AWS News Blog
Introducing Amazon Redshift Serverless – Run Analytics At Any Scale Without Having to Manage Data Warehouse Infrastructure

|
We’re seeing the use of data analytics expanding among new audiences within organizations, for example with users like developers and line of business analysts who don’t have the expertise or the time to manage a traditional data warehouse. Also, some customers have variable workloads with unpredictable spikes, and it can be very difficult for them to constantly manage capacity.
With Amazon Redshift, you use SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes. Today, I am happy to introduce the public preview of Amazon Redshift Serverless, a new capability that makes it super easy to run analytics in the cloud with high performance at any scale. Just load your data and start querying. There is no need to set up and manage clusters. You pay for the duration in seconds when your data warehouse is in use, for example, while you are querying or loading data. There is no charge when your data warehouse is idle.
Amazon Redshift Serverless automatically provisions the right compute resources for you to get started. As your demand evolves with more concurrent users and new workloads, your data warehouse scales seamlessly and automatically to adapt to the changes. You can optionally specify the base data warehouse size to have additional control on cost and application-specific SLAs.
With the new serverless option, you can continue to query data in other AWS data stores, such as Amazon Simple Storage Service (Amazon S3) data lakes and Amazon Aurora and Amazon Relational Database Service (Amazon RDS) databases.
Amazon Redshift Serverless is ideal when it is difficult to predict compute needs such as variable workloads, periodic workloads with idle time, and steady-state workloads with spikes. This approach is also a good fit for ad-hoc analytics needs that need to get started quickly and for test and development environments.
Let’s see how this works in practice.
Using Amazon Redshift Serverless
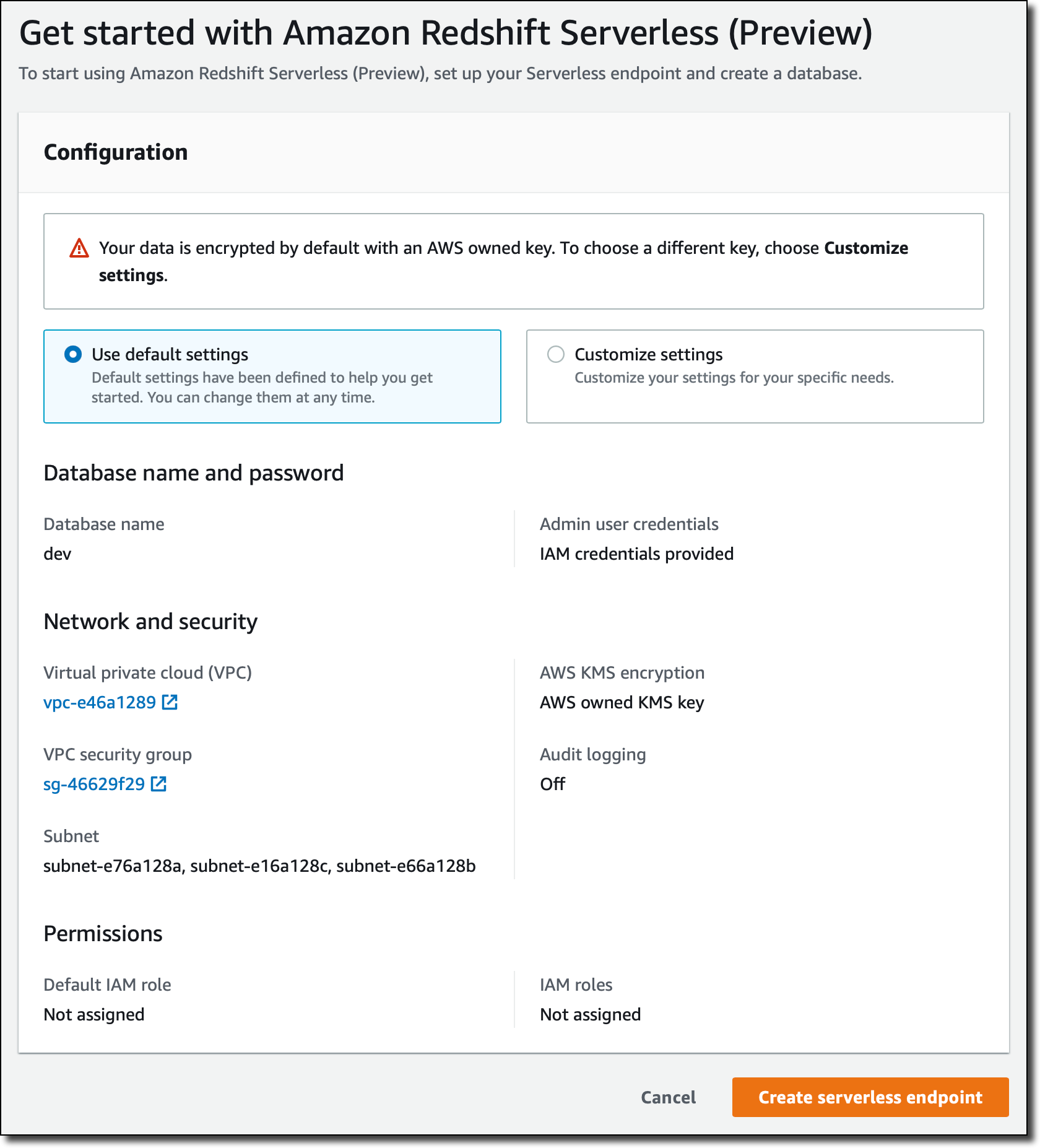
I go to the Amazon Redshift console and choose the new serverless option. The first time, I set up the serverless endpoint and configure networking and security.
I confirm the default settings that use all subnets in my default Amazon Virtual Private Cloud (Amazon VPC) and its default security group. Data is always encrypted, and I use the default AWS-owned key. Optionally, I can customize all settings. I can associate now or later the AWS Identity and Access Management (IAM) roles to give permissions to access other AWS resources, for example, to be able to load data from an S3 bucket. The configuration of the serverless endpoint will be shared by all my serverless data warehouses in the same AWS account and Region.
To query data, I use Amazon Redshift Query Editor V2, a new free web-based tool that we made available a few months back. The query editor provides quick access to a few sample datasets to make it easy to learn Amazon Redshift’s SQL capabilities: TPC-H, TPC-DS, and tickit, a dataset containing information on ticket sales for events.
For a quick test, I use the tickit sample dataset so I don’t need to load any data. I prepare a query to get the list of tickets sold per date, sorted to see the dates with more sales first:
SELECT caldate, sum(qtysold) as sumsold
FROM tickit.sales, tickit.date
WHERE sales.dateid = date.dateid
GROUP BY caldate
ORDER BY sumsold DESC;By using the web-based query editor, I don’t need to configure a SQL client or set up the network permissions to reach the serverless endpoint. Instead, I just write my SQL query and run it.

I am a visual person. I enable the Chart option on the right of the result table and select a bar chart.

Satisfied with the clarity of the chart, I export it as an image file. In this way, I can quickly share it or include it in a report.

Amazon Redshift Serverless supports all rich SQL functionality of Amazon Redshift such as semi-structured data support. I can use any JDBC/ODBC-compliant tool or the Amazon Redshift Data API to query my data. To migrate data, I can take a snapshot of an Amazon Redshift provisioned cluster and restore it as serverless. Then, I just need to update my SQL applications to use the new serverless endpoint.
Availability and Pricing
Amazon Redshift Serverless is available in public preview in the following AWS Regions: US East (Ohio, N. Virginia), US West (N. California, Oregon), Europe (Frankfurt, Ireland), Asia Pacific (Tokyo).
With Amazon Redshift Serverless, you pay separately for the compute and storage you use. Compute capacity is measured in Redshift Processing Units (RPUs), and you pay for the workloads in RPU-hours with per-second billing. For storage, you pay for data stored in Amazon Redshift-managed storage and storage used for snapshots, similar to what you’d pay with a provisioned cluster using RA3 instances.
To control your costs, you can specify usage limits and define actions that Amazon Redshift automatically takes if those limits are reached. You can specify usage limits in RPU-hours and associated with a daily, weekly, or monthly duration. Setting higher usage limits can improve the overall throughput of the system, especially for workloads that need to handle high concurrency while maintaining consistently high performance.
Compute resources automatically shutdown behind the scenes when there is no activity and resume when you are loading data, or there are queries coming in. When accessing your S3 data lake via the new serverless endpoint, you do not pay for Amazon Redshift Spectrum separately. You have a unified serverless experience and pay for data lake queries also in RPU-seconds. For more information, see the Amazon Redshift pricing page.
The serverless end point is configured at the AWS account level. If you have multiple teams or projects and want to manage costs separately, you can use separate AWS accounts. You can share data between your provisioned clusters and serverless endpoint and between serverless endpoints across accounts.
To help you get practice, we provide you upfront with $500 in AWS credits to try the Amazon Redshift Serverless public preview. You get the credits when you first create a database with Amazon Redshift Serverless. These credits are used to cover your costs for compute, storage, and snapshot usage of Amazon Redshift Serverless only.
— Danilo