Amazon Web Services 한국 블로그
Amazon Redshift Serverless – 추가 신규 기능과 함께 정식 출시 (서울 리전 포함)
작년 re:Invent에서는 Amazon Redshift Serverless 평가판이 출시되었습니다. 이 서비스는 Amazon Redshift의 서버리스 옵션으로, 데이터 웨어하우스 인프라를 관리하지 않고도 모든 규모의 데이터를 분석할 수 있습니다. 데이터를 로드 및 쿼리하고 사용한 만큼만 요금을 지불하면 됩니다.
이를 통해 더 많은 기업이 현대적 데이터 전략을 구축할 수 있게 됩니다. 특히, 분석 워크로드를 상시 실행하지 않고 데이터 웨어하우스가 상시 활성 상태가 아닌 사용 사례에 유용합니다. 또한, 조직 내에서 데이터 사용을 확대하고 새로운 부서의 사용자들이 데이터 웨어하우스 인프라를 관리하지 않고도 분석을 수행하고자 하는 기업에서도 활용할 수 있습니다.
오늘은 Amazon Redshift Serverless가 여러 가지 새로운 기능을 추가하여 정식 출시되었다는 소식을 알려드리고자 합니다. Redshift Serverless의 컴퓨팅 비용도 평가판에 비해 낮추었습니다.
이제 네임스페이스와 워크그룹을 사용하여 AWS 계정 및 리전당 여러 개의 서버리스 엔드포인트를 생성할 수 있습니다.
- 네임스페이스(namespace)는 데이터베이스 이름과 암호, 권한, 암호화 구성과 같은 데이터베이스 개체 및 사용자 모음입니다. 여기에서 데이터를 관리하고, 스토리지 사용량을 확인할 수 있습니다.
- 워크그룹(workgroup)은 네트워크 및 보안 설정을 비롯한 컴퓨팅 리소스 모음입니다. 각 워크그룹에는 애플리케이션을 연결할 수 있는 서버리스 엔드포인트가 있습니다. 워크그룹을 구성할 때 비공개 엔드포인트를 설정하거나 공개적으로 액세스 가능한 엔드포인트를 설정할 수 있습니다.
각 네임스페이스는 연결된 워크그룹을 하나만 가질 수 있습니다. 다시 말해, 각 워크그룹은 하나의 네임스페이스와만 연결할 수 있습니다. 워크그룹이 연결되지 않은 네임스페이스도 있을 수 있습니다. 예를 들어, 이 네임스페이스는 동일하거나 서로 다른 AWS 계정 또는 리전에서 다른 네임스페이스와 데이터를 공유하는 데만 사용합니다.
워크그룹 구성에서 쿼리 모니터링 규칙을 사용하면 비용을 관리하는 데 도움이 됩니다. 또한, Amazon Redshift Serverless는 더욱 지능적인 방식으로 데이터 웨어하우스 용량을 자동으로 확장하므로 부하가 크고 예측이 어려운 워크로드에 빠른 성능을 제공합니다.
간단한 데모를 통해 작동 원리를 살펴보겠습니다. 그런 다음, 네임스페이스와 워크그룹에 어떤 기능이 있는지 보여드리겠습니다.
Amazon Redshift Serverless 사용
Amazon Redshift 콘솔의 탐색 창에서 Redshift Serverless를 선택합니다. 먼저 기본 설정 사용하기(Use default settings)를 선택하여 가장 일반적인 옵션으로 네임스페이스와 워크그룹을 구성하겠습니다. 예를 들어 기본 VPC(default VPC) 및 기본 보안 그룹(default security group)을 사용하여 연결할 수 있습니다.

