- Amazon Redshift
- Tính năng
- Tích hợp cho Apache Spark
Tích hợp Amazon Redshift cho Apache Spark
Xây dựng các ứng dụng Apache Spark đọc và ghi dữ liệu từ Amazon Redshift
Tại sao nên sử dụng Tích hợp Amazon Redshift cho Apache Spark?
Lợi ích của Amazon Redshift
-
Mở rộng phạm vi nguồn dữ liệu mà bạn có thể sử dụng trong các phân tích và ứng dụng máy học (ML) phong phú chạy trong Amazon EMR, AWS Glue hoặc SageMaker bằng cách đọc từ và ghi dữ liệu vào kho dữ liệu của bạn.
-
Hợp lý hóa quy trình thiết lập bộ kết nối chưa được chứng nhận và trình điều khiển JDBC vốn rườm rà và thủ công, giảm thời gian chuẩn bị cho các tác vụ phân tích và ML.
-
Sử dụng một số chức năng đẩy xuống như sắp xếp, tổng hợp, giới hạn, kết nối và vô hướng để chỉ di chuyển dữ liệu có liên quan từ kho dữ liệu Amazon Redshift.
Cách thức hoạt động
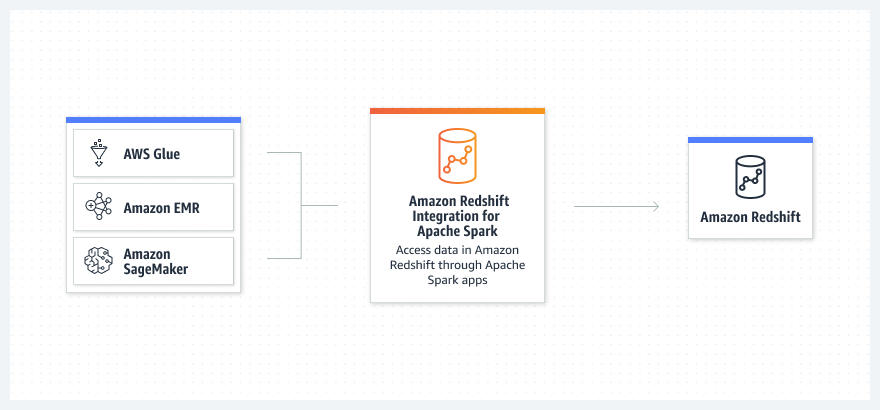
Trường hợp sử dụng
-
Tạo các ứng dụng Apache Spark bằng Java, Scala và Python bằng các dịch vụ phân tích AWS dựa trên Apache Spark.
-
Đọc và ghi dữ liệu vào và từ Amazon Redshift bằng các dịch vụ Amazon EMR, AWS Glue, SageMaker, AWS analytics và ML.
-
Sử dụng Amazon EMR hoặc AWS Glue để lấy mã khung dữ liệu từ sổ tay hoặc tác vụ Apache Spark rồi kết nối với Amazon Redshift.
-
Hợp lý hóa quy trình mà không cần cài đặt hoặc kiểm thử, đồng thời sở hữu độ bảo mật nâng cao (thông tin chứng thực dựa trên IAM), các tính năng đẩy xuống trong hoạt động và định dạng tệp Parquet để đạt được hiệu năng.
Khách hàng
Corey Johnson, Giám đốc kiến trúc dữ liệu – Huron Consulting
Huron là công ty dịch vụ chuyên nghiệp toàn cầu hợp tác với khách hàng để biến khả năng thành hiện thực bằng cách tạo ra các chiến lược hợp lý, tối ưu hóa hoạt động, đẩy nhanh quá trình chuyển đổi kỹ thuật số và hỗ trợ các doanh nghiệp cũng như đội ngũ nhân sự làm chủ tương lai của mình.
“Chúng tôi hỗ trợ các kỹ sư xây dựng ứng dụng và quy trình dữ liệu với Apache Spark bằng Python và Scala. Chúng tôi muốn có một giải pháp phù hợp, giúp đơn giản hóa các hoạt động, có thể cung cấp nhanh hơn và hiệu quả hơn đến khách hàng của mình. Tích hợp Amazon Redshift mới cho Apache Spark chính là giải pháp như vậy”.
Alcuin Weidus, Kiến trúc sư dữ liệu chính cấp cao – GE Aerospace
GE Aerospace là nhà cung cấp toàn cầu về động cơ phản lực, linh kiện và hệ thống cho máy bay thương mại và quân sự. Công ty đã thiết kế, phát triển và sản xuất động cơ phản lực kể từ Thế chiến I.
“GE Aerospace đã sử dụng phân tích AWS và Amazon Redshift để cung cấp thông tin chuyên sâu quan trọng về kinh doanh, giúp công ty đưa ra các quyết định kinh doanh quan trọng. Với tính năng hỗ trợ tự động sao chép từ Amazon S3, chúng tôi có thể xây dựng các quy trình dữ liệu đơn giản hơn để di chuyển dữ liệu từ Amazon S3 sang Amazon Redshift. Điều này giúp các nhóm sản phẩm dữ liệu của chúng tôi tăng tốc độ truy cập dữ liệu và cung cấp thông tin chuyên sâu cho người dùng cuối. Chúng tôi đã dành nhiều thời gian hơn cho việc gia tăng giá trị thông qua dữ liệu và giảm bớt thời gian vào hoạt động tích hợp”.
Neema Raphael, Giám đốc dữ liệu – Goldman Sachs
Goldman Sachs Group, Inc. là tổ chức tài chính hàng đầu thế giới cung cấp nhiều loại dịch vụ tài chính về ngân hàng đầu tư, chứng khoán, quản lý đầu tư và ngân hàng tiêu dùng cho cơ sở khách hàng lớn và đa dạng, bao gồm các tập đoàn, tổ chức tài chính, chính phủ và cá nhân.
“Trọng tâm của chúng tôi là cung cấp quyền truy cập tự phục vụ vào dữ liệu cho tất cả người dùng tại Goldman Sachs. Thông qua Legend, nền tảng quản trị và quản lý dữ liệu mã nguồn mở của mình, chúng tôi hỗ trợ người dùng phát triển các ứng dụng tập trung vào dữ liệu và khai thác những thông tin chuyên sâu dựa trên dữ liệu khi chúng tôi cộng tác trong ngành dịch vụ tài chính. Với tích hợp Amazon Redshift cho Apache Spark, đội ngũ nền tảng dữ liệu của chúng tôi sẽ có thể truy cập dữ liệu Amazon Redshift với ít bước thủ công nhất, từ đó chúng tôi có thể sử dụng ETL không cần mã để nâng cao khả năng giúp các kỹ sư dễ dàng tập trung vào việc hoàn thiện quy trình làm việc hơn, đồng thời thu thập thông tin đầy đủ và kịp thời. Chúng tôi hy vọng sẽ thấy được sự cải thiện trong các ứng dụng cũng như trong độ bảo mật, vì giờ đây người dùng có thể dễ dàng truy cập dữ liệu mới nhất trong Amazon Redshift”.
Hôm nay, bạn đã tìm thấy nội dung mình cần chưa?
Chia sẻ với chúng tôi để chúng tôi có thể cải thiện chất lượng nội dung trên trang