O blog da AWS
Criação de aplicativos multi regionais Serverless resilientes na AWS
Por Vamsi Vikash Ankam, arquiteto sênior de soluções para Serverless na Amazon Web Services.
Aplicativos de missão crítica exigem alta disponibilidade e resiliência contra possíveis interrupções. Nos jogos online, milhões de jogadores se conectam simultaneamente, tornando evidentes os desafios de disponibilidade. Quando as plataformas de jogos sofrem interrupções, os jogadores perdem o progresso, os torneios são interrompidos e a reputação da marca é prejudicada. Os ambientes tradicionais geralmente superprovisionam a computação para enfrentar esses desafios, resultando em configurações complexas e altos custos de infraestrutura e operação. A moderna infraestrutura Serverless da Amazon Web Services (AWS) oferece uma abordagem mais eficiente. Esta publicação apresenta as melhores práticas de arquitetura para criar aplicativos Serverless resilientes, demonstradas por meio de uma implementação de autorizador em várias regiões.
Visão geral
É tarde demais se você reconhecer a importância da disponibilidade somente depois de passar por um evento de desastre. Os aplicativos falham por vários motivos, como problemas de infraestrutura, defeitos de código, erros de configuração, picos de tráfego inesperados ou interrupções no serviço em nível regional. Serviços comerciais essenciais, como sistemas de autenticação, processadores de pagamento e recursos de jogos em tempo real, exigem alta disponibilidade. Para minimizar o impacto na experiência do usuário e na receita da empresa, estabeleça tempos de recuperação limitados para serviços essenciais durante interrupções.
As arquiteturas Serverless da AWS fornecem inerentemente alta disponibilidade por meio de implantações de Zona de Disponibilidade (AZ) e escalabilidade integrada. Esses serviços minimizam o gerenciamento da infraestrutura enquanto operam em um modelo de precificação de pagamento por valor em nível regional. O modelo de pagamento por valor Serverless da AWS permite implantações econômicas em várias regiões, tornando-o ideal para criar arquiteturas resilientes.
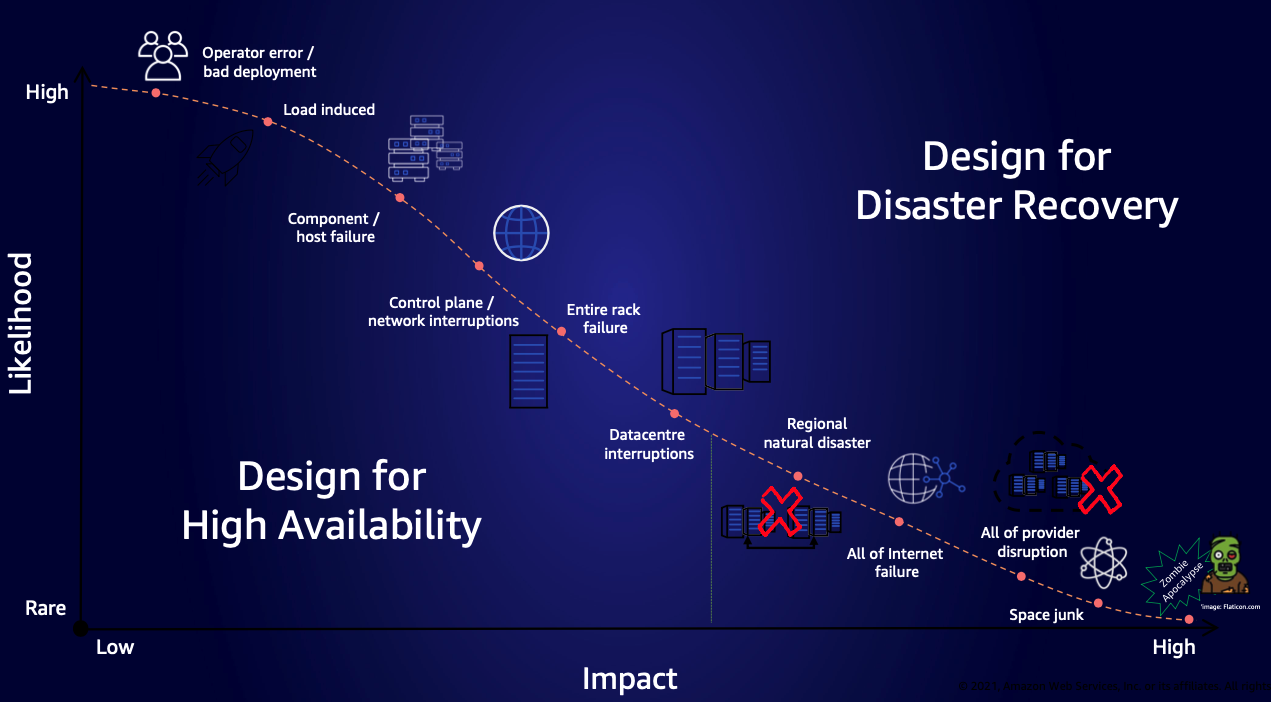
Figura 1. Gráfico mostrando várias causas de falha, seu impacto e com que frequência elas acontecem
Figura 1. Gráfico mostrando várias causas de falha, seu impacto e com que frequência elas acontecem
O gráfico anterior mapeia as falhas, de erros operacionais comuns a eventos catastróficos raros. Ele orienta as organizações na priorização de estratégias de recuperação em várias regiões com base na probabilidade e no impacto potencial nos negócios.
