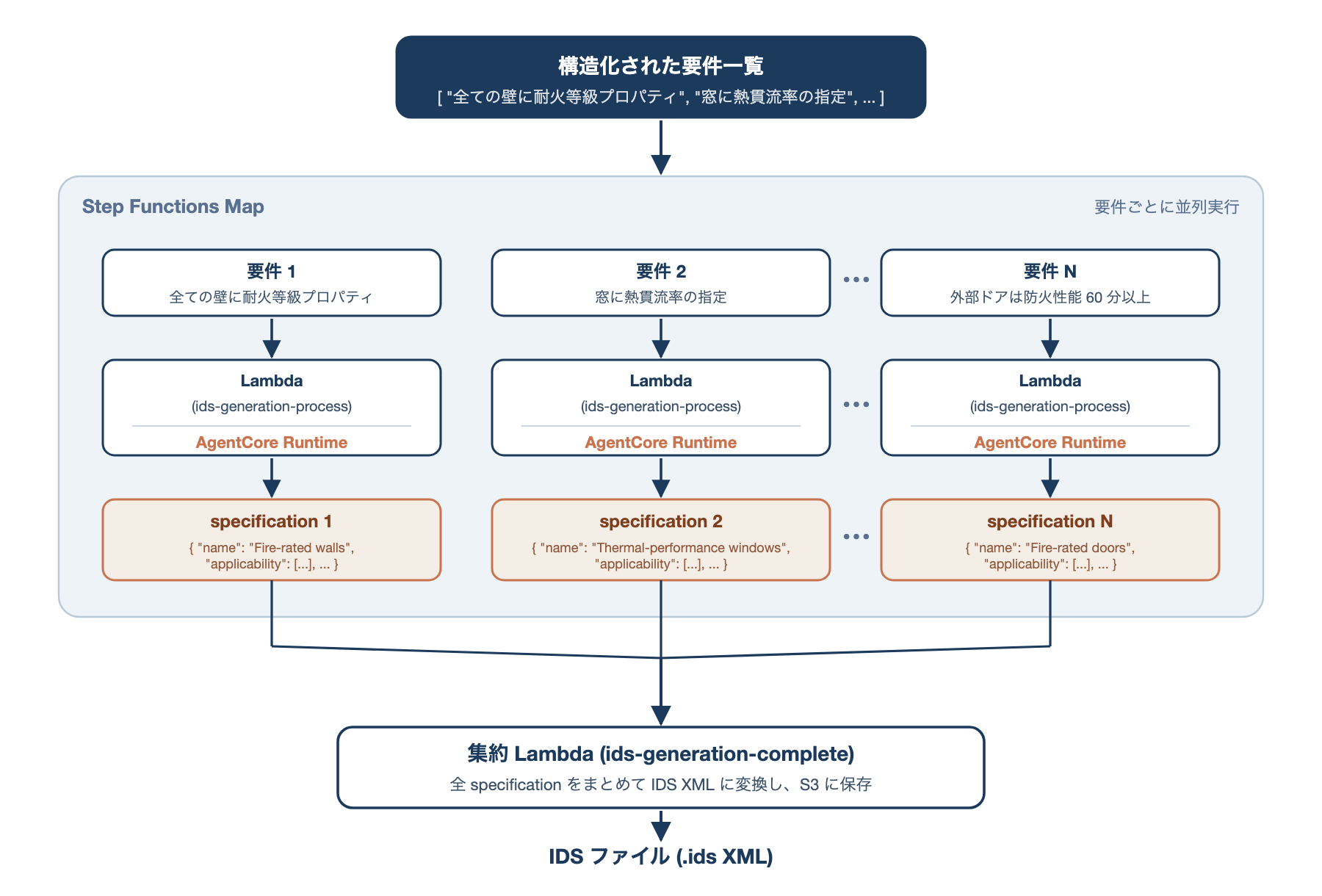
この並列化のポイントは 3 つあります。
- AgentCore Runtime が「セッション分離」を前提とした設計のため、並列呼び出しが安全: 各セッションが専用の microVM で動くため、状態が混ざる心配がない。Lambda でエージェントをホストする場合のように「同じインスタンスでの実行順序」を考慮する必要がない
- 個別要件の失敗が全体を止めない: Map 内の各要件の処理は独立しているため、1 件の要件が失敗しても残りの要件は処理が続く。失敗した要件は DB に error ステータスで記録され、ユーザーは後で個別に再実行できる
