O blog da AWS
Lidar com tempos de processamento imprevisíveis com consistência operacional ao integrar serviços AWS assíncronos com uma máquina de estados do AWS Step Functions
Por Maria John, Arquiteta de Soluções Sênior na Amazon Web Services e Philip Whiteside, Arquiteto de Soluções Sênior na Amazon Web Services.
Integrar serviços AWS assíncronos com uma máquina de estados do AWS Step Functions apresenta um desafio ao construir aplicações serverless na Amazon Web Services (AWS). Serviços como Amazon Translate, Amazon Macie e Amazon Bedrock Data Automation (BDA) se destacam no tratamento de operações de longa duração que podem levar mais de 10 minutos para serem concluídas devido à sua natureza assíncrona. Serviços assíncronos retornam uma resposta 200 OK imediata, indicando que a solicitação foi bem-sucedida, após o envio do trabalho (veja a sintaxe de resposta da API de StartTextTranslationJob no Amazon Translate, CreateClassificationJob no Macie e InvokeDataAutomationAsync no BDA), em vez de aguardar a conclusão real da tarefa e os resultados.
Nesta publicação, exploramos o uso de máquinas de estados do AWS Step Functions com serviços AWS assíncronos, examinamos alguns cenários onde o tempo de processamento pode ser imprevisível, explicamos quando soluções tradicionais como polling (verificação periódica) ficam aquém, e demonstramos como implementar um padrão de callback generalizado para lidar com operações assíncronas em um fluxo síncrono mais gerenciável. Cobrimos a arquitetura relacionada, implementação técnica e melhores práticas, e fornecemos exemplos do mundo real que usam o AWS Cloud Development Kit (AWS CDK). Os serviços usados neste padrão de callback generalizado incluem Amazon DynamoDB, Amazon EventBridge e AWS Step Functions.
Compreendendo o problema que esta solução aborda
Operações assíncronas são projetadas para lidar com operações de longa duração sem bloquear recursos, um design seguido por muitos serviços AWS. No entanto, esses serviços criam desafios em fluxos de trabalho do Step Functions ao retornar respostas 200 OK imediatas em vez de confirmar a conclusão da tarefa. Isso quebra o modelo de execução do Step Functions, que espera que cada etapa seja concluída antes de avançar. Os desenvolvedores frequentemente tentam resolver esse problema por meio de loops de polling para verificar repetidamente o status das operações, uma abordagem que funciona para aplicações em containers e Amazon Elastic Compute Cloud (Amazon EC2). Para esses serviços, os recursos de computação já estão provisionados, mas os recursos de computação se tornam problemáticos em arquiteturas Serverless quando as funções do AWS Lambda têm um limite de execução de 15 minutos, tornando-as inadequadas para polling de longa duração.
O Step Functions suporta Run a Job (.sync) para chamar um serviço e fazer com que o Step Functions aguarde a conclusão de um trabalho, mas isso funciona apenas para integrações otimizadas selecionadas. No entanto, essa funcionalidade é limitada a serviços AWS específicos, como AWS Glue. Amazon Translate, Macie e outros serviços não são integrações otimizadas. Se sua operação não estiver listada como funcionando com .sync, ela pode se beneficiar do padrão de callback generalizado abordado neste post.
Para essas integrações não otimizadas, uma opção é usar polling (verificação periódica). No entanto, o polling pode levar a latência adicional na resposta porque os tempos de polling provavelmente não se alinham com a conclusão do trabalho. Isso é mostrado na figura a seguir.
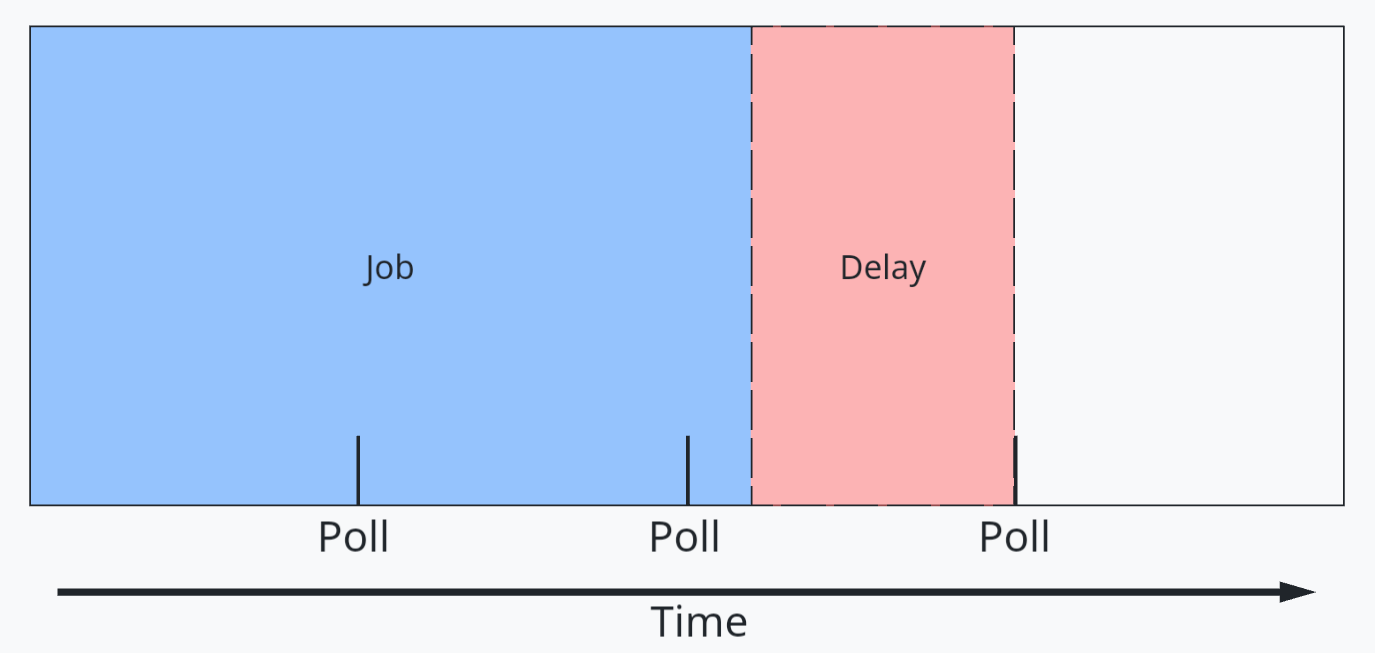
Figura 1: Um diagrama de linha do tempo de processamento de trabalho e atraso
O padrão de callback generalizado do Step Functions pode resolver esse problema de latência pausando a execução por até um ano enquanto aguarda a conclusão da tarefa (isso não incorre em custo adicional). Quando tal operação assíncrona termina, um mecanismo de callback retoma o fluxo de trabalho de onde parou. Este padrão de callback generalizado transforma operações assíncronas em síncronas e mantém a eficiência de custos e agilidade operacional.
Cenários
Para nos ajudar a ver onde este padrão de callback generalizado poderia ser aplicado, vamos examinar alguns cenários. Cada um desses cenários faz uso de máquinas de estados do AWS Step Functions para executar os fluxos de trabalho das aplicações.
Cenário 1: Tradução de documentos com conformidade de informações pessoalmente identificáveis
As organizações devem gerenciar informações pessoalmente identificáveis (PII) ao traduzir documentos porque as PII podem ser duplicadas nas saídas de idiomas. Por exemplo, ao traduzir um documento contendo “Jane Doe”, esse nome aparece tanto na versão original quanto na traduzida, criando múltiplas instâncias de dados sensíveis que precisam de medidas de conformidade. A tradução em lote do Amazon Translate tem uma concorrência padrão de 10, o que significa que as traduções podem levar mais de 10 minutos ou ficar em fila por períodos mais longos. Além disso, a operação de tradução em lote do Amazon Translate é assíncrona, mantendo a solicitação de tradução em uma fila até ser concluída. O padrão de callback generalizado nesta publicação garante que os fluxos de trabalho da máquina de estados do Step Functions sejam retomados adequadamente para aplicar tratamento consistente de PII em todas as saídas. Neste cenário, o design faz uso de marcação de arquivos do Amazon Simple Storage Service (Amazon S3) como contendo PII ou não, o que por sua vez associa políticas de ciclo de vida do S3 para períodos de retenção específicos a esses objetos do S3.
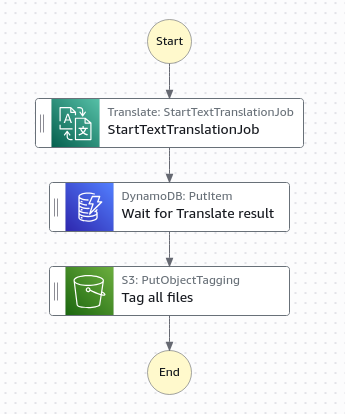
Figura 2: Um diagrama de fluxo de trabalho de tradução de texto
Cenário 2: Usando execução concorrente para pausar a máquina de estados até que os processos sejam concluídos
Continuando do cenário 1, o Macie e o Amazon Translate podem ser executados em paralelo (cada um aproximadamente 10 minutos) em vez de sequencialmente (aproximadamente 20 minutos) para uma melhor experiência do usuário. Semelhante às operações de tradução em lote do Amazon Translate sendo assíncronas, a operação de criação de classificação do Macie também é assíncrona. As máquinas de estados do Step Functions permitem a execução concorrente de ambas as solicitações de serviço. O padrão de callback generalizado permite que a máquina de estados pause cada fluxo de trabalho paralelo e retome apenas quando os serviços assíncronos concluírem seus trabalhos. Sem esse padrão, ambos os serviços retornariam imediatamente respostas 200 OK, fazendo com que o fluxo de trabalho continue prematuramente antes que os resultados de tradução ou classificação estejam disponíveis. Se os resultados de classificação não estiverem disponíveis posteriormente no fluxo de trabalho, as tags PII apropriadas não serão aplicadas e, portanto, a política de retenção de ciclo de vida apropriada também não será aplicada, resultando em não aderência às práticas de tratamento de PII.
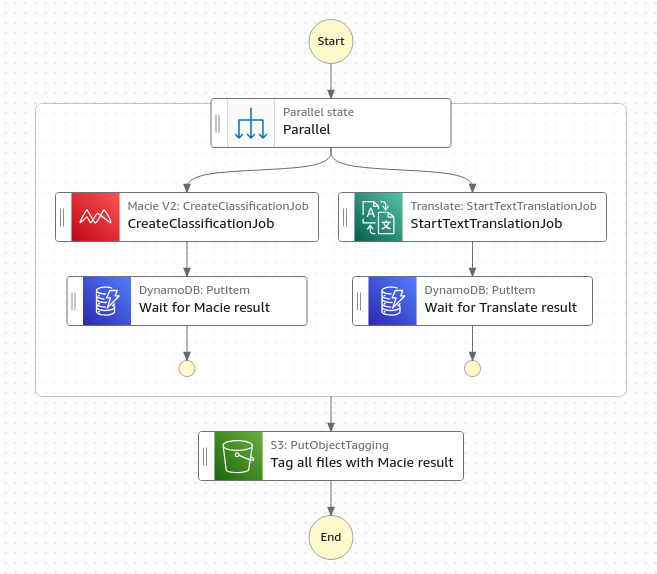
Figura 3: Um diagrama de fluxo de trabalho de classificação e tradução paralelas
Cenário 3: Processamento inteligente de documentos
Organizações que usam o Bedrock Data Automation para processamento inteligente de documentos devem levar em consideração os limites de concorrência regional. O BDA tem limites de concorrência regionais “Número máximo de trabalhos simultâneos” de 25 trabalhos nas regiões us-east-1 e us-west-2. Além disso, o BDA tem um limite de concorrência de apenas cinco trabalhos em outras regiões suportadas, portanto, lotes grandes de documentos podem ficar em fila por períodos prolongados, resultando em longos tempos de espera de processamento para o usuário. Essa funcionalidade de serviço é tratada de forma assíncrona, pois a duração da solicitação pode ser de muitos minutos. O padrão de callback generalizado garante que os fluxos de trabalho sejam retomados adequadamente assim que um trabalho termina, em vez de esperar um tempo arbitrário para verificar se o trabalho foi concluído. Por exemplo, o padrão de callback generalizado para BDA pode ser usado para aprimorar a solução descrita no post do blog, Processamento inteligente de documentos escalável usando Amazon Bedrock Data Automation.
