AWS 기술 블로그
분산 트레이닝 관점에서의 AWS 인터커넥트 기술 소개 – AWS는 왜 인터커넥트 기술로 EFA를 사용하는가?
2025년 하반기부터 AWS에서 GPU 기반 분산 트레이닝 환경을 구축하는 고객이 급증하고 있습니다. 그럼에도 불구하고 많은 고객분들이 기존에 온프레미스 환경에서 사용되는 대표적인 인터커넥트 기술인 인피니밴드(Infiniband)와 AWS의 인터커넥트 기술의 차이점에 대해 명확히 이해하지 못하는 상황을 지켜보면서 이 블로그를 작성하게 되었습니다.
이번 블로그 시리즈에서는 AWS 클라우드 환경에서 분산 트레이닝 환경을 구축하고 운영하는데 필수적인 AWS의 인터커넥트 기술에 대해 소개하고자 합니다. 이 블로그 시리즈를 통해, 분산 트레이닝 관점에서 AWS 인터커넥트 기술의 특장점 및 제약 사항 등에 대해 이해의 폭을 넓혔으면 합니다. 인터커넥트의 개념과 AWS 인터커넥트 기술의 핵심 요소인 EFA(Elastic Fabric Adapter)및 SRD(Scalable Reliable Datagram)에 대한 기본적인 내용은 다음의 블로그를 참고하시기 바랍니다.
우선 첫 번째 블로그에서는 “인피니밴드와 EFA의 기술적 원리부터 AWS가 클라우드 환경에 최적화된 독자적인 인터커넥트 기술인 EFA를 선택한 이유, 그리고 두 기술의 철학적 차이와 실질적인 장단점” 에 대해 소개하고자 합니다.
시리즈 블로그 보기
- 분산 트레이닝 관점에서의 AWS 인터커넥트 기술 소개 – AWS는 왜 인터커넥트 기술로 EFA를 사용하는가?
- 분산 트레이닝 관점에서의 AWS 인터커넥트 기술 소개 – AWS의 인터커넥트 기반 기술, ENI 소개
- 분산 트레이닝 관점에서의 AWS 인터커넥트 기술 소개 – AWS 환경에서 NCCL을 이용한 GPU간 통신
- 분산 트레이닝 관점에서의 AWS 인터커넥트 기술 소개 – 분산 트레이닝을 위해 알아야 할 GPU간 고속 통신 기술
당신의 분산 트레이닝은 왜 느릴까?
대규모 모델 트레이닝 시 GPU 간 통신 오버헤드가 전체 트레이닝 시간의 약 22%에서 47%를 차지하며, 최신 H100 시스템에서도 이 비중이 약 43%에 달한다는 분석 결과가 있습니다. GPU 클러스터 운영 비용을 고려하면, 이 오버헤드는 대규모 트레이닝 프로젝트에서 상당한 인프라 낭비로 직결됩니다. 결국 아무리 자동차 엔진(GPU)이 슈퍼카 수준이라 하더라도, 도로(Network)가 막히면 목적지에 빨리 도착할 수 없습니다. LLM 트레이닝 효율화의 핵심은 엔진 튜닝만이 아니라 도로 정체 해소에도 있습니다. 따라서 인피니밴드 및 EFA의 특징 및 차이점에 대해 명확히 이해할 필요가 있습니다.
인피니밴드란 무엇인가?
인피니밴드는 1990년대 후반에 등장한 고성능 네트워크 기술로, 슈퍼컴퓨터와 온프레미스 HPC(High Performance Computing) 클러스터에서 수십 년간 표준으로 자리 잡아 왔습니다. 인피니밴드의 가장 큰 특징은 전용 하드웨어와 전용 프로토콜을 사용한다는 점입니다. 일반적인 이더넷과는 완전히 다른 별도의 네트워크 패브릭을 구성하며, 전용 HCA(Host Channel Adapter)와 인피니밴드 전용 스위치가 필요합니다.