기본 설정을 적용하고 나면 이제 권한(Permissions)만 구성하면 됩니다. 여기에서는 Amazon Redshift가 다른 서비스(예: S3, Amazon CloudWatch Logs, Amazon SageMaker, AWS Glue)와 상호작용하는 방식을 지정할 수 있습니다. 나중에 데이터를 로드하기 위해 Amazon Redshift에 S3 버킷에 대한 액세스 권한을 부여하겠습니다. IAM 역할 관리(Manage IAM roles)를 선택한 다음, IAM 역할 생성(Create IAM role)을 선택합니다.
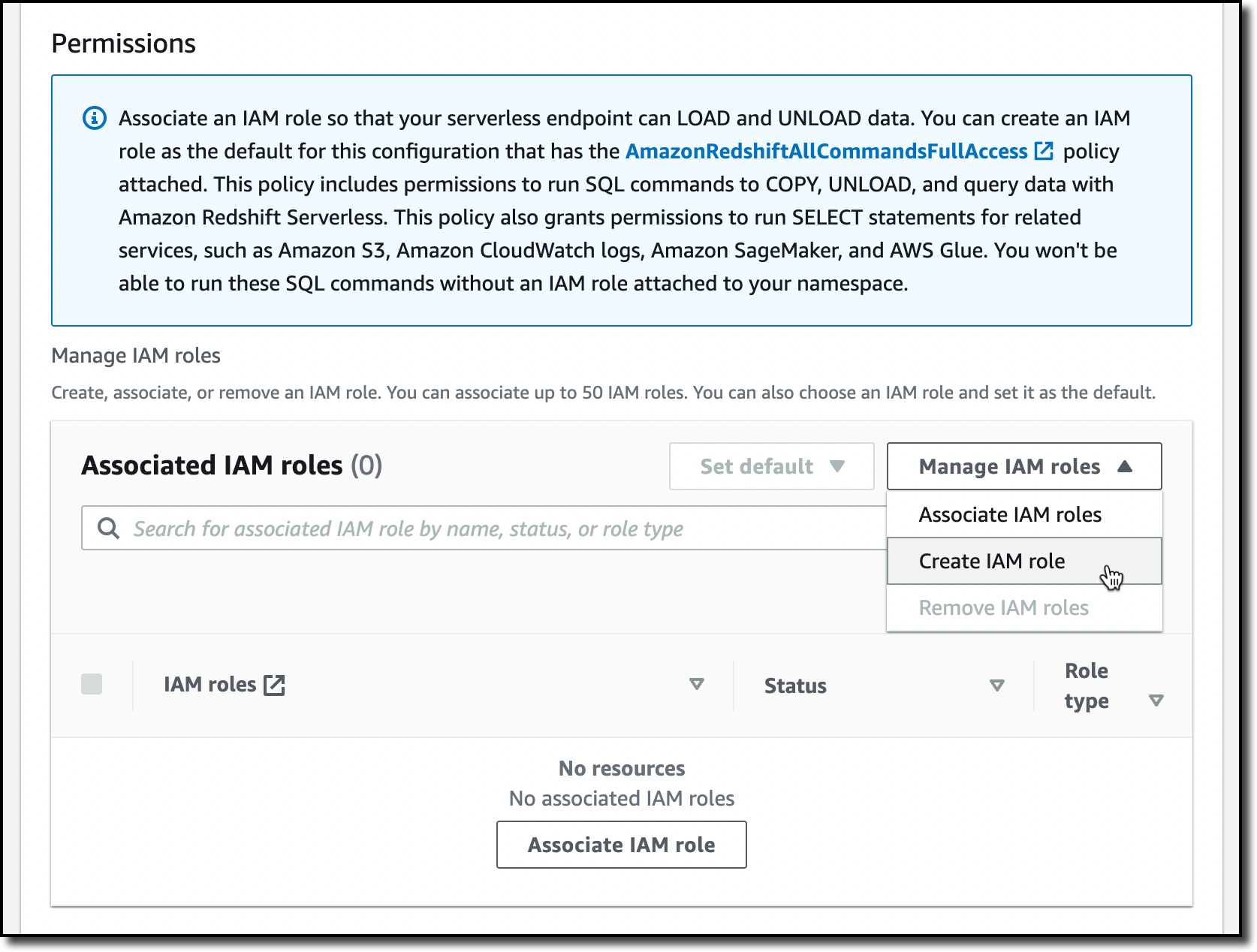
IAM 역할을 생성할 때 특정 S3 버킷(pecific S3 buckets)에 액세스 권한을 부여하는 옵션을 선택하고, 동일한 AWS 리전에 있는 S3 버킷을 선택합니다. 그런 다음, IAM 역할을 기본값으로 생성(Create IAM role as default)을 선택하여 역할 생성 단계를 완료하고 네임스페이스의 기본 역할에 자동으로 사용하도록 합니다.

구성 저장(Save configuration)을 선택한 후 몇 분이 지나면 데이터베이스를 사용할 수 있습니다. 서버리스 대시보드(Serverless dashboard)에서 쿼리 데이터(Query data)를 사용하여 Redshift 쿼리 편집기 v2(Redshift query editor v2)를 엽니다. 여기에서 Amazon Redshift 데이터베이스 개발자 안내서의 지침에 따라 샘플 데이터베이스를 로드합니다. 간단하게 테스트를 실행하려면 sample_data_dev 데이터베이스에 이미 준비되어 있는 몇 가지 샘플 데이터베이스를 활용하세요(저도 샘플 데이터베이스를 사용했습니다). 또한, 쿼리를 실행할 때는 Amazon Redshift로 데이터를 로드할 필요가 없습니다. 외부 스키마와 외부 테이블을 생성하는 방법으로 S3 데이터 레이크의 데이터를 쿼리에 사용할 수 있습니다.
샘플 데이터베이스는 7개의 테이블로 구성되며, 사용자가 스포츠 행사, 공연, 콘서트 티켓을 사고파는 가상의 ‘TICKIT’ 웹사이트의 판매 활동을 추적합니다.
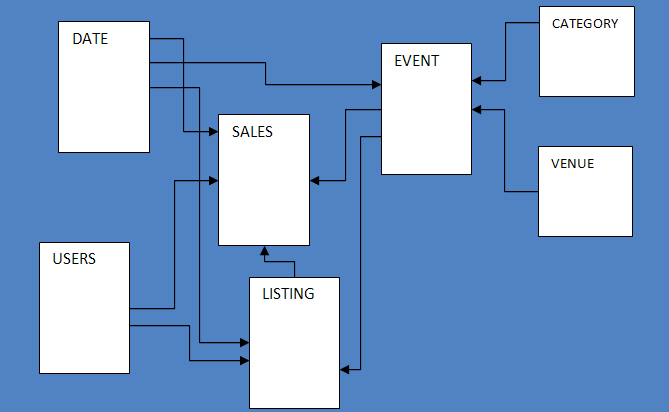
데이터베이스 스키마를 구성하기 위해 몇 가지 SQL 명령을 실행하여 users, venue, category, date, event, listing, sales 테이블을 생성합니다.