Decisões regionais
Para determinar a abordagem de múltiplas regiões apropriada, avalie cuidadosamente os seguintes fatores:
- Avalie se seus requisitos de objetivo de tempo de recuperação (RTO) e objetivo de ponto de recuperação (RPO) podem ser atendidos em uma única região ou se uma arquitetura de múltiplas regiões é necessária para atingir seus objetivos de recuperação.
- Os benefícios comerciais da redundância de múltiplas regiões superam os custos operacionais de replicação e sincronização de dados e o aumento do custo e da complexidade da implementação?
- Avalie se as leis de soberania de dados, os requisitos de conformidade ou as restrições geográficas impedem a replicação de dados em regiões específicas da AWS.
- Certifique-se de que as regiões escolhidas em uma solução de múltiplas regiões tenham compatibilidade de serviços, limites de cota e preços adequados às suas necessidades.
Depois de avaliar esses requisitos, se as organizações determinarem a necessidade de cargas de trabalho em várias regiões, elas deverão escolher entre dois padrões de arquitetura: implantações ativo-passivas ou ativo-ativas. Cada padrão oferece vantagens e compensações distintas em termos de resiliência, custos e complexidade operacional.
Padrões de implantação em várias regiões
As seções a seguir descrevem os diferentes padrões de implantação em várias regiões: ativo-passivo e ativo-ativo.
Ativo-passivo
Nesse padrão, uma região da AWS serve como região “ativa”, gerenciando todo o tráfego de produção, enquanto outras regiões permanecem “passivas”, conforme mostrado na figura a seguir. As regiões passivas replicam dados e configurações da região ativa sem atender às solicitações e estão preparadas para lidar com solicitações durante interrupções no serviço na região “ativa”. Dependendo da criticidade do aplicativo, as regiões passivas implementam vários níveis de prontidão da infraestrutura: infraestrutura totalmente implantada (Hot Standby), infraestrutura parcialmente implantada (Warm Standby) ou infraestrutura central mínima (Pilot Light).
As arquiteturas ativo-passivas tradicionais precisam de investimentos significativos em infraestrutura ociosa: balanceadores de carga, grupos de escalonamento automático, recursos computacionais em execução e sistemas de monitoramento. As organizações podem usar aplicativos Serverless da AWS, com seus preços de pagamento por valor, para pagar principalmente pela replicação de dados, não por recursos computacionais ociosos. A AWS gerencia a infraestrutura subjacente, eliminando a maior parte da sobrecarga operacional.