인피니밴드는 크레딧 기반 흐름 제어(Credit-based Flow Control)를 자체적으로 내장하고 있어, 패킷이 드롭되지 않는 손실 없는(lossless) 통신을 기본으로 보장합니다. 크레딧 기반의 흐름 제어란, 수신 측의 버퍼 상태를 고려하여 송신량을 조절함으로써, 버퍼 넘침으로 인한 패킷 유실(Drop)을 원천적으로 방지하는 메커니즘입니다. 또한 RDMA(Remote Direct Memory Access)를 지원하여 CPU의 개입 없이 한 서버의 메모리에서 다른 서버의 메모리로 데이터를 직접 전송할 수 있습니다. 따라서 매우 낮은 지연 시간과 높은 대역폭을 실현할 수 있어, 대형 슈퍼컴퓨터와 금융, 기상, 제조 분야 등의 HPC 클러스터에서 널리 사용되고 있습니다.
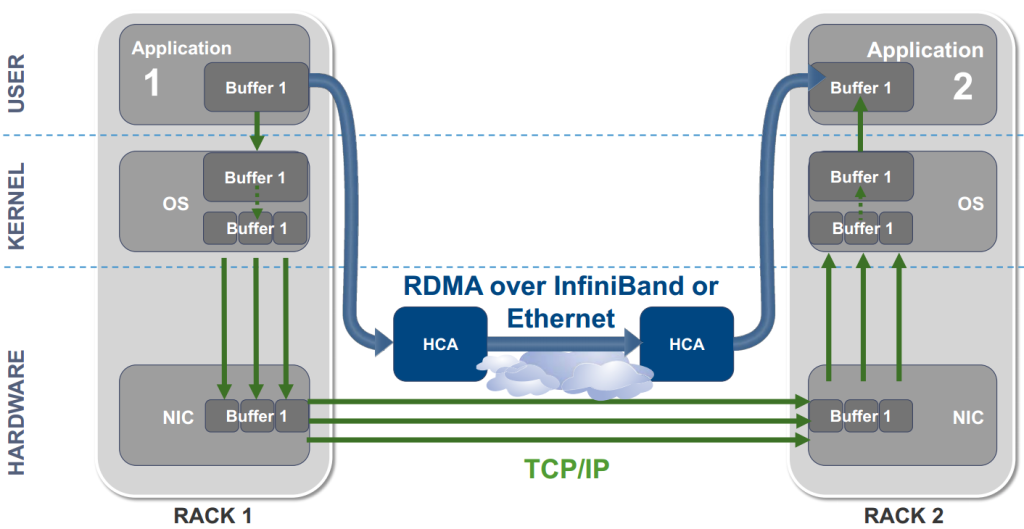
그림1. 인피니밴드의 기본 개념
인피니밴드를 비롯한 고성능 인터커넥트 기술의 핵심에는 앞서 언급한 RDMA가 있습니다. RDMA가 왜 중요한지 이해하려면, 전통적인 TCP/IP 통신 방식과 비교해 보는 것이 가장 직관적입니다.
전통적인 TCP/IP 통신: 데이터가 여러 번 복사된다
- 일반적인 TCP/IP 통신에서 데이터가 한 서버에서 다른 서버로 전달되는 과정을 살펴보겠습니다. 그림1의 RACK1 서버 A의 애플리케이션이 데이터를 보내려 하면, 먼저 애플리케이션의 메모리 버퍼에 있는 데이터가 운영체제(OS) 커널의 버퍼로 복사됩니다. 이후 커널은 이 데이터를 다시 NIC(Network Interface Card)의 버퍼로 복사하여 네트워크로 전송합니다. 반대편 RACK2 서버 B에서는 이 과정이 역순으로 반복됩니다. NIC이 수신한 데이터를 커널 버퍼로, 커널 버퍼에서 다시 애플리케이션 버퍼로 복사합니다.