- リトライ戦略を Step Functions 側で完結させられる: AgentCore の一時的なスロットリングや Claude のタイムアウトは、Step Functions の自動リトライ(指数バックオフ)に任せられる。Lambda のコードに再試行ロジックを書く必要がない
これらの並列度・エラーハンドリング・リトライの設定は、すべて AWS CDK 上で宣言的に定義しています。Map ステートの並列処理を「アプリケーションのコードではなく、ワークフロー定義として外側に持てる」ことが、実装をシンプルに保つことに繋がっています。
4.5 動作イメージ
ここまでの仕組みを、実際の画面で一連の流れとして見てみます。
まず、要件定義書(PDF)をアップロードすると、生成 AI が内容を解釈し、要件を 1 件ずつ構造化して一覧に展開します。
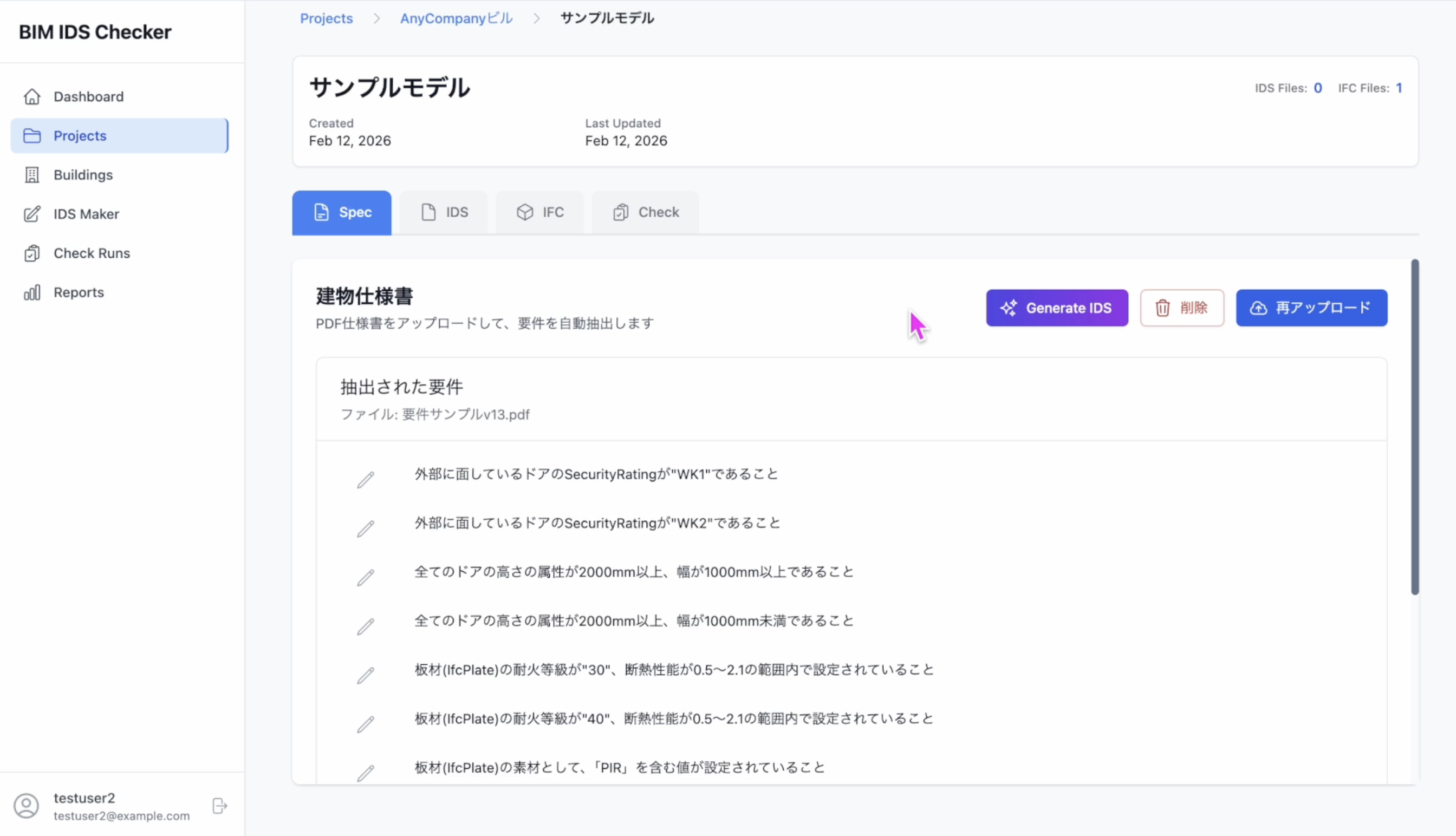
次に、構造化された要件のうち、IDS specification を生成する対象を選択します。
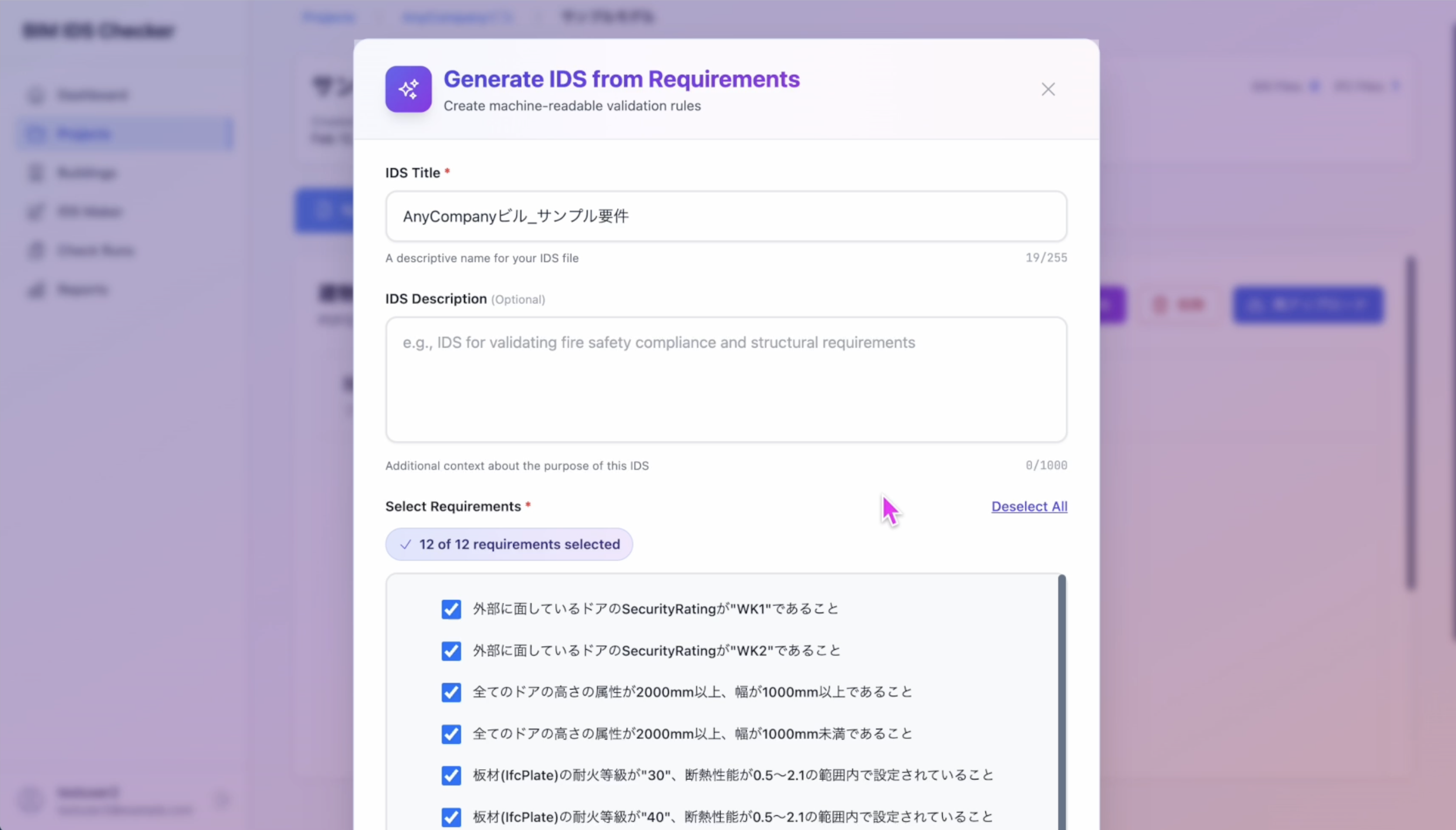
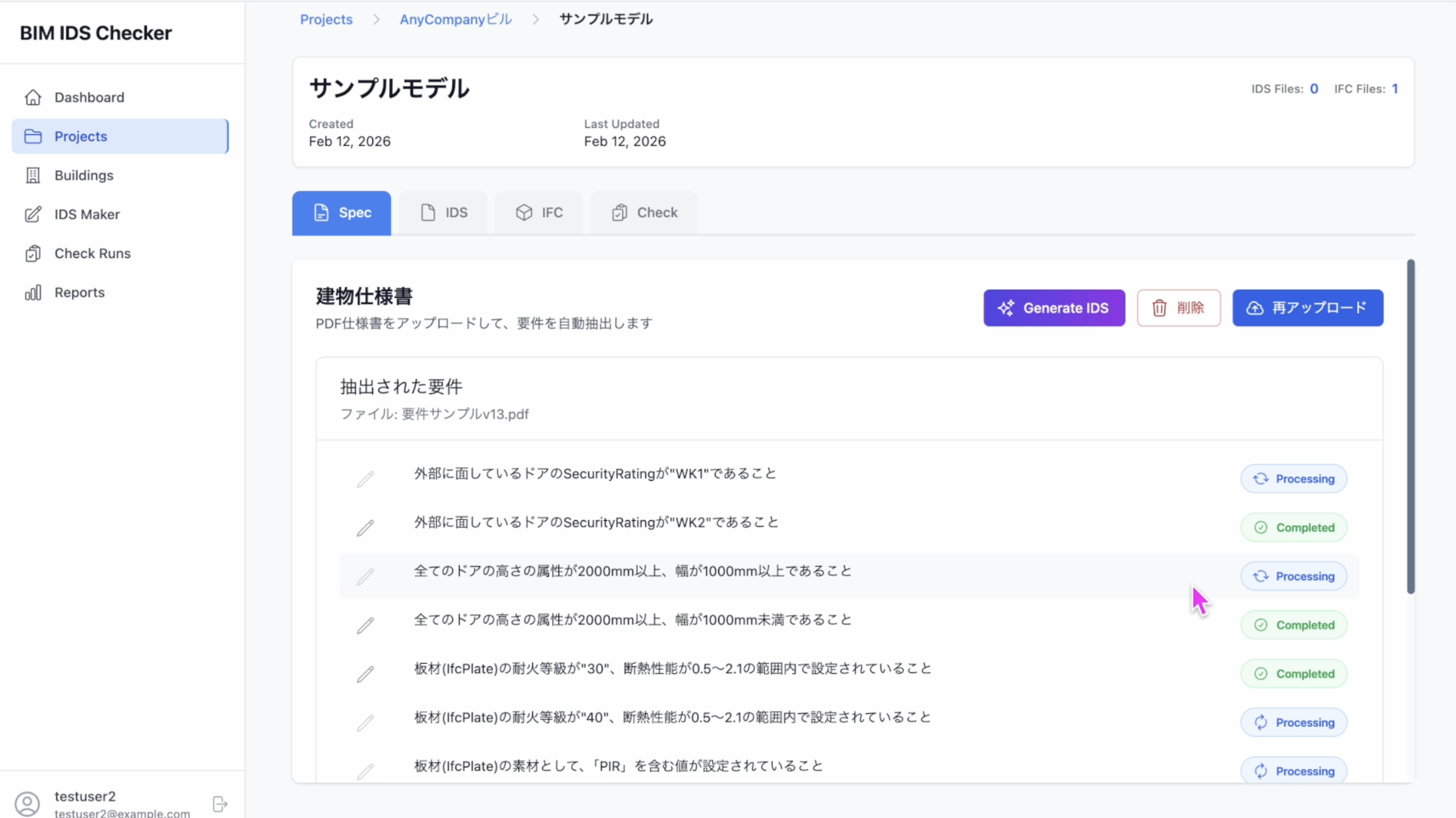
「生成」を実行すると、AgentCore Runtime により、選択した要件ごとに specification が並列で生成され、各要件の状況(処理中 / 完了など)がリアルタイムに更新されます。
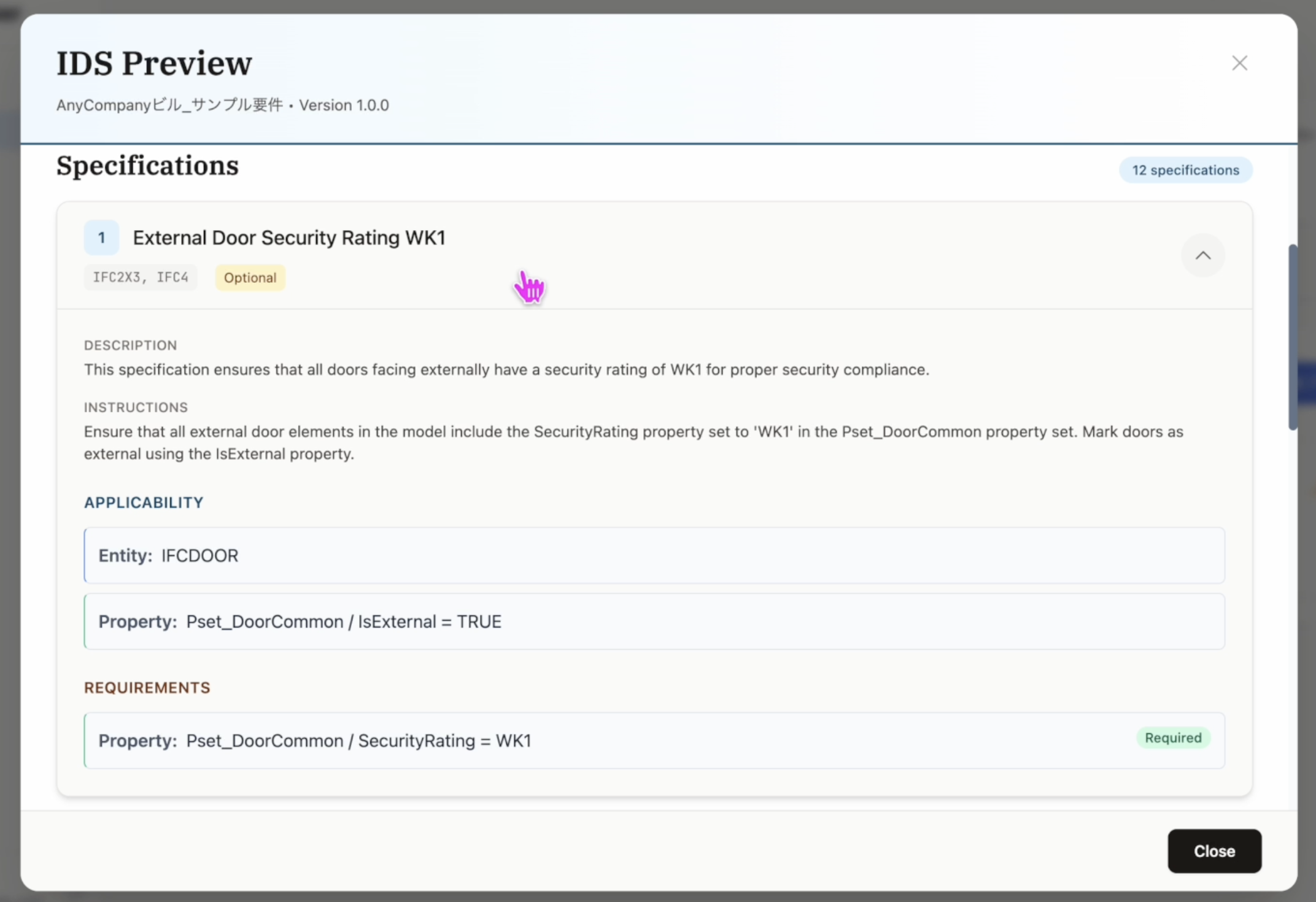
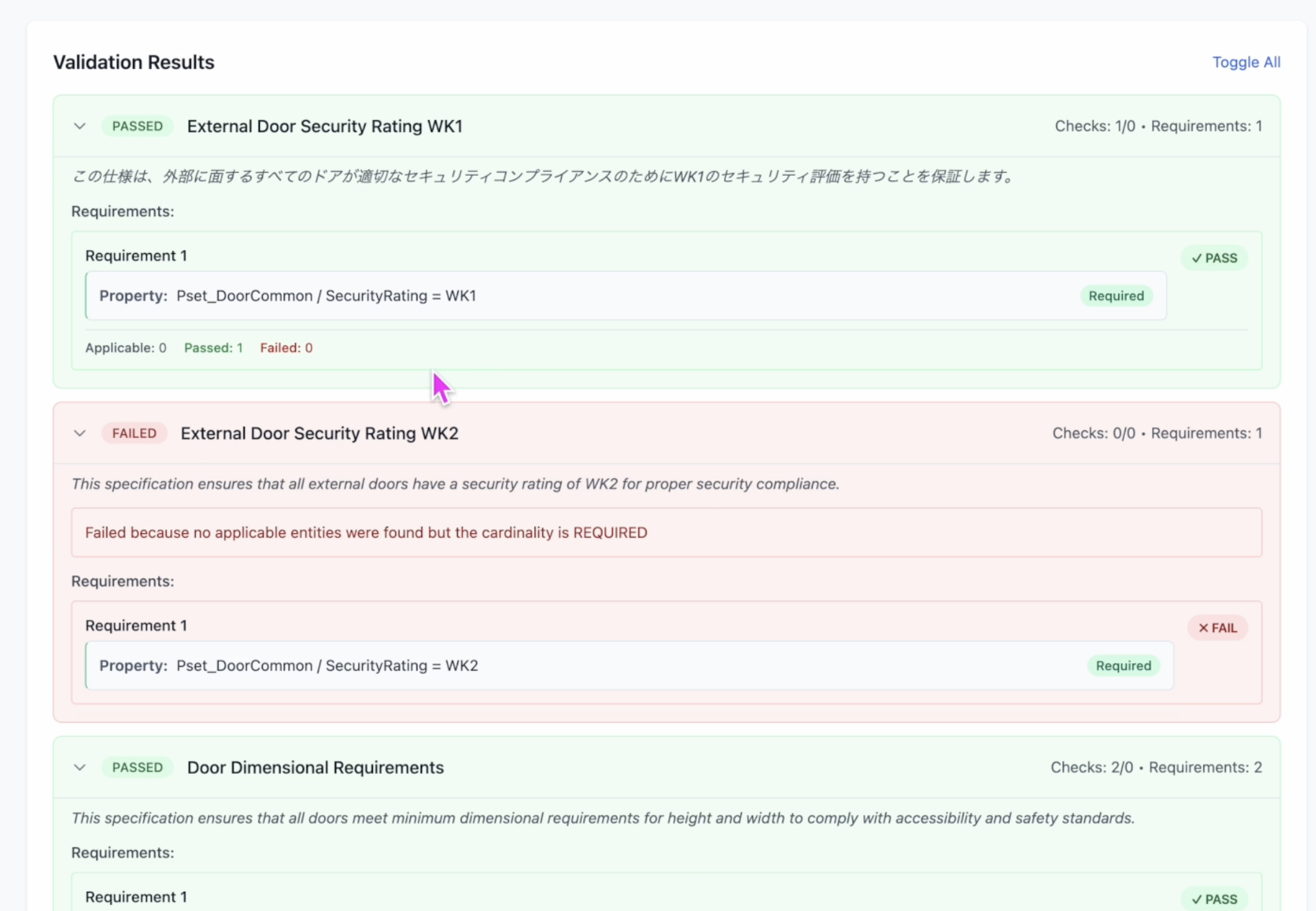
