- AWS Builder Center
- builders.flash
AWS Lambda で動く、プロンプトライクな物体検出システム ~ RoomClip による生成 AI 実装解説
2024-10-03 | Author : 平山 知宏 (ルームクリップ株式会社)
builders.flash メールメンバー登録
概要
「十分に発達した科学技術は、魔法と見分けがつかない。」とアーサー・C・クラークは言い、「テクノロジーは自転車のようなもの」とスティーブ・ジョブズは言ったそうです。
まるで思春期のように成長する AI は、さながら「魔法のようなもの」になりつつある昨今ですが、「それに乗ってどこへ行くのか ?」という内なるジョブズの囁きもまた、無視できないわけです。
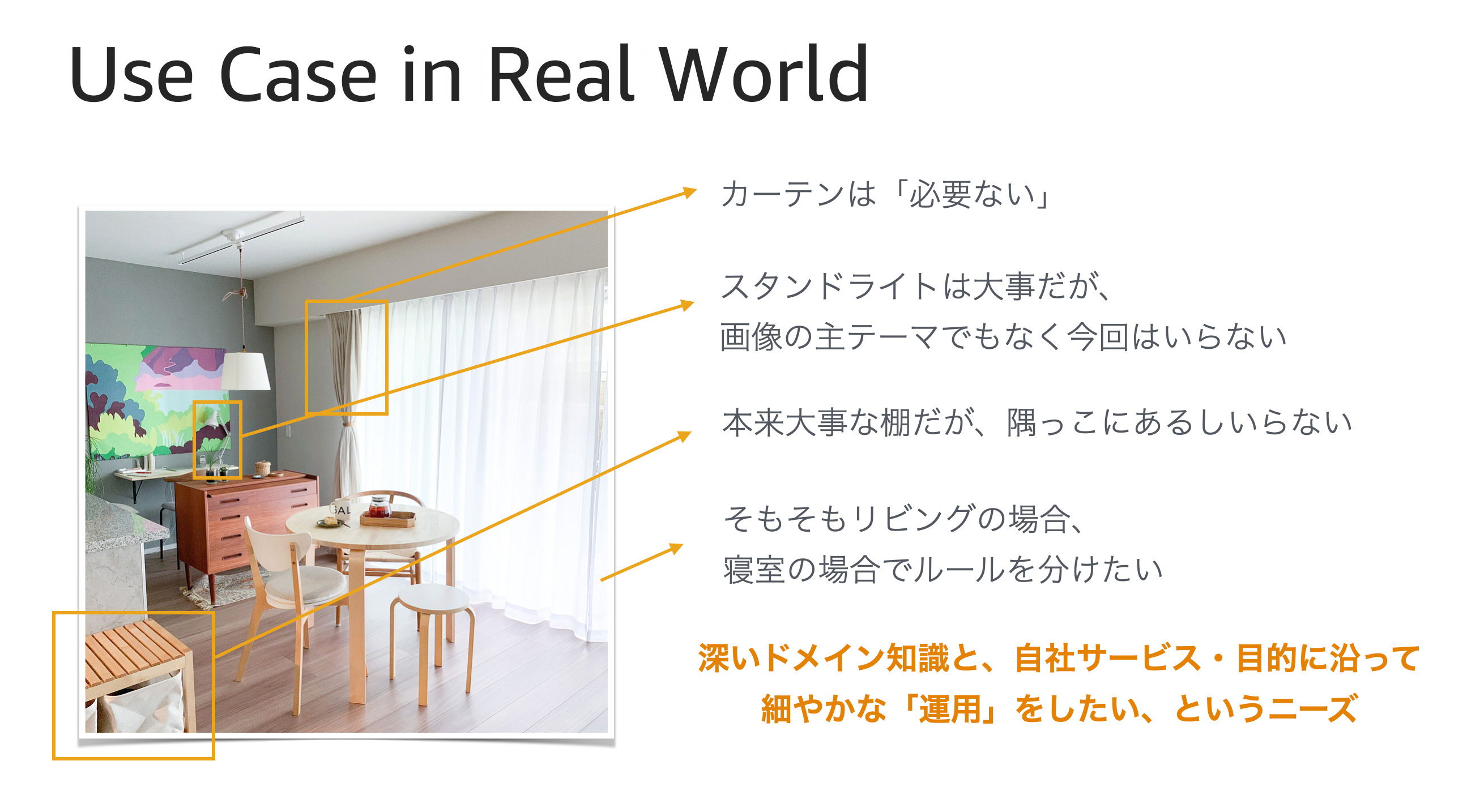
私たちが運営するサービス「RoomClip」では、日々大量に「部屋の画像」が投稿されています。その「部屋の画像」から「いい感じ」に物体を検出したい、という曖昧なくせにやたら強い意志が私たちにはありました。
YOLO などに代表される素晴らしい検出システムも検討しましたが、やはり、求める出力のためには「微調整」と「最適化」が必要になります。そのためには、無限に求められる教師データと、大量の計算ノードが必要な上に、それら試行錯誤のサイクル間隔は到底我慢できるものではありませんでした。
私たちのワガママは下記のような限界に達していたのです。
-
プロンプトライクで検出対象を柔軟に表現できること
-
検出矩形は正確な座標で取得できること
-
CPU で軽快に動くこと
この極まった要望の実現のため、ペダルの付いた魔法である SAM と CLIP を採用することにしました。
本題
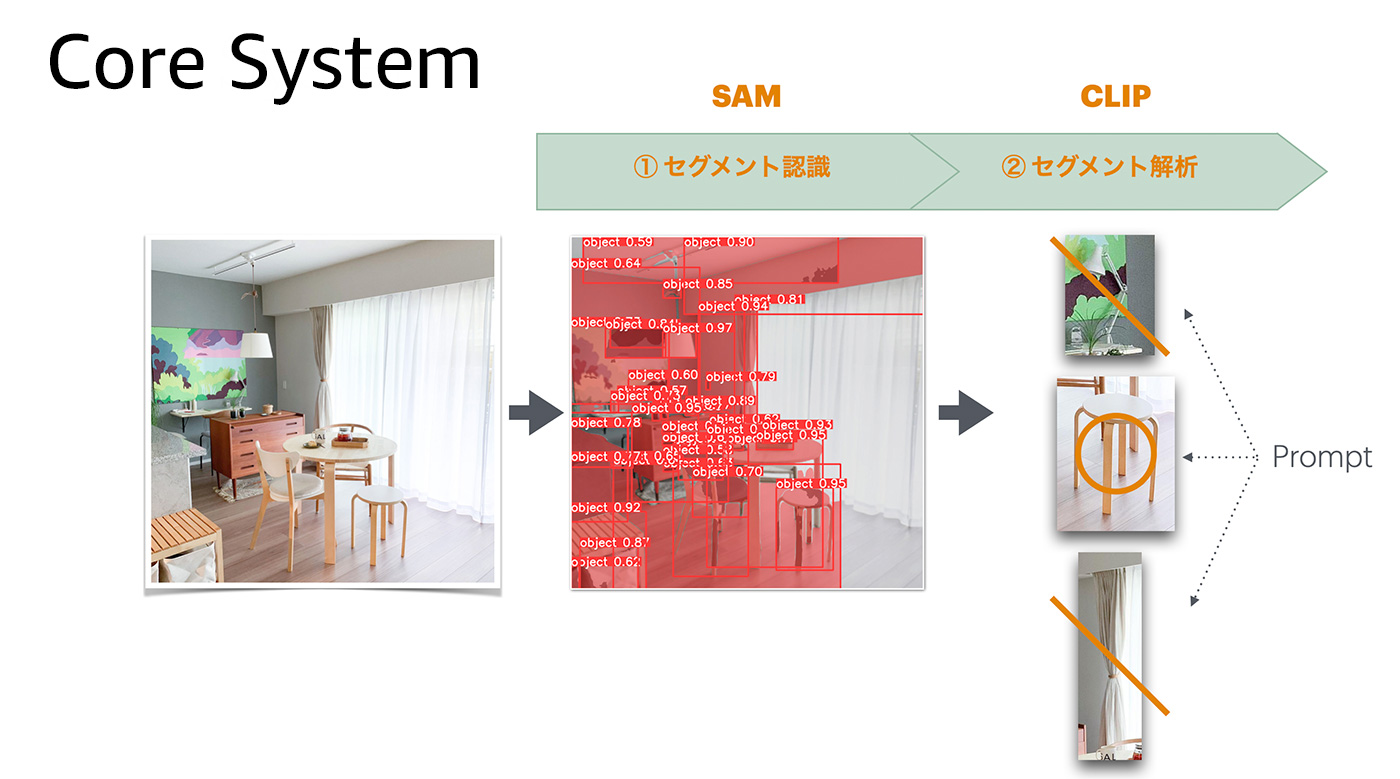