- 결과적으로 데이터는 총 4번의 복사 과정을 거치게 됩니다. 매번 복사가 일어날 때마다 CPU가 개입해야 하고, 사용자 공간(User space)과 커널 공간(Kernel space) 사이를 오가는 시스템 콜 오버헤드도 발생합니다. 수백~수천 개의 GPU가 동시에 그래디언트(gradient, 모델이 실수를 고치는 방향 지시서)를 교환하는 분산 트레이닝 환경에서는 이 오버헤드가 전체 성능을 심각하게 저하시킵니다.
RDMA 통신: 커널을 건너뛰고 직접 전달한다
- RDMA는 이 문제를 근본적으로 해결합니다. RACK1 서버 A의 애플리케이션 버퍼에 있는 데이터는 OS 커널을 거치지 않고 HCA(Host Channel Adapter)로 직접 전달됩니다. HCA는 네트워크를 통해 RACK2 서버 B의 HCA로 데이터를 전송하고, RACK2 서버 B의 HCA는 수신한 데이터를 곧바로 애플리케이션의 메모리 버퍼에 직접 기록합니다.
- 이 과정에서 핵심은 세 가지입니다. 첫째, OS-Bypass: 커널을 완전히 우회하여 사용자 공간의 애플리케이션이 하드웨어와 직접 통신합니다. 둘째, Zero-Copy: 데이터를 중간에 복사하지 않아 불필요한 메모리 사용과 CPU 부하가 사라집니다. 셋째, CPU 개입 최소화: CPU는 통신 명령만 내리고, 실제 데이터 전송은 HCA가 독립적으로 처리합니다.
각 구성 요소의 역할
- HCA(Host Channel Adapter): RDMA를 지원하는 전용 네트워크 어댑터입니다. 내부에 DMA 엔진을 탑재하고 있어 CPU의 도움 없이 메모리와 직접 통신할 수 있으며, 인피니밴드 Verbs나 RoCE 같은 RDMA 프로토콜을 하드웨어 레벨에서 처리합니다.
- NIC(Network Interface Card): 일반적인 이더넷 네트워크 카드로, TCP/IP 통신을 담당합니다. 데이터를 전송하려면 반드시 커널을 거쳐야 합니다.
- Buffer(버퍼): 각 레이어에 존재합니다. 사용자 레이어의 버퍼는 애플리케이션이 직접 읽고 쓰는 메모리 영역이고, 커널 레이어의 버퍼는 TCP/IP 통신 시 OS가 데이터를 임시 저장하는 영역이며, 하드웨어 레이어의 버퍼는 NIC/HCA 내부의 송수신 버퍼입니다. RDMA에서는 커널 레이어의 버퍼를 완전히 건너뜁니다.
수백~수천 개의 GPU가 동시에 그래디언트를 교환하는 분산 AI 트레이닝 환경에서, RDMA를 사용하면 CPU는 계산 작업에만 집중하고 통신은 HCA가 독립적으로 처리합니다. 반면 TCP/IP를 사용하면 CPU가 통신 처리에 많은 시간을 소모하고, 데이터 복사 오버헤드로 인해 대역폭이 낭비되며, GPU가 통신 완료를 기다리며 유휴 상태에 머무는 시간이 늘어납니다. 바로 이것이 인피니밴드, RoCE, 그리고 AWS EFA 모두가 RDMA를 핵심 기술로 채택하는 이유입니다. “데이터를 여러 번 복사하며 느리게 가는가, 아니면 한 번에 직접 보내는가” — 이 차이가 전체 시스템 성능을 결정짓습니다.
RoCE
- 인피니밴드의 성능은 매력적이지만, 전용 하드웨어와 별도의 네트워크 인프라를 구축해야 한다는 점은 높은 비용과 운영 복잡도를 수반합니다. 이러한 한계를 극복하기 위해 등장한 것이 RoCE(RDMA over Converged Ethernet)입니다.
- RoCE는 기존 이더넷 인프라 위에서 RDMA를 구현하는 기술입니다. 별도의 인피니밴드 전용 네트워크 없이도 RDMA의 이점을 활용할 수 있다는 점에서 비용 효율적인 대안으로 주목받았습니다.