生成された specification は、要件ごとに内容を確認できます。
最後に、生成した IDS を使い、チェック対象の IFC ファイルが要件を満たしているかを検証します。本ソリューションでは、検証処理は AWS Batch 上で実行しています。
5. 考慮点: 条件分岐の多い要件への対応
本ブログで紹介したアプローチは、「全ての壁に耐火等級」「外部ドアは防火性能 60 分以上」といった、独立したルールが多数並ぶタイプの要件定義に有効です。一方で、用途・地域・構造などの組み合わせで要求内容が変わる、条件分岐が多い領域(たとえば建築基準法のような規定群)には、IDS の仕様上の制約から、そのままでは適用しづらい点があります。
理由は、IDS の設計思想にあります。IDS は「情報デリバリー仕様」という名前のとおり、「何が含まれているべき/いないべきか」を記述するのがスコープで、1 つの specification の中に if-then-else のような条件分岐を入れ込む機能は持ちません。条件によって要求が変わるルールは、条件の組み合わせごとに別々の specification として分割する必要があります。
チェックのスコープや内容によっては、様々な条件の組み合わせで要求内容が変わるため、これらを素朴に specification として展開すると、その数は膨大になります。本ブログのアプローチは個々の要件を IDS 化する部分を自動化しますが、こうした「条件分岐をどう整理して IDS に落とすか」という設計の問題は依然として残ります。分岐の多い領域へ適用を広げる際の検討課題と言えるでしょう。
