Amazon Web Services 한국 블로그
Amazon S3 Tables, 계정 및 리전간 복제 지원 및 지능형 계층화 출시
오늘 Amazon S3 Tables에 대한 두 가지 새로운 기능을 발표합니다. 액세스 패턴에 따라 비용을 자동으로 최적화하는 새로운 Intelligent-Tiering 스토리지 클래스 지원과 수동 동기화 없이 AWS 리전 및 계정 전체에서 일관된 Apache Iceberg 테이블 복제본을 자동으로 유지 관리하는 복제 지원입니다.
테이블 형식 데이터를 사용하는 조직은 두 가지 공통적인 과제에 직면합니다. 첫째, 데이터세트가 증가하고 시간이 지남에 따라 액세스 패턴이 변함에 따라 스토리지 비용을 수동으로 관리해야 합니다. 둘째, 리전이나 계정에 걸쳐 Iceberg 테이블의 복제본을 유지 관리하는 경우 업데이트를 추적하고, 객체 복제를 관리하고, 메타데이터 변환을 처리하기 위해 복잡한 아키텍처를 구축하고 유지 관리해야 합니다.
S3 Tables Intelligent-Tiering 스토리지 클래스
S3 Tables Intelligent-Tiering 스토리지 클래스를 사용하면 데이터가 액세스 패턴에 따라 가장 비용 효율적인 액세스 계층으로 자동 계층화됩니다. 데이터는 지연 시간이 짧은 세 가지 계층인 Frequent Access, Infrequent Access(Frequent Access보다 40% 저렴), Archive Instant Access(Infrequent Access보다 68% 저렴)에 저장됩니다. 액세스하지 않은 지 30일이 지나면 데이터는 Infrequent Access로 이동하고, 90일이 지나면 Archive Instant Access로 이동합니다. 이 과정은 애플리케이션 변경이나 성능 저하 없이 진행됩니다.
압축, 스냅샷 만료, 참조되지 않은 파일 제거를 비롯한 테이블 유지 관리 작업은 데이터 액세스 계층에 영향을 주지 않고 작동합니다. 압축은 빈번한 액세스 계층의 데이터만 자동으로 처리하여 적극적으로 쿼리되는 데이터의 성능을 최적화하는 동시에 비용이 낮은 계층의 오랫동안 사용되지 않은 파일을 건너뛰어 유지 관리 비용을 절감합니다.
기본적으로 모든 기존 테이블은 표준 스토리지 클래스를 사용합니다. 새 테이블을 생성할 때 Intelligent-Tiering을 스토리지 클래스로 지정하거나 테이블 버킷 수준에서 구성된 기본 스토리지 클래스를 사용할 수 있습니다. 테이블 버킷의 기본 스토리지 클래스로 Intelligent Tiering을 설정하면 테이블 생성 시 스토리지 클래스를 지정하지 않은 경우 테이블이 Intelligent Tiering에 자동으로 저장됩니다.
작동 방식 보기
AWS Command Line Interface(AWS CLI)와 put-table-bucket-storage-class 및 get-table-bucket-storage-class 명령을 사용하여 S3 테이블 버킷의 스토리지 계층을 변경하거나 확인할 수 있습니다.
# Change the storage class
aws s3tables put-table-bucket-storage-class \
--table-bucket-arn $TABLE_BUCKET_ARN \
--storage-class-configuration storageClass=INTELLIGENT_TIERING
# Verify the storage class
aws s3tables get-table-bucket-storage-class \
--table-bucket-arn $TABLE_BUCKET_ARN \
{ "storageClassConfiguration":
{
"storageClass": "INTELLIGENT_TIERING"
}
}S3 Tables 복제 지원
새로운 S3 테이블 복제 지원을 통해 AWS 리전 및 계정 전반에서 테이블의 일관된 읽기 전용 복제본을 유지할 수 있습니다. 대상 테이블 버킷을 지정하면 서비스가 읽기 전용 복제본 테이블을 생성합니다. 상위-하위 스냅샷 관계를 유지하면서 모든 업데이트를 시간순으로 복제합니다. 테이블 복제를 통해 지리적으로 분산된 팀의 쿼리 지연 시간을 최소화하고, 규정 준수 요구 사항을 충족하며, 데이터 보호를 제공하는 글로벌 데이터세트를 구축할 수 있습니다.