- 초기 버전인 RoCEv1은 이더넷 L2 위에서 직접 동작하기 때문에 IP 헤더가 없습니다. 라우터는 L3 IP 헤더를 기반으로 패킷을 전달하는데, RoCEv1 프레임에는 이 헤더가 없어 동일 스위치에 연결된 서버들끼리만 통신이 가능했습니다. RoCEv2는 전송 계층을 UDP/IP로 변경하면서 이 제약을 해소했습니다. IP 헤더가 생기면서 라우팅이 가능해졌고, 멀티랙 구성이나 서로 다른 서브넷의 서버 간에도 RDMA 통신을 사용할 수 있게 되었습니다.
- 다만 인피니밴드와 달리 lossless 통신을 기본으로 보장하지 않습니다. 이더넷의 특성상 패킷 손실이 발생할 수 있기 때문에, 실제 운영 환경에서는 PFC(Priority Flow Control)와 ECN(Explicit Congestion Notification) 설정이 필수입니다. PFC는 특정 우선순위 큐가 가득 찼을 때 해당 트래픽을 일시적으로 멈추는 방식으로 동작하는데, 수천 대 규모의 대형 클러스터에서는 PFC pause 프레임이 연쇄적으로 전파되며 네트워크 전체가 마비되는 PFC Storm 문제가 발생할 수 있습니다. ECN은 PFC의 한계를 보완하기 위해 함께 사용됩니다. 혼잡이 감지되면 패킷을 드롭하는 일반 이더넷과 달리, ECN은 패킷에 혼잡 신호를 마킹하여 송신 측이 스스로 전송 속도를 줄이도록 유도합니다. 이를 통해 PFC Storm 없이도 혼잡을 사전에 완화할 수 있습니다. 이 두 가지 설정이 제대로 되어 있지 않으면 패킷 손실로 인한 재전송이 발생하고, RDMA 성능이 크게 저하될 수 있습니다.
소프트웨어 스택: libibverbs와 libfabric
인터커넥트 기술을 이해하려면 소프트웨어 스택도 함께 살펴볼 필요가 있습니다. 인피니밴드와 RoCE 환경에서는 libibverbs(InfiniBand Verbs)라는 라이브러리를 통해 애플리케이션이 RDMA 기능에 접근합니다. MPI, NCCL 등 분산 컴퓨팅 프레임워크들은 이 libibverbs를 통해 하드웨어와 통신합니다.
반면 AWS EFA 환경에서는 libfabric이 libibverbs에 대응하는 역할을 합니다. libfabric은 다양한 네트워크 패브릭을 추상화하는 오픈소스 라이브러리로, EFA는 libfabric 위에서 자체적인 SRD 프로토콜을 통해 고성능 통신을 구현합니다.
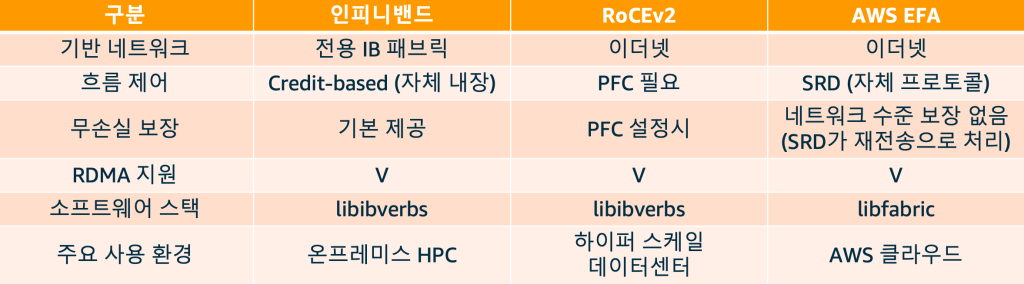
표1. 고성능 네트워크 기술 비교: 인피니밴드 vs RoCEv2 vs AWS EFA
왜 AWS는 인피니밴드를 선택하지 않았는가?