As cotas de serviço, os limites de API e as configurações de simultaneidade devem corresponder entre as regiões da AWS para fornecer um failover contínuo. O AWS Lambda oferece simultaneidade provisionada para manter as funções ativas e responsivas, o que é particularmente útil para regiões secundárias durante o failover. Ele ajuda a reduzir as partidas a frio, mantendo ambientes de execução quentes, portanto, o sistema pode lidar com picos repentinos de tráfego com menos partidas a frio. Observe que a simultaneidade provisionada incorre em custos de computação, independentemente do uso. Considere implementar o escalonamento automático para simultaneidade provisionada com base em padrões de tráfego para otimizar os custos durante os períodos de inatividade.
Esse padrão é adequado para organizações que buscam uma solução econômica de recuperação de desastres (DR), porque as cobranças Serverless da AWS se aplicam somente quando os recursos são usados ativamente na região secundária. Serviços gerenciados, como o Amazon DynamoDB Global Tables e o Amazon Aurora Global Database, lidam com a replicação de dados, simplificando ainda mais a implementação. O autorizador Serverless discutido posteriormente neste artigo demonstra esse padrão na prática.
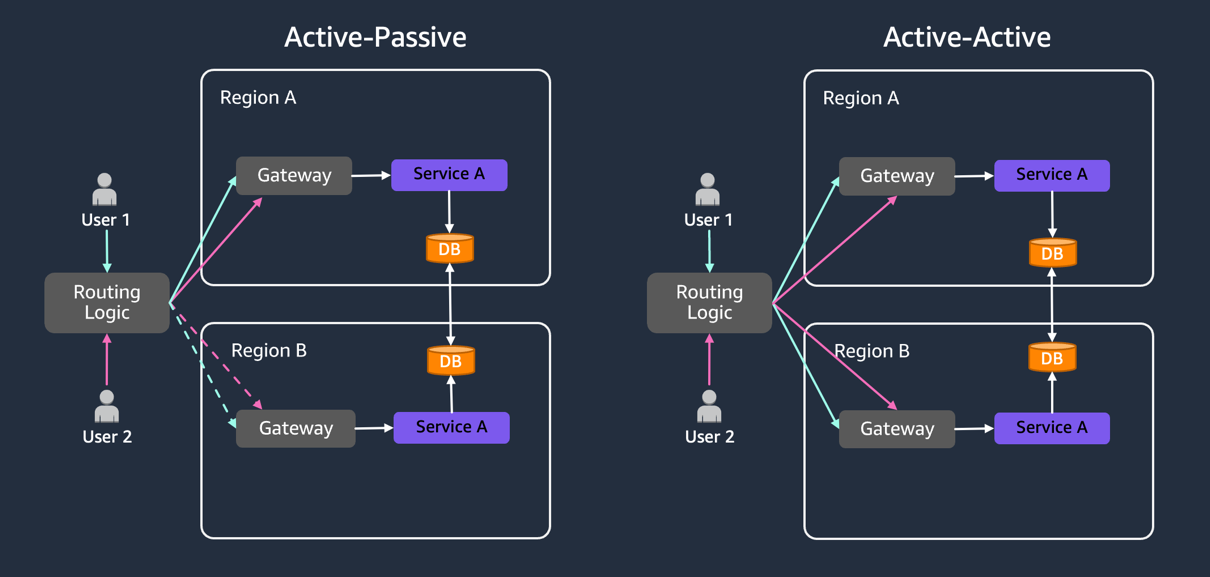
Figura 2: O padrão ativo-passivo com linhas pontilhadas mostra regiões em espera, enquanto os padrões ativo-ativos atendem ao tráfego simultâneo
Ativo-ativo
Nesse padrão, várias regiões atendem ativamente ao tráfego simultaneamente, distribuindo a carga e fornecendo recursos rápidos de failover. As arquiteturas ativo-ativas são caras e projetadas para oferecer a maior disponibilidade. No entanto, eles não fornecem inerentemente DR para todos os modos de falha em potencial. Essa abordagem é adequada para aplicativos que precisam de roteamento baseado em geolocalização ou requisitos de maior disponibilidade.
As implantações ativo-ativas precisam de engenharia rigorosa para lidar com a sincronização de dados e a resolução de conflitos. Cada região deve ser dimensionada para lidar com a carga total do aplicativo se outra região apresentar deficiências no serviço. Os usuários ativos são distribuídos pelas regiões da AWS, portanto, uma interrupção no serviço em uma região redireciona todo o tráfego para as regiões restantes, o que exige que eles lidem com a carga combinada. Para melhorar a resiliência do aplicativo, implemente mecanismos de repetição, disjuntores e estratégias de fallback. Planeje a estabilidade estática pré-provisionando a capacidade e implementando o armazenamento em cache do lado do cliente. Serviços como o Amazon Route 53 com roteamento baseado em latência e as tabelas globais do Amazon DynamoDB com forte consistência fornecem a base, mas precisam de testes completos em vários cenários de falha. Este blog não abordará implantações ativas-ativas.
Autorizador de múltiplas regiões Serverless
Para demonstrar o cenário ativo-passivo, criamos um aplicativo de exemplo que demonstra como criar um autorizador de múltiplas regiões Serverless usando o Amazon API Gateway, as funções Lambda e o Amazon Route53. Plataformas modernas de jogos e entretenimento hospedam serviços essenciais, como matchmaking de jogadores, transmissão ao vivo e análises esportivas em tempo real. Esses serviços dependem de sistemas de autorização robustos: quando a autorização falha, os jogadores não podem participar das partidas, os espectadores perdem o acesso às transmissões e os eventos ao vivo ficam inacessíveis. Esta postagem demonstra como criar um autorizador Serverless de múltiplas regiões tolerante a falhas e, ao mesmo tempo, manter os custos mais baixos em comparação aos ambientes tradicionais.
As arquiteturas multi regionais Serverless geralmente incluem camadas de roteamento, computação e dados. Ao implementar implantações em várias regiões, a replicação de dados nas regiões da AWS é essencial, independentemente dos serviços computacionais usados. A camada computacional deve priorizar a idempotência para garantir o processamento seguro de eventos em todas as regiões da AWS. Use o Powertools for Lambda para gerenciar a idempotência de forma eficiente ou implemente soluções personalizadas usando IDs de eventos exclusivos com o DynamoDB as an idempotency repository. Embora esta postagem se concentre na implementação do serviço autorizador, esse padrão pode ser aplicado para criar microsserviços multi regionais que lidam com várias funções críticas, como gerenciamento de sessões de jogos, orquestração de entrega de conteúdo, gerenciamento de preferências do usuário e serviços de perfil.
Visão geral da demonstração
Para demonstrar a operação do autorizador Serverless em várias regiões, podemos examinar o fluxo de trabalho:
- O aplicativo de frontend se autentica com o provedor de identidade para obter um token de autenticação.
- O token de autenticação é enviado para um endpoint DNS de múltiplas regiões resiliente, hospedado no Route 53 nesta demonstração.
- O Route 53 encaminha a solicitação com o token para o API Gateway na região primária.
- O Route 53 monitora a integridade do aplicativo usando uma função simulada do Lambda neste exemplo. Em ambientes de produção, implemente verificações de integridade detalhadas para monitorar toda a pilha de serviços.
- Após a autorização bem-sucedida, o aplicativo recebe uma resposta. Se o Route 53 detectar comprometimento da região primária, ele acionará os alarmes do Amazon CloudWatch, que os proprietários do aplicativo podem usar para avaliar e aprovar o redirecionamento de tráfego para a região secundária.
- Novas rotas de tráfego para o API Gateway na região secundária após a aprovação manual do failover.
- As verificações de saúde do Route 53 continuam monitorando a saúde da região primária e restauram o tráfego de solicitações quando a região se recupera.
