Amazon Web Services 한국 블로그
기계 학습 및 고성능 컴퓨팅(HPC)을 위한 GPU 기반 Amazon EC2 P4 인스턴스 신규 출시
Amazon EC2 팀은 지난 10여 년 동안 고객에게 GPU 장착 인스턴스를 제공해 왔습니다. 1세대 클러스터 GPU 인스턴스는 2010년 후반에 시작되었고, 그다음부터 G2(2013), P2(2016), P3(2017), G3(2017), P3dn(2018) 및 G4(2019) 인스턴스가 출시되었습니다. 각각 충분한 CPU 전력, 메모리 및 네트워크 대역폭과 함께 용량을 계속 늘릴 수 있는 GPU를 통합하므로 GPU를 최대한 활용할 수 있습니다.
새로운 EC2 P4 인스턴스
오늘은 새로운 GPU 장착 P4 인스턴스에 대해 말씀드리고자 합니다. 이 인스턴스는 최신 Intel® Cascade Lake 프로세서로 구동되며 8개의 최신 NVIDIA A100 Tensor 코어 GPU를 갖추고 있습니다. 각 GPU는 NVLink를 통해 다른 모든 GPU에 연결되며 NVIDIA GPUDirect를 지원합니다. 2.5페타플롭스의 부동 소수점 성능과 320GB의 고대역폭 GPU 메모리를 통해 인스턴스는 최대 2.5배의 딥 러닝 성능을 제공할 수 있으며, P3 인스턴스에 비해 훈련 비용을 최대 60% 절감할 수 있습니다.
P4 인스턴스에는 초당 최대 16GB의 읽기 처리량을 제공할 수 있는 1.1TB의 시스템 메모리와 8TB의 NVME 기반 SSD 스토리지가 포함되어 있습니다.
네트워크에서는 최대 80K IOPS를 지원할 수 있는 19Gbps의 EBS 대역폭과 함께 P4 인스턴스를 위해 특별히 설계된 전용 페타비트급 비차단 네트워크 패브릭(EFA를 통해 액세스 가능)에 대한 4개의 100Gbps 네트워크 연결에 액세스할 수 있습니다.
EC2 UltraClusters
NVIDIA A100 GPU, NVIDIA GPUDirect 지원, 400Gbps 네트워킹, 페타비트급 네트워크 패브릭 및 S3, Amazon FSx for Lustre, AWS ParallelCluster와 같은 AWS 서비스에 대한 액세스 권한만 있으면 4,000개 이상의 GPU가 포함된 온디맨드 EC2 UltraClusters를 생성할 수 있습니다.
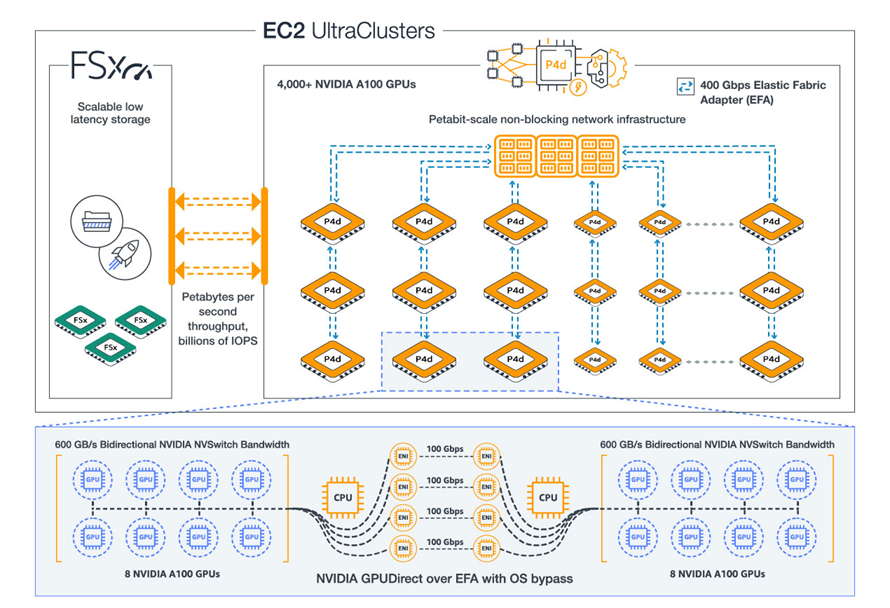
이 클러스터는 자연어 처리, 객체 감지 및 분류, 장면 이해, 지진 분석, 일기 예보, 재무 모델링 등 가장 까다로운 슈퍼컴퓨터급 기계 학습 및 HPC 워크로드를 처리할 수 있습니다.
정식 출시
P4 인스턴스는 하나의 크기(p4d.24xlarge)로 제공되며, 현재 미국 동부(버지니아 북부) 및 미국 서부(오레곤) 리전에서 시작할 수 있습니다. AMI에는 NVIDIA A100 드라이버와 최신 ENA 드라이버가 필요합니다(딥 러닝 컨테이너는 이미 업데이트됨).
여러 P4를 사용하여 분산 훈련 작업을 실행하는 경우 EFA 및 MPI 호환 애플리케이션을 사용하여 400Gbps의 네트워킹 및 페타바이트급 네트워킹 패브릭을 최대한 활용할 수 있습니다.
P4 인스턴스는 온디맨드, Savings Plan, 예약 인스턴스 및 스팟 양식으로 구매할 수 있습니다. Amazon SageMaker 및 Amazon Elastic Kubernetes Service와 같은 관리형 AWS 서비스에서의 P4 인스턴스 사용에 대한 지원이 현재 작업 중이며 올해 말에 정식으로 제공될 예정입니다.
Take it from Dave
제 동료 Dave Brown이 P4 인스턴스에 대해 훨씬 더 많은 내용을 알려드릴 수 있습니다.
자세한 내용
이전 세대(P3) 인스턴스와 비교한 P4d 인스턴스의 성능에 대해 자세히 알아보려면 Amazon EC2 P4d Instances in UltraClusters를 참조하십시오. 요금 및 추가 기술 세부 정보는 P4 인스턴스를 읽어보십시오.
— Jeff