고성능 컴퓨팅(HPC) 세계에서 인피니밴드는 오랫동안 최고의 인터커넥트 기술로 군림해 왔습니다. 낮은 지연 시간, 높은 대역폭, 그리고 손실 없는(lossless) 통신을 기본으로 제공하는 인피니밴드는 슈퍼컴퓨터와 온프레미스 HPC 클러스터의 표준으로 자리 잡았습니다. 그렇다면 AWS는 왜 이 검증된 기술을 채택하지 않고, EFA라는 독자적인 솔루션을 개발하는 길을 선택했을까요? 그 이유는 단순한 기술적 선택을 넘어, 클라우드 비즈니스의 본질과 맞닿아 있습니다.
이미 지난 블로그에서 언급한 것처럼, AWS는 자사의 클라우드 환경에 최적화된 인터커넥트 프로토콜인 SRD를 개발하여, 고성능의 네트워크 어댑터인 EFA에 탑재시켰습니다. AWS 클라우드 환경에서 분산 트레이닝 환경을 구축하기 위해서는 EFA의 선택은 필수이며, 반드시 이 기능을 ‘enable’ 시켜야 EFA에서 제공하는 OS 바이패스(SRD) 및 RDMA 기능을 사용할 수 있습니다. 만약 EFA가 제대로 설정이 되어 있지 않다면, GPU 인스턴스간 통신은 TCP/IP를 통해 연결되기 때문에, 분산 트레이닝 속도가 급속하게 저하됩니다.
인피니밴드는 구조적으로 전용 패브릭(dedicated fabric) 위에서 동작하도록 설계되어 있습니다. 특정 조직이 독점적으로 사용하는 폐쇄형 네트워크 환경에서는 탁월한 성능을 발휘하지만, AWS가 운영하는 클라우드 환경은 그 전제 자체가 다릅니다. AWS의 핵심은 멀티테넌시(multi-tenancy), 즉 수많은 고객이 동일한 물리적 인프라를 공유하는 구조입니다. 고객마다 격리된 인피니밴드 서브넷을 독립적으로 프로비저닝하고 관리하는 것은 운영 복잡도 측면에서 사실상 비현실적입니다. 인피니밴드는 클라우드가 요구하는 동적인 자원 할당과 테넌트 간 격리를 동시에 만족시키기 어렵습니다. 결국 인피니밴드는 “모두가 함께 쓰는 클라우드”가 아닌, “나만 쓰는 전용 클러스터”를 위한 기술입니다.
기술적 우수성만큼이나 중요한 것이 경제성입니다. 인피니밴드를 구현하려면 전용 HCA(Host Channel Adapter)와 인피니밴드 전용 스위치가 필요합니다. 이 장비들은 이더넷 기반 솔루션에 비해 현저히 높은 단위 비용을 가집니다. 온프레미스 HPC 클러스터처럼 수백 대 규모에서는 이 비용 차이가 감내할 수 있는 수준일 수 있습니다. 그러나 AWS처럼 전 세계에 수백만 대 이상의 서버를 운영하는 환경에서는 단위 비용의 차이가 천문학적인 규모로 증폭됩니다. 클라우드 사업의 경쟁력은 결국 규모의 경제에서 나오는데, 인피니밴드는 그 규모에서 오히려 비용 부담을 키우는 요소가 됩니다.
인피니밴드는 HPC 워크로드에 최적화된 기술입니다. 그런데 AWS가 제공해야 하는 서비스의 스펙트럼은 훨씬 넓습니다. 웹 서버, 데이터베이스, 머신러닝, 실시간 스트리밍, 그리고 HPC까지—이 모든 워크로드가 동일한 물리적 인프라 위에서 실행되어야 합니다. 인피니밴드 전용 클러스터를 구성하면 그 인프라는 HPC 이외의 용도로 활용하기 어렵습니다. 반면 EFA는 일반 EC2 인스턴스에 선택적으로 추가할 수 있는 구조로 설계되어 있습니다. 필요한 인스턴스에만 고성능 패브릭을 붙이고, 나머지는 표준 이더넷으로 운영하는 유연성—이것이 클라우드 인프라가 가져야 할 본질적인 특성입니다.
인피니밴드 시장은 사실상 NVIDIA가 독점하고 있습니다. 핵심 인프라 기술을 단일 벤더에 의존한다는 것은 공급망 리스크, 가격 협상력 약화, 그리고 기술 로드맵에 대한 통제권 상실을 의미합니다. AWS는 이 문제를 정면으로 돌파했습니다. Nitro 시스템, EFA ASIC, 그리고 자체 설계 칩(Graviton, Trainium, Inferentia)에 이르기까지, AWS는 핵심 실리콘을 직접 설계하고 제어하는 전략을 일관되게 추진해 왔습니다. EFA 역시 이 전략의 연장선상에 있습니다. 자체 솔루션을 통해 공급망을 통제하고, 워크로드 특성에 맞게 하드웨어를 커스터마이징할 수 있는 역량을 확보한 것입니다.
마지막으로, AWS는 이미 전 세계적으로 방대한 이더넷 기반 인프라를 운영하고 있습니다. 여기에는 장비 뿐만 아니라 장기간 축적된 운영 노하우, 모니터링 툴, 장애 대응 프로세스가 포함됩니다. 인피니밴드로 전환한다는 것은 이 모든 자산을 버리고 완전히 새로운 생태계를 구축해야 함을 의미합니다. 반면 EFA는 이더넷 기반 인프라 위에서 동작하도록 설계되어, 기존 생태계의 이점을 그대로 활용하면서도 RDMA 수준의 고성능을 제공합니다. 검증된 기반 위에 혁신을 더하는 접근법입니다.
인피니밴드 대비 EFA의 장점
AWS가 인피니밴드 대신 EFA를 선택한 전략적 이유를 이해했다면, 이제 이 선택이 실제 사용자에게 어떤 혜택을 가져다주는지 살펴볼 필요가 있습니다. 온프레미스에서 인피니밴드 환경을 구축하려면 상당한 초기 투자가 필요합니다. 하드웨어 비용, 데이터센터 공간, 전력, 냉각 시스템, 전문 운영 인력 채용 및 교육, 그리고 지속적인 유지보수 비용이 발생합니다. 이러한 비용은 클러스터 사용률과 무관하게 지속적으로 발생합니다. 피크 시즌을 대비해 구축한 클러스터가 평소에는 불과 20-30% 만 활용되더라도, 전체 인프라에 대한 비용은 계속 지불해야 합니다.
반면 EFA는 AWS 인프라 위에서 동작하기 때문에 사용자가 전용 하드웨어를 직접 구매하거나 관리할 필요가 없습니다. 초기 투자 없이 온디맨드 방식으로 필요할 때만 사용하고, 사용한 만큼만 비용을 지불합니다. 대규모 HPC 클러스터를 상시 운영하는 대신, 피크 시점에만 수천 개의 노드를 즉시 확보하고 작업이 끝나면 반납하는 방식이 가능해집니다. 예를 들어, 분기별로 대규모 분산 트레이닝을 실행하는 연구팀이라면 온프레미스에서는 연중 내내 1,000노드 클러스터 유지 비용을 지불해야 하지만, EFA를 사용하면 분기마다 필요한 2주 동안만 1,000노드를 사용하고 나머지 44주는 비용이 발생하지 않습니다.
인피니밴드 환경에서는 사용자가 하드웨어 유지보수, 펌웨어 관리, 네트워크 관리, 장애 대응, 용량 계획 등 전체 스택을 직접 관리해야 합니다. 이는 상당한 전문성과 인력을 요구하며, 많은 조직에서 실제 연구나 개발보다 인프라 관리에 더 많은 시간을 소비하는 경우가 발생합니다. EFA 환경에서는 인프라 관리의 대부분을 AWS가 담당합니다. EFA 하드웨어 및 네트워크 인프라, 물리적 유지보수 및 장애 대응, 펌웨어 업데이트 및 보안 패치, 용량 계획 및 확장, 24/7 모니터링 및 SLA 보장은 모두 AWS의 책임입니다. 사용자는 소프트웨어 설정 및 최적화, 워크로드 실행 및 결과 분석, 애플리케이션 레벨 튜닝에만 집중할 수 있습니다.
클러스터 구성 시간 측면에서도 차이가 뚜렷합니다. 온프레미스 인피니밴드 환경은 하드웨어 조달부터 구성 완료까지 수주에서 수개월이 소요될 수 있습니다. 하드웨어 발주 및 배송에 4-8주, 데이터센터 설치에 1-2주, 네트워크 구성 및 테스트에 1-2주, 소프트웨어 설정 및 검증에 1-2주가 필요합니다. 반면 AWS ParallelCluster를 활용하면 YAML 설정 파일 작성만으로 수 시간 내에 클러스터를 구성할 수 있습니다. 이는 빠른 실험과 반복이 중요한 현대 AI/HPC 워크로드 환경에서 결정적인 차이를 만들어냅니다.
EFA는 AWS 생태계 안에서 설계된 기술입니다. Amazon S3, Amazon FSx for Lustre, AWS Batch, Amazon SageMaker 등 다양한 AWS 서비스와 자연스럽게 연동되며, 기존 클라우드 워크로드와도 호환됩니다. 인피니밴드 전용 클러스터는 이러한 클라우드 서비스와의 통합을 위해 별도의 브리징 레이어가 필요한 반면, EFA 기반 환경에서는 HPC 워크로드와 일반 클라우드 워크로드가 동일한 인프라 위에서 유기적으로 연결됩니다. 전형적인 AI 트레이닝 파이프라인을 예로 들면, S3에서 대규모 데이터셋을 로드하고, AWS Batch로 데이터 전처리 작업을 실행하며, EFA 지원 인스턴스에서 대규모 모델을 트레이닝하고, 트레이닝된 모델을 S3에 저장한 후, SageMaker로 모델을 배포 및 서빙하는 모든 단계가 동일한 AWS 환경 내에서 원활하게 연결됩니다.
인피니밴드가 나쁜 기술이라서 AWS가 외면한 것이 아닙니다. 인피니밴드는 여전히 온프레미스 HPC 환경에서 탁월한 선택지입니다. 다만 AWS가 운영하는 클라우드의 규모, 멀티테넌트 구조, 비용 효율성, 그리고 전략적 독립성이라는 요구사항 앞에서, 인피니밴드는 최적의 답이 아니었습니다. AWS는 클라우드라는 새로운 환경에 맞는 새로운 해답을 직접 만들었습니다. 그것이 바로 EFA와 SRD 입니다. 이는 단순한 기술 선택이 아니라, 클라우드 인프라의 미래를 어떻게 정의할 것인가에 대한 AWS의 철학적 선언이기도 합니다.
그렇다면 AWS EFA와 인피니밴드 중 어느 기술이 우수할까?
때로는 일부 고객들이 저에게 위와 같은 질문을 하곤 합니다. 인피니밴드와 EFA의 관계를 이해하는 데 있어, macOS와 Windows의 관계는 꽤 직관적인 비유가 됩니다. macOS에서 개발된 macOS 특화 프로그램이 Windows 환경에서는 동작하지 않거나 예상치 못한 문제가 발생할 수 있는 것처럼, 인피니밴드에 특화된 특정 라이브러리나 모델이 EFA 환경에서는 제대로 동작하지 않거나 성능 저하가 발생할 수 있습니다.
대표적인 사례가 DeepSeek가 개발한 MoE 모델 전용 고성능 통신 라이브러리인 DeepEP입니다. DeepEP는 GPU가 CPU의 개입 없이 네트워크 카드(NIC)에 직접 명령을 내려 데이터를 주고받는 NVIDIA의 IBGDA(인피니밴드 GPUDirect Async) 기술을 핵심 메커니즘으로 활용하며, NVIDIA 인피니밴드 하드웨어와 전용 드라이버에 강하게 결합되어 있습니다. 반면 EFA는 인피니밴드 표준이 아닌 자체적인 SRD 프로토콜과 libfabric 기반으로 동작하기 때문에, DeepEP가 요구하는 IBGDA 하드웨어 기능을 제공하지 않습니다. 이처럼 인피니밴드 전용 환경에서 최적화된 소프트웨어 스택은 EFA 환경에서 동일한 성능을 기대하기 어려울 수 있습니다. 그렇다고 해서 EFA가 나쁜 기술이라고 말할 수는 없습니다. 두 기술은 서로 다른 철학과 목표를 가지고 설계되었기 때문입니다. 즉, EFA가 IBGDA를 지원하지 않는 것이 성능 저하의 직접적인 원인이라기보다는, DeepEP가 인피니밴드 생태계에 강하게 결합된 소프트웨어이기 때문에 EFA 환경에서 동일한 최적화 경로를 따를 수 없다는 것이 핵심입니다.
인피니밴드는 “성능을 위해 전용 환경을 구축한다”는 철학을 바탕으로 합니다. 전용 하드웨어와 전용 패브릭 위에서 극강의 속도를 추구하며, 온프레미스 HPC 클러스터나 슈퍼컴퓨터처럼 폐쇄적이고 통제된 환경에서 그 진가를 발휘합니다. macOS가 Apple 하드웨어와의 긴밀한 통합을 통해 최적화된 사용자 경험을 제공하는 것과 유사합니다. 반면 EFA는 “규모를 위해 기존 환경을 혁신한다”는 철학을 따릅니다. 이더넷 기반의 범용 인프라 위에서 RDMA 수준의 고성능을 구현하면서도, 수만 대 규모의 클라우드 환경에서 유연하게 확장할 수 있도록 설계되었습니다. Windows가 다양한 하드웨어 벤더와 소프트웨어 생태계를 포용하며 범용성과 확장성을 확보한 것과 닮아 있습니다.
결국 인피니밴드는 온프레미스 HPC 클러스터처럼 전용 환경에서 극한의 성능이 필요한 곳에 적합하고, EFA는 클라우드 기반의 대규모 머신러닝 트레이닝 및 추론처럼 확장성과 유연성이 중요한 환경에 적합합니다. 어느 쪽이 더 우월한 기술이냐의 문제가 아니라, 어떤 환경에서 무엇을 우선시 하느냐의 문제입니다.
맺음말
지금까지 인피니밴드 기술의 기초부터 시작하여, AWS가 인피니밴드 대신 EFA를 선택한 이유, 그리고 두 기술의 철학적 차이와 EFA의 실질적인 장점까지 살펴보았습니다.
기술의 세계에서 “어느 것이 더 좋은가”라는 질문은 종종 잘못된 질문입니다. 인피니밴드는 수십 년간 HPC 세계를 이끌어온 검증된 기술이며, 온프레미스 전용 클러스터 환경에서 여전히 탁월한 선택입니다. EFA는 클라우드라는 새로운 패러다임 위에서 설계된 기술로, 규모와 유연성, 그리고 운영 효율성이라는 클라우드 고유의 가치를 극대화합니다.
중요한 것은 자신이 해결하려는 문제가 무엇인지, 그리고 어떤 환경에서 워크로드를 운영할 것인지를 명확히 이해하는 것입니다. 온프레미스에서 극한의 성능이 필요한 폐쇄형 HPC 클러스터를 운영한다면 인피니밴드가 여전히 강력한 선택입니다. 반면 클라우드 기반의 대규모 AI 트레이닝, 빠른 실험과 반복, 그리고 AWS 생태계와의 통합이 중요하다면 EFA는 그 요구에 최적화된 답을 제공합니다.
앞으로도 인터커넥트 기술은 계속 진화할 것입니다. 중요한 것은 기술 그 자체가 아니라, 그 기술이 어떤 문제를 해결하고 어떤 가치를 만들어내는가 입니다. 이 블로그가 여러분의 인프라 선택에 조금이나마 도움이 되었기를 바랍니다.
다음 블로그에서는 AWS의 인터커넥트 기술을 이해하기 위해 필수적이라고 할 수 있는 가상 인터페이스 기술인 ENI (Elastic Network Interface)에 대해 소개할 예정입니다.