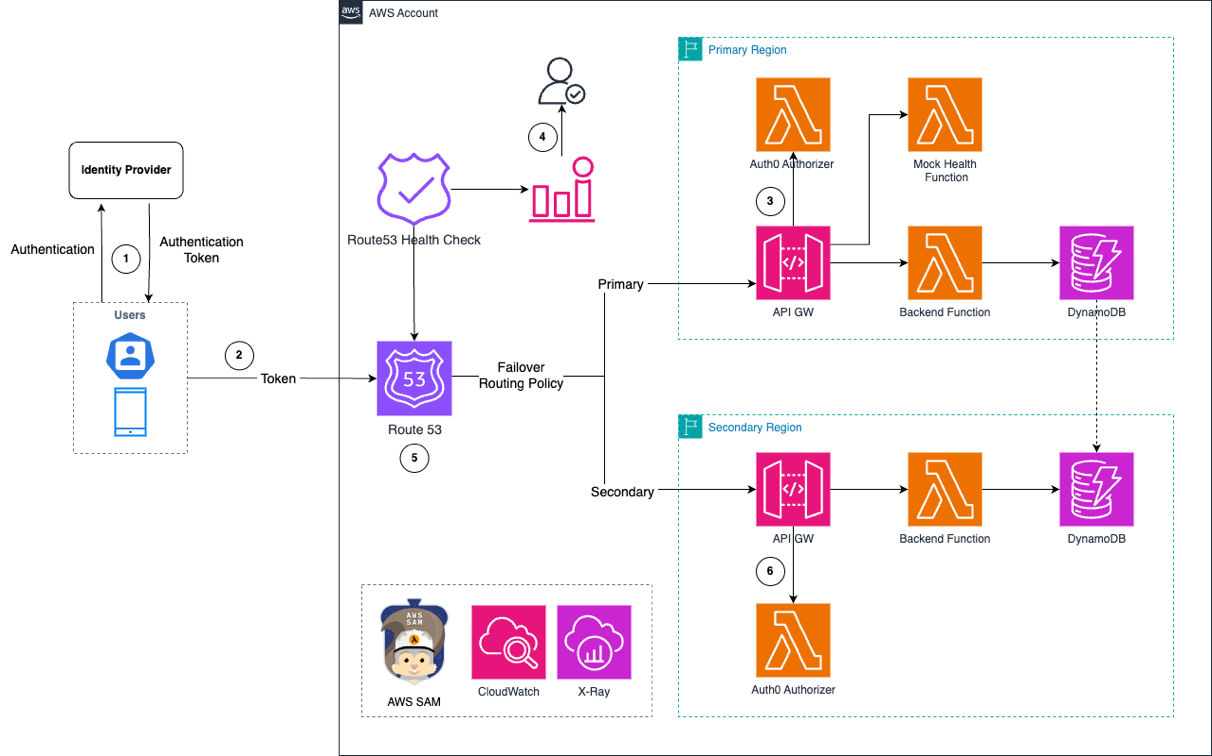
Figura 3: Fluxo de trabalho do autorizador Serverless em várias regiões com failover do Route 53 entre as regiões primária e secundária
A figura anterior mostra a arquitetura, que demonstra os recursos de failover e fallback por meio de alarmes do CloudWatch e de um processo de aprovação manual. Essa abordagem se alinha às melhores práticas para aplicativos essenciais, nos quais o failover automatizado não é recomendado, apesar de ser tecnicamente possível. As equipes podem usar essa abordagem para avaliar a prontidão técnica, avaliar o impacto nos negócios e tomar decisões comerciais informadas sobre o tempo e as possíveis implicações de receita. A demonstração implementa um autorizador Serverless de múltiplas regiões que serve como uma arquitetura de referência. As implementações no mundo real devem avaliar cuidadosamente as estratégias de failover com base na importância dos negócios e nos requisitos operacionais.
Testando cenários multirregionais
O aplicativo de exemplo hospeda seu frontend no Amazon Elastic Container Service (Amazon ECS). A configuração da verificação de integridade do Route 53 neste GitHub define os principais parâmetros de failover:
- FailureThreshold: especifica o número de falhas consecutivas na verificação de integridade antes que o Route 53 marque um endpoint como não íntegro
- Intervalo de solicitação:
- Padrão: intervalo de 30 segundos (0,50 USD por exame de saúde/mês)
- Rápido: intervalos de 10 segundos ($1,00 por exame de saúde/mês)
O intervalo mais rápido permite uma detecção mais rápida de falhas. No entanto, ele aumenta os custos de verificação de integridade por meio de mais recursos de registro, tratamento de solicitações e computação de backend. Problemas temporários, como falhas na rede, erros transitórios ou atrasos na dependência de terceiros, podem ser resolvidos em minutos. A implementação de um tratamento eficaz de novas tentativas introduz complexidades desnecessárias e possíveis inconsistências de dados. Escolha o intervalo adequado com base nos SLAs de sua empresa e nas considerações de custo.