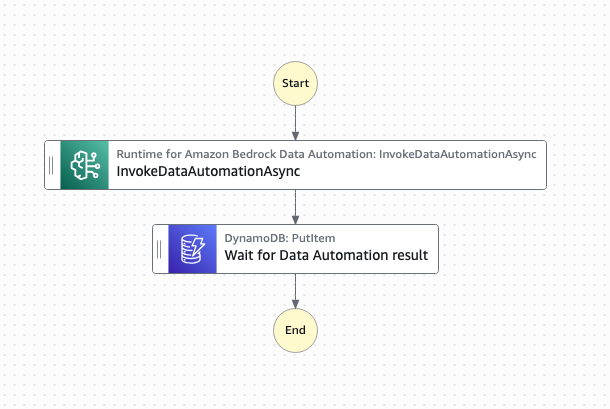
Figura 4: Um diagrama de fluxo de trabalho de automação de dados
Arquitetura da solução
O diagrama de arquitetura a seguir mostra o padrão de callback generalizado (a seção azul no lado direito) integrado com sua aplicação existente (a seção cinza no lado esquerdo).
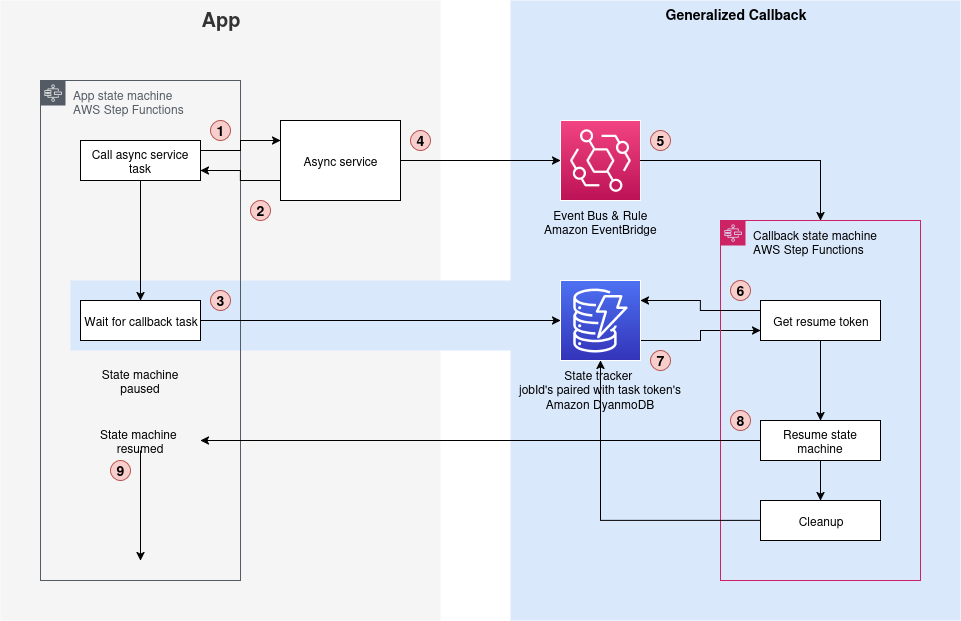
Figura 5: A arquitetura de callback generalizado do Step Functions
Componentes-chave da arquitetura da solução desta publicação
Esta arquitetura de padrão de callback generalizado consiste em quatro componentes essenciais trabalhando juntos. Cada componente desempenha um papel específico enquanto mantém a eficiência de custos e confiabilidade operacional. Os seguintes componentes formam a base deste padrão:
- Tarefa do Step Functions: Implementa o estado de tarefa “Wait for Callback” gerando tokens de tarefa exclusivos para retomada do fluxo de trabalho.
- Regra do EventBridge: Monitora eventos de conclusão de serviços assíncronos e é personalizável para diferentes padrões de serviço. Os serviços AWS fazem uso de um barramento de eventos para rotear notificações de eventos de serviço para outros serviços, como conclusões de trabalhos.
- DynamoDB: Fornece armazenamento persistente correlacionando IDs de trabalho com tokens de tarefa para consulta rápida.
- Máquina de estados do Step Functions: Gerencia o processo de retomada e garante a limpeza adequada dos tokens armazenados.
Processo da solução
Este padrão de callback generalizado opera por meio de uma sequência coordenada de quatro etapas principais. Cada etapa se baseia na anterior. O processo a seguir demonstra como o padrão gerencia a execução do fluxo de trabalho. O diagrama acima mostra etapas mais detalhadas seguindo essas etapas principais.
- Iniciar a operação assíncrona para a qual você deseja aguardar a conclusão. O serviço assíncrono responde com sucesso (200 OK) e a máquina de estados continua. Iniciar uma operação de tradução em lote do Amazon Translate é um exemplo de tal operação assíncrona.
- Acionar o padrão de callback generalizado com a capacidade “Wait for Callback“. Emparelhe o token de tarefa com o jobId no DynamoDB usando o jobId exclusivo como chave primária. Exemplo:
- Monitorar a conclusão: Quando o serviço assíncrono conclui o trabalho solicitado, como tradução de documentos, um evento é criado no EventBridge que contém o jobId e o status. Exemplo:
- Retomar o fluxo de trabalho: A regra do EventBridge aciona o fluxo de trabalho para retomar, que procura o token de tarefa usando o jobId, retoma a execução pausada do Step Functions e limpa a entrada do banco de dados.
Nem todo serviço cria eventos para cada ação, portanto, valide se sua operação de serviço gera os eventos esperados. Por exemplo, o Macie não cria eventos quando nenhuma descoberta é encontrada. Nesses casos, implemente mecanismos adicionais de geração de eventos por meio de assinaturas de Amazon CloudWatch Logs que acionam funções Lambda para criar eventos personalizados.
Implementação técnica da solução
Para implantação rápida da solução desta publicação, os usuários do AWS CDK podem usar este padrão CDK de exemplo com todos os componentes principais. Alternativamente, você pode implementar os componentes individuais por conta própria usando as etapas a seguir, com cada componente personalizável para seus requisitos.
Alguns dos trechos baseados em JSON abaixo são trechos de Amazon States Language (ASL), que é a linguagem que define uma máquina de estados do AWS Step Functions. As máquinas de estados podem ser construídas no Console da AWS usando o construtor visual de arrastar e soltar, ou com ASL. O construtor visual gera este ASL e você pode alternar para visualizar/editar o código do fluxo de trabalho (ASL).
Use uma tarefa do Step Functions que suporte “WaitForCallback” para armazenar o token de tarefa no DynamoDB
Use uma tarefa do Step Functions que suporte “WaitForCallback” para armazenar o token de tarefa no DynamoDB junto com o ID do trabalho do serviço assíncrono.
Os serviços AWS geram um ID exclusivo para esse serviço que se refere a esse trabalho/solicitação/ação. O DynamoDB mantém os mapeamentos entre IDs de trabalho e tokens de tarefa, suportando múltiplas máquinas de estados pausadas em paralelo com execução concorrente. Para evitar conflitos quando diferentes serviços assíncronos geram IDs sobrepostos (por exemplo, se o Serviço A e o Serviço B geram o ID “12345”), use tabelas DynamoDB separadas para cada serviço para manter a exclusividade do ID. O padrão AWS CDK de exemplo demonstra essa abordagem fornecendo tabelas DynamoDB dedicadas e máquinas de estados do Step Functions para cada integração de serviço. Essa estrutura ID-token permite consultas rápidas para retomada e limpeza do fluxo de trabalho.
O ASL a seguir realiza isso usando uma tarefa DynamoDB PutItem:
Neste exemplo, o objeto Item armazena três valores: o ID do trabalho ($.JobId), o token de tarefa ($$.Task.Token) e um valor TTL ($.ttl). O campo ttl configura o Time to Live para limpeza automática com base no tempo de conclusão esperado do seu serviço. Como isso armazena apenas três pequenos valores de string, o uso de dados por entrada é mínimo. A consideração principal é o número de operações simultâneas, pois cada trabalho assíncrono ativo requer uma entrada do DynamoDB até a conclusão ou expiração do TTL.
A tabela DynamoDB usa “id” como chave primária e inclui um atributo “token“. Esses campos são essenciais para o padrão “WaitForCallback“: o “id” (ID do trabalho) permite que seu serviço assíncrono procure a entrada correta, enquanto o “token” (token de tarefa do Step Functions) é o que seu serviço envia de volta ao Step Functions para retomar o fluxo de trabalho pausado. O JSON a seguir mostra um exemplo desses valores:
Quando seu serviço assíncrono conclui seu trabalho, ele recupera o token de tarefa usando o ID do trabalho e, em seguida, chama o Step Functions com esse token para retomar a execução de onde pausou.
O token de tarefa atua como um identificador exclusivo para retomar a execução no ponto exato de pausa. Para evitar a substituição de um registro existente quando um id duplicado é usado, você pode especificar uma “ConditionExpression”. Este ASL mostra apenas a ConditionExpression.
Criar uma regra do EventBridge para monitorar padrões de eventos do seu serviço assíncrono
A integração do EventBridge forma o coração do mecanismo de retomada orientado a eventos. Você pode criar regras do EventBridge para monitorar padrões de eventos específicos de serviços AWS assíncronos. A maioria dos serviços AWS publica automaticamente eventos de conclusão no EventBridge padrão sem custo, e você pode usar o assistente de regras do EventBridge para identificar padrões de eventos corretos. Para serviços que não publicam eventos—como o Macie que não cria eventos quando nenhuma descoberta é encontrada—implemente shims usando Amazon CloudWatch Logs para acionar funções Lambda que geram eventos personalizados. Este JSON mostra a definição de padrão de regra do EventBridge.
Retomar o fluxo de trabalho
Neste ponto, você sabe que a operação foi concluída, então pode retomar o fluxo de trabalho com segurança. Usando o ID do trabalho, chame a operação DynamoDB GetItem para receber o token de tarefa. Este ASL mostra a definição de tarefa para obter o token de tarefa para um determinado ID de trabalho recuperado da notificação de evento.
Use o token de tarefa para retomar o fluxo de trabalho e, em seguida, exclua a entrada do DynamoDB para limpeza. Este ASL mostra a definição de tarefa para usar o token de tarefa para retomar a máquina de estados no ponto onde ela foi pausada.
Este ASL mostra a definição de tarefa para limpar o DynamoDB para remover o token de tarefa usado.
Isso completa a implementação técnica de nossa solução. Com todos os componentes em vigor—a tarefa WaitForCallback, regras do EventBridge, lógica de retomada do fluxo de trabalho e armazenamento DynamoDB—você agora tem uma implementação de padrão de callback generalizado totalmente funcional que elimina o polling e gerencia eficientemente operações assíncronas.
Agora que estabelecemos como implementar o padrão de callback generalizado tecnicamente, vamos explorar as melhores práticas e considerações importantes que ajudarão você a otimizar e proteger sua implementação.
Melhores práticas e considerações
Ao implementar o padrão de callback generalizado no AWS Step Functions, é essencial entender e aplicar melhores práticas que otimizam custos, aprimoram a segurança e garantem operação eficiente. Esta seção descreve considerações principais e recomendações para implementar o padrão de forma eficaz, focando em estratégias de otimização de custos e medidas de segurança que ajudam a manter um fluxo de trabalho serverless robusto e seguro. Seguindo essas diretrizes, você pode maximizar os benefícios do padrão de callback generalizado enquanto minimiza riscos potenciais e despesas desnecessárias.
Otimizar custos usando o padrão de callback generalizado deste post
Gerenciar custos para operações assíncronas de longa duração pode apresentar desafios. O polling tradicional acumula despesas desnecessárias por meio de transições de estado repetidas e tempo de execução, mas a abordagem orientada a eventos do padrão de callback generalizado desta publicação reduz significativamente os custos operacionais.
Eliminar custos de polling e minimizar o tempo de execução
O padrão de callback generalizado reduz custos eliminando transições de polling e pausando a execução durante períodos de espera. Para fluxos de trabalho padrão cobrados a $0,000025 por transição de estado, usar apenas duas transições em vez de polling contínuo alcança aproximadamente uma redução de custos de 87%. Um trabalho de tradução de 15 minutos fazendo polling a cada minuto precisaria de 15 transições em oposição a duas com o padrão de callback generalizado. Para fluxos de trabalho expressos cobrados a $0,000001 por solicitação e $0,00001667 por GB-segundo, o padrão oferece economias significativas por meio de contagem de solicitações reduzida e tempo de execução mínimo. O polling tradicional mantém os fluxos de trabalho ativos durante toda a operação, acumulando cobranças de tempo de execução. Em contraste, o padrão de callback generalizado elimina cobranças de tempo de execução durante o período de espera. No exemplo de trabalho de tradução mencionado anteriormente neste parágrafo, isso poderia reduzir o tempo de execução de mais de 15 minutos para apenas os segundos necessários para iniciar trabalhos e concluir processos.