이제 소스 테이블과 유사한 쿼리 성능을 제공하는 복제본 테이블을 쉽게 생성할 수 있습니다. 복제본 테이블은 소스 테이블 업데이트 후 몇 분 이내에 업데이트되며, 소스 테이블과 독립적인 암호화 및 보존 정책을 지원합니다. 복제본 테이블은 Amazon SageMaker Unified Studio 또는 DuckDB, PyIceberg, Apache Spark, Trino를 비롯한 Iceberg 호환 엔진을 사용하여 쿼리할 수 있습니다.
AWS Management Console 또는 API 및 AWS SDK를 통해 테이블 복제본을 생성하고 유지할 수 있습니다. 소스 테이블을 복제할 하나 이상의 대상 테이블 버킷을 지정합니다. 복제를 켜면 S3 Tables가 대상 테이블 버킷에 읽기 전용 복제 테이블을 자동으로 생성하고, 소스 테이블의 최신 상태로 다시 채우고, 새로운 업데이트를 지속적으로 모니터링하여 복제본을 동기화합니다. 이를 통해 여러 데이터 복제본을 유지하면서 시간 이동 및 감사 요구 사항을 충족할 수 있습니다.
작동 방식 보기
어떻게 작동하는지 보여주기 위해 세 단계로 진행하겠습니다. 첫 번째로 S3 테이블 버킷을 생성하고, Iceberg 테이블을 생성한 후 데이터를 채웁니다. 두 번째로 복제를 구성합니다. 세 번째로 복제된 테이블에 연결하고 데이터를 쿼리하여 변경 사항이 복제되었음을 보여줍니다.
이 데모에서는 S3 팀이 이미 프로비저닝된 Amazon EMR 클러스터에 대한 액세스를 친절하게 제공해 주었습니다. Amazon EMR 설명서를 따라 자체 클러스터를 생성할 수 있습니다. 또한 복제를 위한 소스와 대상, 두 개의 S3 테이블 버킷을 생성했습니다. 다시 말하지만, S3 Tables 설명서가 시작하는 데 도움이 될 것입니다.
두 개의 S3 Tables 버킷 Amazon 리소스 이름(ARN)을 기록해 둡니다. 이 데모에서는 이 두 변수를 SOURCE_TABLE_ARN 및 DEST_TABLE_ARN 환경 변수라고 부릅니다.
1단계: 소스 데이터베이스 준비
터미널을 시작하고, EMR 클러스터에 연결하고, Spark 세션을 시작하고, 테이블을 생성하고, 데이터 행을 삽입합니다. 이 데모에서 사용하는 명령은 Amazon S3 Tables Iceberg REST 엔드포인트를 사용하여 테이블에 액세스하는 방법에 설명되어 있습니다.
sudo spark-shell \
--packages "org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.1,software.amazon.awssdk:bundle:2.20.160,software.amazon.awssdk:url-connection-client:2.20.160" \
--master "local[*]" \
--conf "spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" \
--conf “Spark.sql.DefaultCatalog=Spark_Catalog”\
--conf "spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkCatalog" \
--conf “spark.sql.catalog.spark_catalog.type=rest”\
--conf “spark.sql.catalog.spark_catalog.uri= https://s3tables.us-east-1.amazonaws.com/iceberg”\
--conf “spark.sql.catalog.spark_catalog.warehouse=arn:aws:s3tables:us-east- 1:012345678901:버킷/aws-news-blog-test”\
--conf “spark.sql.catalog.spark_catalog.rest.sigv4-enabled=true”\
--conf “spark.sql.catalog.spark_catalog.rest.signing-name=s3tables”\
--conf “spark.sql.catalog.spark_catalog.rest.signing-region=us-east-1"\
--conf “Spark.sql.Catalog.spark_Catalog.IO-IMPL=org.apache.iceberg.aws.s3.s3FileIO”\
--conf "spark.hadoop.fs.s3a.aws.credentials.provider=org.apache.hadoop.fs.s3a.SimpleAWSCredentialProvider" \
--conf “spark.sql.catalog.spark_catalog.rest-metrics-reporting-enabled=false”
spark.sql("""
CREATE TABLE s3tablesbucket.test.aws_news_blog (
customer_id STRING,
address STRING
) USING iceberg
""")
spark.sql("INSERT INTO s3tablesbucket.test.aws_news_blog VALUES ('cust1', 'val1')")
spark.sql("SELECT * FROM s3tablesbucket.test.aws_news_blog LIMIT 10").show()
+-----------+-------+
|customer_id|address|
+-----------+-------+
| cust1| val1|
+-----------+-------+지금까지는 좋아요.
2단계: S3 Tables의 복제 구성
이제 노트북에서 CLI를 사용하여 S3 테이블 버킷 복제를 구성합니다.
구성하기 전에 AWS Identity and Access Management(IAM) 정책을 생성하여 복제 서비스가 S3 테이블 버킷과 암호화 키에 액세스할 수 있도록 권한을 부여합니다. 자세한 내용은 S3 Tables 복제 설명서를 참조하세요. 이 데모에 사용한 권한은 다음과 같습니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:*",
"s3tables:*",
"kms:DescribeKey",
"kms:GenerateDataKey",
"kms:Decrypt"
],
"Resource": "*"
}
]
}이 IAM 정책을 생성한 후 이제 복제를 진행하고 구성할 수 있습니다.
aws s3tables-replication put-table-replication \
--table-arn ${SOURCE_TABLE_ARN} \
--configuration '{
"role": "arn:aws:iam::<MY_ACCOUNT_NUMBER>:role/S3TableReplicationManualTestingRole",
"rules":[
{
"destinations": [
{
"destinationTableBucketARN": "${DST_TABLE_ARN}"
}]
}
]
복제는 자동으로 시작됩니다. 업데이트는 일반적으로 몇 분 이내에 복제됩니다. 완료하는 데 걸리는 시간은 소스 테이블의 데이터 볼륨에 따라 달라집니다.
3단계: 복제된 테이블에 연결하여 데이터 쿼리
이제 EMR 클러스터에 다시 연결하고 두 번째 Spark 세션을 시작합니다. 이번에는 대상 테이블을 사용합니다.
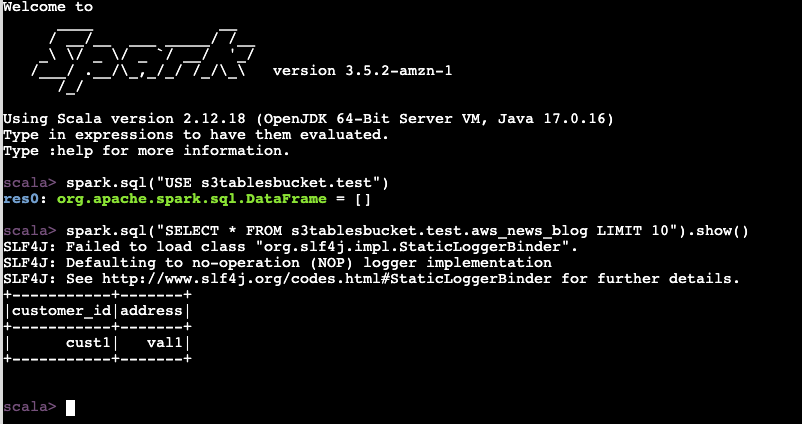
복제가 제대로 작동하는지 확인하기 위해 소스 테이블에 두 번째 데이터 행을 삽입합니다.
spark.sql("INSERT INTO s3tablesbucket.test.aws_news_blog VALUES ('cust2', 'val2')")
I wait a few minutes for the replication to trigger. I follow the status of the replication with the get-table-replication-status command.
aws s3tables-replication get-table-replication-status \
--table-arn ${SOURCE_TABLE_ARN} \
{
"sourceTableArn": "arn:aws:s3tables:us-east-1:012345678901:bucket/manual-test/table/e0fce724-b758-4ee6-85f7-ca8bce556b41",
"destinations": [
{
"replicationStatus": "pending",
"destinationTableBucketArn": "arn:aws:s3tables:us-east-1:012345678901:bucket/manual-test-dst",
"destinationTableArn": "arn:aws:s3tables:us-east-1:012345678901:bucket/manual-test-dst/table/5e3fb799-10dc-470d-a380-1a16d6716db0",
"lastSuccessfulReplicatedUpdate": {
"metadataLocation": "s3://e0fce724-b758-4ee6-8-i9tkzok34kum8fy6jpex5jn68cwf4use1b-s3alias/e0fce724-b758-4ee6-85f7-ca8bce556b41/metadata/00001-40a15eb3-d72d-43fe-a1cf-84b4b3934e4c.metadata.json",
"timestamp": "2025-11-14T12:58:18.140281+00:00"
}
}
]
}복제 상태가 준비로 표시되면 EMR 클러스터에 연결하여 대상 테이블을 쿼리합니다. 예상대로 새 데이터 행이 표시됩니다.

추가 정보
다음은 주의해야 할 몇 가지 추가 사항입니다.
- S3 Tables 복제는 Apache Iceberg V2와 V3 테이블 형식을 모두 지원하므로 테이블 형식을 유연하게 선택할 수 있습니다.
- 테이블 버킷 수준에서 복제를 구성할 수 있으므로 개별 테이블 구성 없이 해당 버킷 아래의 모든 테이블을 간편하게 복제할 수 있습니다.
- 복제 테이블은 대상 테이블에 대해 선택한 스토리지 클래스를 유지하므로 특정 비용 및 성능 요구 사항에 맞게 최적화할 수 있습니다.
- Iceberg 호환 카탈로그는 추가 조정 없이 복제 테이블을 직접 쿼리할 수 있습니다. 복제 테이블 위치만 지정하면 됩니다. 이를 통해 쿼리 엔진과 도구를 유연하게 선택할 수 있습니다.
요금 및 가용성
AWS 비용 및 사용량 보고서와 Amazon CloudWatch 지표를 통해 액세스 티어별 스토리지 사용량을 추적할 수 있습니다. 복제 모니터링의 경우, AWS CloudTrail 로그는 복제된 각 객체에 대한 이벤트를 제공합니다.
Intelligent Tiering을 구성하는 데 추가 비용은 없습니다. 각 티어의 스토리지 비용만 지불하면 됩니다. 테이블은 이전과 동일하게 작동하며 액세스 패턴에 따라 비용이 자동으로 최적화됩니다.
S3 Tables 복제의 경우 대상 테이블의 저장, 복제 PUT 요청, 테이블 업데이트(커밋), 복제된 데이터에 대한 객체 모니터링에 대한 S3 Tables 요금을 지불합니다. 리전 간 테이블 복제의 경우, 리전 쌍을 기준으로 Amazon S3에서 대상 리전으로의 리전 간 데이터 전송 비용도 지불합니다.
평소와 같이 자세한 내용은 Amazon S3 요금 페이지를 참조하세요.
두 기능 모두 현재 S3 Tables가 지원되는 모든 AWS 리전에서 사용할 수 있습니다.
이러한 새로운 기능에 대해 자세히 알아보려면 Amazon S3 Tables 설명서를 참조하거나 Amazon S3 콘솔에서 지금 사용해 보세요. AWS re:Post for Amazon S3 또는 AWS Support 담당자를 통해 피드백을 공유해 주세요.