Para testar cenários de failover, a arquitetura usa uma função Lambda simulada como endpoint de verificação de integridade. Acionamos os alarmes do CloudWatch simulando um código de status de resposta de 500 dessa função, que solicita o processo manual de decisão de failover, conforme mostrado na figura a seguir.

Figura 4. Captura de tela do console mostrando a verificação de integridade de várias autorizações com o status “Não íntegro”
O cache do DNS ocorre em vários níveis (navegador, sistema operacional, ISP e VPN). Para observar o comportamento de failover imediatamente, limpe os caches do resolvedor de DNS em cada nível
Para testes de resiliência mais abrangentes, considere a implementação de práticas de engenharia do caos. Você pode usar a extensão chaos-lambda para introduzir a latência ou modificar as respostas da função de forma controlada. O AWS Fault Injection Service (AWS FIS), um serviço totalmente gerenciado, permite experimentos de injeção de falhas para melhorar a resiliência, o desempenho e a observabilidade do aplicativo. A combinação dessas ferramentas ajuda a validar suas arquiteturas multi regionais sob várias condições de falha controladas.
Observabilidade em implantações em multiplas regiões
A implementação de uma arquitetura de múltiplas regiões é apenas a primeira etapa. A observabilidade entre regiões exige o monitoramento dos recursos da Região A a partir da Região B e vice-versa. O CloudWatch permite isso por meio do monitoramento entre contas e regiões, fornecendo registros e métricas consolidados em um único painel. Implemente verificações de saúde detalhadas para verificar a funcionalidade crítica do aplicativo em todas as regiões da AWS.
Embora os serviços Serverless da AWS sejam distribuídos, identificar as falhas exatas exige a combinação de vários pontos de dados. Os alarmes compostos do CloudWatch ajudam a agregar esses insights, facilitando assim decisões informadas. Considere implementar soluções de monitoramento personalizadas para rastreamento de solicitações de ponta a ponta em todas as regiões da AWS. Essa visão abrangente ajuda a gerenciar a complexidade da complexidade de múltiplas regiões e fornece respostas rápidas a possíveis problemas.
Conclusão
A criação de aplicativos multi regionais resilientes exige considerações cuidadosas sobre padrões de arquitetura, custos e complexidades operacionais. Os serviços Serverless da AWS, com seu modelo de pagamento por valor, reduzem significativamente os desafios da implementação de arquiteturas multirregionais. O padrão do autorizador demonstrado nesta publicação mostra como as organizações podem alcançar alta disponibilidade sem a sobrecarga tradicional da infraestrutura ociosa. As equipes podem seguir esses padrões arquitetônicos e as melhores práticas para criar soluções robustas e econômicas que mantenham a disponibilidade do serviço durante interrupções no serviço.
Para aprender os conceitos de resiliência, visite o AWS Developer Center. O código-fonte completo da demonstração usada nesta postagem está disponível em nosso repositório do GitHub. Para expandir seu conhecimento Serverless, visite Serverless Land.
Este conteúdo foi traduzido da postagem original do blog, que pode ser encontrada aqui.
Autor
 |
Vamsi Vikash Ankam é arquiteto sênior de soluções para Serverless na Amazon Web Services. |
Tradutoes
 |
Daniel Abib é Arquiteto de Soluções Sênior e Especialista em Amazon Bedrock na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e especialização em Machine Learning. Ele trabalha apoiando Startups, ajudando-os em sua jornada para a nuvem. |
 |
Rodrigo Peres é Arquiteto de Soluções na AWS, com mais de 20 anos de experiência trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados. |