Aumentar a eficiência de recursos
O padrão de callback aumenta a eficiência de recursos removendo o polling constante, resultando em redução substancial no registro do CloudWatch e custos de monitoramento associados. Isso cria uma solução mais econômica com uma pegada reduzida de recursos AWS.
Otimizar ainda mais os custos do padrão de callback
Aprimore a eficiência de custos por meio de otimizações do DynamoDB. Escolha o modo sob demanda para cargas de trabalho imprevisíveis ou modo provisionado com escalonamento automático para padrões consistentes, configure as configurações de escalonamento automático com base no uso e implemente TTL para remover automaticamente itens expirados sem consumir capacidade de gravação.
Considerações de segurança para o padrão de callback
O padrão de callback envolve armazenar tokens de tarefa, processar eventos e gerenciar a retomada do fluxo de trabalho em vários serviços AWS. Implementar controles de acesso adequados é essencial para proteger a integridade de seus fluxos de trabalho e prevenir acesso não autorizado ou manipulação dos componentes do padrão.
Esta seção descreve as considerações de segurança para o padrão de callback, focando em controles de acesso para armazenamento de dados e processamento de eventos.
Segurança de armazenamento de dados
Habilite a criptografia em repouso do DynamoDB usando chaves do AWS Key Management Service (AWS KMS) de propriedade da AWS ou gerenciadas pelo usuário. Implemente políticas baseadas em identidade definindo as ações da função AWS Identity and Access Management (IAM) do Step Functions (como PutItem, GetItem e DeleteItem) e políticas baseadas em recursos que especificam quais principais do IAM podem acessar a tabela. Juntas, essas medidas garantem que apenas máquinas de estados autorizadas acessem o armazenamento de tokens e as operações sejam limitadas a permissões mínimas. Além disso, configure o TTL para remover automaticamente tokens expirados para que esses tokens não sejam reutilizados acidentalmente, o que pode resultar em erros ao retomar os fluxos de trabalho relevantes do AWS Step Functions.
Segurança de processamento de eventos
Defina o escopo das regras do EventBridge precisamente para corresponder apenas a eventos necessários específicos. Para conclusão de trabalho do Amazon Translate, as regras devem corresponder explicitamente apenas a eventos de conclusão de trabalho de tradução, evitando assim acionamentos não autorizados. As funções do IAM devem seguir os princípios de privilégio mínimo para que apenas ações específicas possam fazer com que os fluxos de trabalho sejam retomados.
Conclusão
O padrão de callback apresentado nesta publicação fornece uma solução para gerenciar operações assíncronas de longa duração em arquiteturas Serverless. Você pode usar o estado de tarefa “Wait for Callback” do Step Functions com EventBridge e DynamoDB para transformar serviços assíncronos em fluxos de trabalho síncronos sem a sobrecarga do polling. Este padrão reduz custos, melhora a eficiência por meio de arquitetura orientada a eventos e mantém a segurança por meio de controles de acesso adequados. Você pode usar a implementação CDK fornecida para implementar este padrão e adaptá-lo às suas necessidades específicas enquanto segue as práticas recomendadas de segurança e otimização de custos.
Este conteúdo foi traduzido da publicação original do blog, que pode ser encontrado aqui.
Autores
 |
Maria John é uma Arquiteta de Soluções Sênior na Amazon Web Services, ajudando clientes a construir soluções na AWS. |
 |
Philip Whiteside é um Arquiteto de Soluções Sênior na Amazon Web Services. Philip é apaixonado por superar barreiras utilizando tecnologia. |
Tradutores
 |
Daniel Abib é Arquiteto de Soluções Sênior e Especialista em Amazon Bedrock na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e especialização em Machine Learning. Ele trabalha apoiando Startups, ajudando-os em sua jornada para a nuvem. |
 |
Rodrigo Peres é Arquiteto de Soluções na AWS, com mais de 20 anos de experiência trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados. |