SAM は非常に優れたセグメンテーション技術です。私たちは「特になんの指示をすることもなく」、部屋画像の中から物体を切り出すことに成功しました。残った課題は、切り出された画像たちが、私たちの興味のあるものなのかどうか ? という問いでした。
その画像が何であるのか ? という QA モデルは現在進化の過程にあります。重武装したGPU で動く最新システムは日々リリースされていますが、私たちに必要だったのは軽量で、信頼感のある、手垢のついた、まるで歴戦の軽戦車のような CLIP モデルでした。
私たちは、SAM で切り出された多数の画像に対し、CLIP でプロンプト質問を投げる簡易なプロセスを試しに構築してみました。「ソファ」でも「椅子」でも「コーヒーメーカー」でも、およそ英語で表現できるものなら何でも分類してみました。
このコンビネーションは一撃で魔法のような成果をもたらしませんでしたが、十分な「調整」の余地を与えてくれました。SAM のパラメータを調整することで納得感のある画像の切り出しをテストし、CLIP のプロンプトを調整することで欲しいラベルの分類をテストする。以上の流れが、手元の CPU マシン (なんならコンテナ上) で、1 分もかからず終了するのです。「この魔法のハンドリングは確かに難しいが、乗り手のセンス次第でどこまでもいける。」内なるジョブズがニヤリと笑った瞬間でした。
システム全体は Python でできるだけコンパクトにしました。「切り出し画像を検索して、商品と結びつける」ような工夫を添えても、一連の動作はコンテナ上の 1 プロセスで完了するシンプルさもあります。
そして重要な関心事は「パラメータの調整」や「フィルタの条件」そして「プロンプトの調整」だけに絞り込むことができます。私はこの調整群を yml にとりまとめ、それら一群を「モデル」と呼びました。本当の生成モデルではなく、単なる yml の集合をモデルと指すことに、もはやためらいはありませんでした。
livingroom.yml
(サンプル)
specify:
recognize:
CLIP:
# ネガティブな認識
negative_categories:
- !include ./categories/tv.yml
- !include ./categories/tire.yml
- !include ./categories/pc.yml
# 画像認識のカテゴリ
categories:
-
- !include ./categories/desk.yml
- !include ./categories/chair.yml
- !include ./categories/table.yml
- !include ./categories/coffee_maker.yml./categories/coffee_maker.yml
(livingroom が参照する特定のクラスのサンプル)
{
label: "coffee_maker",
text: "This photos shows a home coffee appliance designed for brewing various types of coffee, including espresso.",
min_score: 0.7,
threshold: 0.7,
parent_genre: ["家電"]
}常に自由なモデルを開発可能
開発者は常に自由なモデルを開発できます。なぜならいくつかの yml ファイルを作成し、それらを格納するディレクトリを切るだけで、全く別の意図に対応する検出システムになるからです。例に示したように、livingroom.yml は tv,tire,pc を拒絶し、desk,chair,table を認識します。もし仮に「コーヒーメーカーもお願い!」と言われたとしても、coffe_maker.yml にあるような英文を用意して組み込むだけで、分類クラスは拡張されるのです。私の実装した main.py はそれら yml にしたがって、SAM を起動し、CLIP に明け渡すだけです。
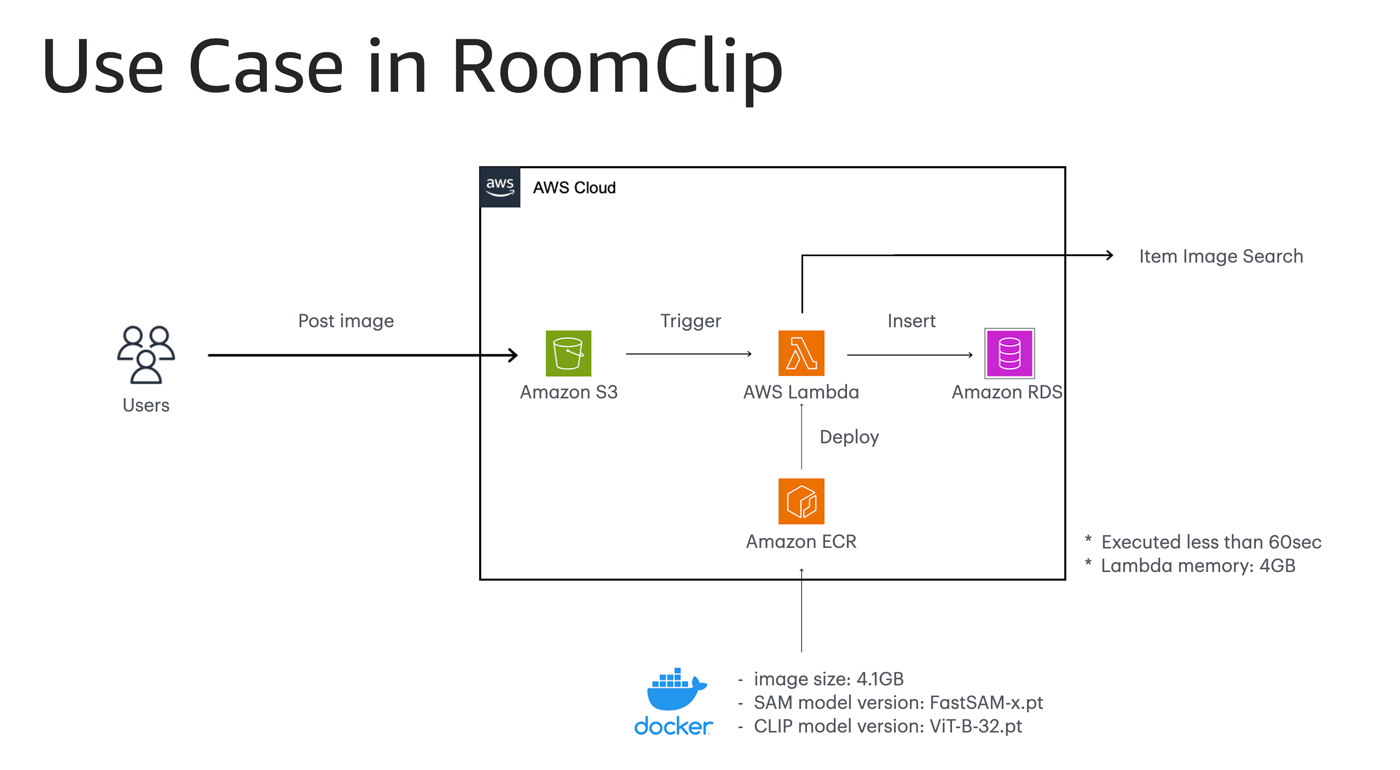