그런 다음, 데이터베이스 테이블의 샘플 데이터가 포함된 tickitdb.zip 파일을 다운로드합니다. 압축을 해제하고 IAM 역할을 구성할 때 사용했던 것과 동일한 S3 버킷의 tickit 폴더로 파일을 로드합니다.
이제 COPY 명령을 사용하여 S3 버킷의 데이터를 데이터베이스로 로드할 수 있습니다. 예를 들어 users 테이블로 데이터를 로드해 보겠습니다.
copy users from 's3://MYBUCKET/tickit/allusers_pipe.txt' iam_role default;
sales 테이블의 데이터가 포함된 파일은 탭으로 구분된 값을 사용합니다.
copy sales from 's3://MYBUCKET/tickit/sales_tab.txt' iam_role default delimiter '\t' timeformat 'MM/DD/YYYY HH:MI:SS';모든 테이블로 데이터를 로드하고 나면 몇 가지 쿼리를 실행하기 시작합니다. 예를 들어, 다음 쿼리는 테이블 5개를 조인하여 캘리포니아에서 개최되는 이벤트에 대한 상위 5위 판매자를 찾습니다(샘플 데이터는 2008년 데이터입니다).
select sellerid, username, (firstname ||' '|| lastname) as sellername, venuestate, sum(qtysold)
from sales, date, users, event, venue
where sales.sellerid = users.userid
and sales.dateid = date.dateid
and sales.eventid = event.eventid
and event.venueid = venue.venueid
and year = 2008
and venuestate = 'CA'
group by sellerid, username, sellername, venuestate
order by 5 desc
limit 5;
이제 데이터베이스가 준비되었으므로 Amazon Redshift Serverless 네임스페이스와 워크그룹을 구성하여 어떤 기능을 사용할 수 있는지 알아보겠습니다.
네임스페이스 사용 및 구성
네임스페이스는 데이터베이스 데이터와 보안 구성의 모음입니다. Amazon Redshift 콘솔 창에서 네임스페이스 구성(Namespace configuration)을 선택합니다. 목록에서 방금 생성한 기본 네임스페이스를 선택합니다.
데이터 백업(Data backup) 탭에서는 스냅샷을 생성/복구하거나, 30분마다 자동 생성되어 24시간 유지되는 복구 지점 중 하나에서 데이터를 복구할 수도 있습니다. 이 기능은 실수로 데이터를 작성하거나 삭제한 경우에 데이터를 복구하는 데 유용합니다.

보안 및 암호화(Security and encryption) 탭에서는 리소스를 암호화 및 복호화하는 데 사용한 AWS Key Management Service(AWS KMS) 키를 포함한 권한 및 암호화 설정을 업데이트할 수 있습니다. 이 탭에서는 감사 로깅을 활성화하고 사용자, 연결, 사용자 활동 로그를 내보낼 수도 있습니다. [[ 로그는 어디로 내보내질까요? CloudWatch Logs일까요? 콘솔에는 명확히 나와 있지 않습니다. ]]

Datashares(데이터 공유) 탭에서는 동일하거나 서로 다른 리전에 있는 다른 네임스페이스 및 AWS 계정과 데이터를 공유하기 위한 데이터 공유를 생성할 수 있습니다. 또한, 다른 네임스페이스나 AWS 계정에서 받은 공유로부터 데이터베이스를 생성할 수도 있고 AWS Data Exchange에서 관리하는 데이터 공유에 대한 구독을 확인할 수도 있습니다.

데이터 공유를 생성할 때 여기에 포함할 개체를 선택할 수 있습니다. 예를 들어 저는 민감한 데이터가 포함되지 않은 date 및 event 테이블만 이 데모에 공유하고자 합니다.

워크그룹 사용 및 구성
워크그룹은 컴퓨팅 리소스와 그에 대한 네트워크 및 보안 설정의 모음입니다. 워크그룹은 구성된 네임스페이스에 대한 서버리스 엔드포인트를 제공합니다. Amazon Redshift 콘솔의 탐색 창에서 워크그룹 구성(Workgroup configuration)을 선택합니다. 목록에서 방금 생성한 기본 네임스페이스를 선택합니다.
데이터 액세스(Data access) 탭에서는 네트워크 및 보안 설정(예: VPC, 서브넷, 보안 그룹 변경)을 업데이트하거나 엔드포인트에 공개적으로 액세스하도록 설정할 수 있습니다. 또한 여기에서 향상된 VPC 라우팅(Enhanced VPC routing)을 활성화하면 서버리스 데이터베이스와 사용 중인 데이터 리포지토리(예: 데이터를 로드하거나 언로드하는 데 사용한 S3 버킷) 사이의 네트워크 트래픽을 인터넷 대신 VPC를 통해 라우팅할 수도 있습니다. 다른 VPC나 서브넷에 있는 서버리스 엔드포인트에 액세스하려면 Amazon Redshift에서 관리하는 VPC 엔드포인트(VPC endpoint)를 생성합니다.

제한(Limits) 탭에서는 쿼리를 처리하는 데 사용하는 기본 용량(Redshift 처리 장치 또는 RPU 단위로 표시)을 구성할 수 있습니다. Amazon Redshift Serverless는 사용자 수가 늘어나면 이를 처리하기 위해 용량을 확장합니다. 쿼리 속도를 높이기 위해 기본 용량을 높이거나, 비용을 절감하기 위해 기본 용량을 낮추는 옵션도 있습니다.
이 탭에서는 사용 제한(Usage limits)을 설정하여 하루, 주간, 월간 임계값을 구성하여 비용을 예측 가능하게 관리할 수도 있습니다. 예를 들어 저는 컴퓨팅 리소스의 일일 제한은 200 RPU-시간으로, 월간 제한은 2,000 RPU-시간으로 구성했습니다. 리전 간 데이터 공유 시 데이터 전송 비용을 제어하기 위해 일일 제한은 3TB로, 주간 제한은 10TB로 구성했습니다. 마지막으로 각 쿼리에서 사용하는 리소스를 제한하기 위해 쿼리 제한(Query limits)을 사용하여 쿼리 실행 시간은 60초 이내로 설정했습니다.

가용성 및 요금
현재 Amazon Redshift Serverless는 미국 동부(오하이오), 미국 동부(버지니아 북부), 미국 동부(오레곤), 유럽(프랑크푸르트), 유럽(아일랜드), 유럽(런던), 유럽(스톡홀름), 아시아 태평양(서울), 아시아 태평양(싱가포르), 아시아 태평양(시드니), 아시아 태평양(도쿄) AWS 리전에서 정식으로 이용할 수 있습니다.
JDBC/ODBC를 통해 자주 사용하는 클라이언트 도구를 사용하여 워크그룹 엔드포인트에 연결하거나, Amazon Redshift 쿼리 편집기 v2(Amazon Redshift 콘솔에서 제공하는 웹 기반 클라이언트 애플리케이션)로 연결할 수 있습니다. 웹 서비스 기반 애플리케이션(예: AWS Lambda 함수, Amazon SageMaker 노트북)을 사용할 경우, 기본으로 제공하는 Amazon Redshift Data API로 데이터베이스에 액세스하고 쿼리를 수행할 수 있습니다.
Amazon Redshift Serverless는 데이터베이스가 활성화된 상태에서 사용하는 컴퓨팅 용량에 대해서만 요금을 지불합니다. 컴퓨팅 용량은 워크로드에 따라 자동으로 확장되거나 축소되며, 비활성 상태일 때는 종료되므로 시간과 비용이 절약됩니다. 데이터는 관리형 스토리지에 저장되고, 사용한 용량(GB)에 따라 월 요금을 지불합니다.
더욱 폭넓은 사용 사례에 Amazon Redshift Serverless를 유연하게 사용할 수 있도록 지원하고 가격 대비 성능을 높이기 위해, 미국 동부(버지니아 북부) 리전의 RPU-시간당 요금을 0.5 USD에서 0.375 USD로 인하합니다. 마찬가지로, 다른 리전의 요금도 이전 요금 대비 평균 25% 인하 중입니다. 자세한 내용은 Amazon Redshift 요금 페이지를 참조하세요.
Amazon Redshift Serverless에 자신의 사용 사례에 적용하는 데 도움을 드리기 위해 AWS Credit 300 USD를 90일 동안 제공합니다. 이 크레딧은 Amazon Redshift Serverless의 컴퓨팅, 스토리지 및 스냅샷 사용 비용을 충당하는 데만 사용됩니다.
Amazon Redshift Serverless를 사용하면 몇 초 만에 데이터에서 인사이트를 얻을 수 있습니다.
— Danilo