6. まとめ
本ブログでは、BIM の要件定義を巡る課題と、それに対する国際標準 IDS の位置づけを整理した上で、「自然言語で書かれた要件定義書から IDS を自動生成する」 ソリューションを、実装レベルで解説しました。要点は次のとおりです。
- IDS は buildingSMART が 2024 年に v1.0 として承認した国際標準で、IFC ファイルに何が含まれているべきか/いないべきかを機械可読に定義する
- IDS 作成には IFC スキーマの専門知識が必要で、自然言語の要件定義からの変換は手作業では負担が大きい
- 課題の性質(要件が多い / 専門知識が要る / ミスが許されない)から、「並列処理」「専門知識ツールを持つ AI エージェント」「自己検証ループ」という 3 つの仕組みを組み合わせるアプローチを紹介
- 建築基準法のように条件分岐が多い領域には、IDS の仕様上、条件の組み合わせごとに specification を分割する必要があり、その整理が適用範囲を広げる際の検討課題となる
このアプローチの利点は、既存の要件定義資産(自然言語の Excel / PDF)をそのまま活用しながら、機械可読な IDS に変換できることです。本ブログでは IDS を題材にしましたが、同じ並列エージェントパターン(「自然言語の要件 → 構造化 → 要件ごとの並列 AI 処理 → 集約」)は、仕様書からのテストケース生成、要件定義からのチェックリスト生成など、大量の個別要件を AI で処理する場面に応用できます。