python スクリプトを、AWS Lambda ワークフローにデプロイ
私は最初のモデル=単なる yml ファイルを搭載した python スクリプトを、非常に簡易な AWS Lambda ワークフローにデプロイしました。誰しもが一度は実装したことがありそうな、何の変哲もない Amazon S3 トリガーの Lambda コンテナです。内心「無理かも」と思っていたのですが、わずか 1 分の後に、たったメモリ 4 GB の Lambda マシンが私の不安をかき消しました。
まとめ
SAM や CLIP といった CPU 動作する画像系の AI モデルのユースケースとして、RoomClip の物体検出システムの紹介をしました。
CLIP プロンプトを中心に画像ラベリングをしつつ、前処理として対象画像の矩形選択は SAM で行う、という実装となります。細やかな調整が必要なため、性能は直ちに発揮されませんが、Lambda でも軽快に動作するところが大きな特徴となります。
執筆現在は、手広く汎用な検出モデルだけでなく、例えば洗面所や玄関にだけに特化したものなど、様々な調整を施したモデル (= yml ファイル群) を作り検証しています。実際のところ、いうほど上手くいかないケースもたくさんあります。しかし、部屋画像に表れる「ユーザーさんの日々の創造的な営み」に、私たち IT エンジニアの知恵と工夫が応えられるように、日々精進してまいります。
筆者プロフィール
平山 知宏 (ひらやま ともひろ)
ルームクリップ株式会社 CTO
2012 年創業時より参画し、ローンチ初期より AWS を利用。好きな AWS サービスは Amazon EC2 だが、最近はあまり使えなくて悲しい。最近はグラフデータベースの Amazon Neptune に興味を持ち始めている。意外とこいつやるな、と思う言語は awk。

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages