Analytics on AWS
A comprehensive set of capabilities for every analytics workload, optimized for price performance and scale
Overview
AWS offers a comprehensive set of capabilities for every analytics workload. From data processing and SQL analytics to streaming, search, and business intelligence, AWS delivers unmatched price performance and scalability with governance built in. Choose purpose-built services optimized for specific workloads or streamline and manage your data and AI workflows with Amazon SageMaker. Whether you're starting your data journey or seeking an integrated experience, AWS gives you the right analytics capabilities to help you reinvent your business with data.
Drive tangible business outcomes with analytics on AWS
Search foundation for agentic AI
Accelerate data, analytics, and AI with an integrated experience
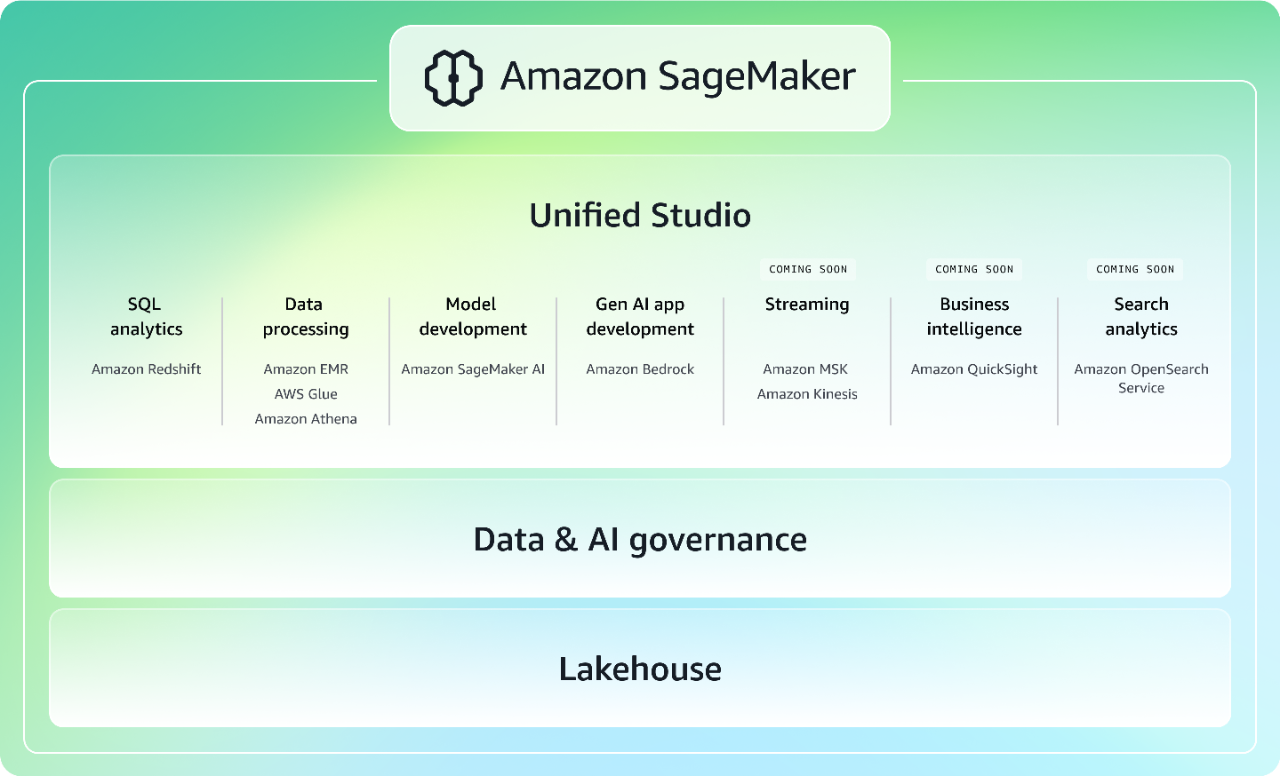
Bringing together widely adopted AWS machine learning (ML) and analytics capabilities, the next generation of Amazon SageMaker delivers an integrated experience for analytics and AI with unified access to all your data. Collaborate and build faster from a unified studio using familiar AWS tools for model development, generative AI application development, data processing, and SQL analytics, accelerated by Amazon Q Developer, the most capable generative AI assistant for software development. Access all your data, whether it's stored in data lakes, data warehouses, or third-party or federated data sources, with governance built into address enterprise security needs. Learn more about SageMaker.
Enabling multicloud strategies with AWS
AWS offers a comprehensive collection of powerful analytics services that enable seamless data access and processing across multicloud and hybrid environments. You can achieve this flexibility through federated querying, data integration, secure data movement, and compatibility with open standards- allowing you to gain insights from all of your data regardless of where it resides.
Amazon Athena allows you to query and gain insights from data stored in a variety of external data sources, including Azure Data Lake Storage, Google Cloud Storage, Microsoft SQL Server, and many others - without the need to copy or transform the data.
AWS Glue simplifies the discovery, preparation, and integration of all your data at any scale, with connectors for over 100 different data sources spanning cloud storage, databases, and analytics services. Glue's zero-ETL integrations make it easy to ingest and replicate data from third-party applications like Salesforce, SAP, Facebook Ads, and Instagram Ads directly into your AWS lakehouses, data lakes, and data warehouses. AWS Glue also offers data interoperability through support for open standards like Apache Hive, Apache Parquet, and Apache Iceberg.
The next generation of Amazon SageMaker is built on an open data lakehouse architecture, providing unified access to data lakes and data warehouses on AWS as well as federated data sources like Google BigQuery and Snowflake. This lakehouse architecture is fully compatible with Apache Iceberg, giving you flexibility to access and query data in-place using any Iceberg-compatible tools and engines.
Harnessing analytics for humans and AI
Power analytics at scale with purpose-built services for storing, querying, streaming, processing, and governing data. From Open Table Formats (OTF) to agentic infrastructure, AWS is evolving analytics engines and applications for the rapidly changing landscape of analytics. In this session see how AWS delivers optimized solutions built for both human users and agentic workflows.

Services
|
Analytics category
|
Description
|
AWS service and capabilities
|
|---|---|---|
|
Streaming
|
Build, scale, and operate real-time data pipelines and applications without the burden of infrastructure management. |
|
|
Data lakehouse, Data warehouse, Data lake
|
Access and analyze all your data in data lakehouses, data warehouses, and data lake. |
|
|
Data processing
|
Analyze, prepare, and integrate data for analytics and AI using open-source frameworks. |
|
|
Business intelligence
|
Build, discover, and share meaningful insights through modern interactive dashboards, pixel-perfect reports, natural language queries, and embedded analytics. |
|
|
Search analytics
|
Securely unlock real-time search, monitoring, and analysis of business and operational data. |
|
|
Data and AI governance
|
Catalog, discover, share, and govern data stored across AWS, on premises, and third-party sources. |
|
|
Data collaboration
|
Analyze and collaborate on collective datasets with your partners—all without sharing or copying one another's underlying data. |
The Total Economic Impact of AWS Modern Data Strategy
Cost savings and business benefits enabled by Amazon Web Services Modern Data Strategy, as reported by Forrester.
Stats
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages