



Was ist Boosting bei Machine Learning?
Boosting ist ein Vorgang, der beim Machine Learning verwendet wird, um Fehler bei der prädiktiven Datenanalyse zu reduzieren. Datenwissenschaftler trainieren Software für Machine Learning, so genannte Machine-Learning-Modelle, auf markierten Daten, um Rückschlüsse auf unmarkierte Daten zu ziehen. Ein einzelnes Machine-Learning-Modell kann je nach Genauigkeit des Training-Datensatzes Fehler in der Vorhersage machen. Wenn zum Beispiel ein Modell zur Katzenerkennung nur auf Bildern von weißen Katzen trainiert wurde, kann es gelegentlich Probleme bei der Erkennung einer schwarze Katze haben. Mit Boosting wird versucht, dieses Problem zu lösen, indem mehrere Modelle nacheinander trainiert werden, um die Genauigkeit des Gesamtsystems zu verbessern.
Warum ist Boosting wichtig?
Das Boosting verbessert die Vorhersagegenauigkeit und die Leistung von Machine-Learning-Modellen, indem es mehrere schwache Lerner in ein einziges starkes Lernmodell umwandelt. Machine-Learning-Modelle können schwache oder starke Lerner sein:
Schwache Lerner
Schwache Lerner haben eine geringe Vorhersagegenauigkeit, ähnlich wie beim zufälligen Raten. Sie neigen zur Überanpassung, d. h. sie können keine Daten klassifizieren, die zu sehr von ihrem ursprünglichen Datensatz abweichen. Wenn Sie das Modell zum Beispiel darauf trainieren, Katzen als Tiere mit spitzen Ohren zu erkennen, kann es sein, dass es eine Katze mit gekrümmten Ohren nicht erkennt.
Starke Lerner
Starke Lerner haben eine höhere Vorhersagegenauigkeit. Durch das Boosting wird ein System schwacher Lerner in ein einziges starkes Lernsystem umgewandelt. Um beispielsweise das Bild einer Katze zu identifizieren, werden ein schwacher Lerner, der spitze Ohren erkennt, und ein weiterer Lerner, der katzenförmige Augen erkennt, kombiniert. Nachdem das Bild des Tieres auf spitze Ohren untersucht wurde, analysiert das System es noch einmal auf katzenförmige Augen. Dadurch wird die insgesamte Genauigkeit des Systems verbessert.
Wie funktioniert das Boosting?
Um zu verstehen, wie das Boosting funktioniert, müssen zuerst erklären, wie Machine-Learning-Modelle Entscheidungen treffen. Obwohl es viele Variationen in der Implementierung gibt, benutzen Datenwissenschaftler häufig Boosting mit Entscheidungsbaum-Algorithmen:
Entscheidungsbäume
Entscheidungsbäume sind Datenstrukturen im Machine Learning, bei denen der Datensatz auf der Grundlage seiner Funktionen in immer kleinere Untergruppen aufgeteilt wird. Das Ziel dabei ist, dass Entscheidungsbäume die Daten wiederholt aufteilen, bis nur noch eine Art übrig ist. Der Baum kann zum Beispiel eine Reihe von Ja- oder Nein-Fragen enthalten und die Daten bei jedem Schritt in verschiedene Kategorien unterteilen.
Boosting-Ensemble-Methode
Beim Boosting wird ein Ensemble-Modell erstellt, indem mehrere schwache Entscheidungsbäume aneinander angereiht werden. Es ordnet der Ausgabe der einzelnen Bäume verschiedene Gewichtungen zu. Dann werden falsche Klassifizierungen aus dem ersten Entscheidungsbaum höher gewichtet und in den nächsten Baum eingegeben. Nach zahlreichen Zyklen kombiniert die Boosting-Methode diese schwachen Regeln zu einer einzigen leistungsfähigen Vorhersageregel.
Boosting im Vergleich zum Bagging
Das Boosting und das Bagging sind die beiden gebräuchlichen Ensemble-Methoden, mit denen die Vorhersagegenauigkeit verbessert werden kann. Der Hauptunterschied zwischen diesen Lernmethoden ist die Trainingsart. Beim Bagging verbessern Datenwissenschaftler die Genauigkeit von schwachen Lernern, indem sie mehrere davon gleichzeitig auf mehreren Datensätzen trainieren. Im Gegensatz dazu werden beim Boosting schwache Lerner nacheinander trainiert.
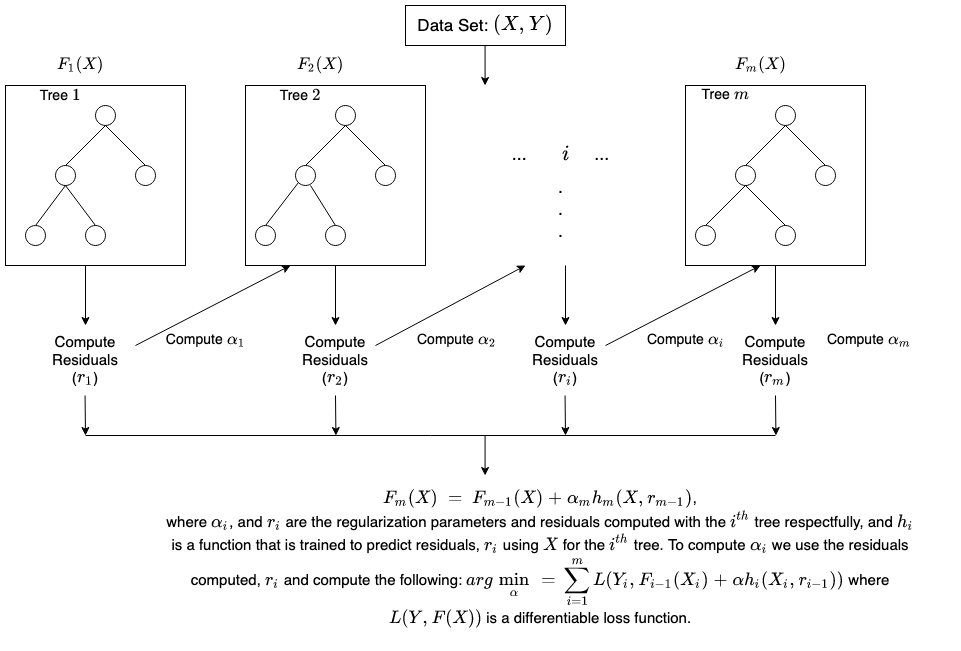
Wie wird das Training beim Boosting durchgeführt?
Die Trainingsart variiert je nach Art des Boosting-Vorgangs, der als Boosting-Algorithmus bezeichnet wird. Ein Algorithmus führt jedoch immer die folgenden allgemeinen Schritte durch, um das Boosting-Modell zu trainieren:
Schritt 1
Beim Boosting-Algorithmus wird jeder Datenprobe die selbe Gewichtung zugewiesen. Er speist die Daten in das erste Maschinenmodell, den so genannten Basisalgorithmus, ein. Der Basisalgorithmus macht Vorhersagen für jede Datenprobe.
Schritt 2
Der Boosting-Algorithmus bewertet die Modellvorhersagen und erhöht die Gewichtung der Stichproben mit einem größeren Fehler. Außerdem wird eine Gewichtung je nach Modellleistung zugewiesen. Ein Modell, das hervorragende Vorhersagen liefert, wird einen großen Einfluss auf die endgültige Entscheidung haben.
Schritt 3
Der Algorithmus leitet die gewichteten Daten an den nächsten Entscheidungsbaum weiter.
Schritt 4
Der Algorithmus wiederholt die Schritte 2 und 3, bis die Instances der Trainingsfehler unter einem bestimmten Schwellenwert liegen.
Welche Arten von Boosting gibt es?
Im Folgenden werden die drei Hauptarten des Boostings beschrieben:
Adaptives Boosting
Das Adaptive Boosting (AdaBoost) war eines der ersten Boosting-Modelle, die entwickelt wurden. Es passt sich an und versucht, sich in jeder Iteration des Boosting-Vorgangs selbst zu korrigieren.
AdaBoost teilt jedem Datensatz zunächst die selbe Gewichtung zu. Anschließend passt es die Gewichtung der Datenpunkte nach jedem Entscheidungsbaum automatisch an. Falsch eingestufte Elemente werden stärker gewichtet, um sie in der nächsten Runde zu korrigieren. Der Vorgang wird so lange wiederholt, bis der Restfehler, d. h. die Differenz zwischen den tatsächlichen und den vorhergesagten Werten, unter einen akzeptablen Schwellenwert fällt.
AdaBoost kann mit vielen Prädiktoren verwendet werden und ist in der Regel nicht so empfindlich wie andere Boosting-Algorithmen. Dieser Ansatz funktioniert nicht gut, wenn es eine Korrelation zwischen Funktionen oder eine große Datendimensionalität gibt. Zusammenfassend lässt sich sagen, dass AdaBoost ein geeigneter Boosting-Typ für Klassifikationsprobleme ist.
Gradient Boosting
Gradient Boosting (GB) ähnelt AdaBoost insofern, als es sich ebenfalls um ein sequentielles Training handelt. Der Unterschied zwischen AdaBoost und GB besteht darin, dass bei GB falsch klassifizierte Elemente nicht stärker gewichtet werden. Stattdessen optimiert die GB-Software die Verlustfunktion, indem sie nacheinander Basis-Lerner erzeugt, so dass der aktuelle Basis-Lerner immer effektiver ist als der vorherige. Bei dieser Methode wird versucht, von Anfang an genaue Ergebnisse zu erzielen, anstatt wie bei AdaBoost Fehler während des gesamten Vorgangs zu korrigieren. Aus diesem Grund kann die GB-Software zu genaueren Ergebnissen führen. Gradient Boosting kann sowohl bei Klassifizierungs- als auch bei Regressionsproblemen helfen.
Extremes Gradient Boosting
Das Extreme Gradient Boosting (XGBoost) verbessert das Gradient Boosting im Hinblick auf Computing-Geschwindigkeit und Skalierung auf mehrere Art und Weisen. XGBoost benutzt mehrere Cores auf der CPU, so dass das Lernen während des Trainings erfolgen kann. Es handelt sich um einen Boosting-Algorithmus, der umfangreiche Datensätze verarbeiten kann, was ihn für Big-Data-Anwendungen attraktiv macht. Die wichtigsten Funktionen von XGBoost sind die Parallelisierung, das verteilte Computing, die Cache-Optimierung und die Out-of-Core-Verarbeitung.
Welche Vorteile bietet das Boosting?
Boosting bietet die folgenden großen Vorteile:
Leichte Umsetzung
Boosting hat leicht verständliche und einfach zu interpretierende Algorithmen, die aus ihren Fehlern lernen. Diese Algorithmen erfordern keine Vorverarbeitung der Daten und verfügen über integrierte Routinen zur Behandlung fehlender Daten. Darüber hinaus verfügen die meisten Sprachen über integrierte Bibliotheken zur Implementierung von Boosting-Algorithmen mit vielen Parametern zur Leistungsoptimierung.
Bias-Verringerung
Unter Bias versteht man das Vorhandensein von Unsicherheit oder Ungenauigkeit in den Ergebnissen des Machine Learning. Boosting-Algorithmen kombinieren mehrere schwache Lerner in einem sequenziellen Verfahren, das die Beobachtungen iterativ verbessert. Dieser Ansatz trägt dazu bei, den hohen Biasgrad, der bei Machine-Learning-Modellen häufig auftritt, zu reduzieren.
Computing-Effizienz
Boosting-Algorithmen priorisieren Funktionen, die die Vorhersagegenauigkeit beim Training erhöhen. Sie können dazu beitragen, Datenattribute zu reduzieren und große Datensätze effizient zu verarbeiten.
Was sind die Herausforderungen beim Boosting?
Nachfolgend sind die üblichen Einschränkungen der Boosting-Modi aufgeführt:
Anfälligkeit für Ausreißerdaten
Boosting-Modelle sind anfällig für Ausreißer oder Datenwerte, die sich vom Rest des Datensatzes unterscheiden. Da jedes Modell versucht, die Fehler des Vorgängermodells zu korrigieren, können Ausreißer die Ergebnisse erheblich verfälschen.
Umsetzung in Echtzeit
Sie könnten es auch als schwierig empfinden, Boosting für die Echtzeit-Implementierung zu verwenden, da der Algorithmus komplexer ist als andere Vorgänge. Boosting-Methoden sind sehr anpassungsfähig – man kann daher eine Vielzahl von Modellparametern verwenden, die sich unmittelbar auf die Leistung des Modells auswirken.
Wie kann AWS Ihnen beim Boosting helfen?
Die Netzwerk-Services von AWS bieten Unternehmen Folgendes:
Amazon Sagemaker
Amazon SageMaker vereint eine breite Palette von Funktionen, die speziell für Machine Learning entwickelt wurden. Sie können es verwenden, um qualitativ hochwertige Machine-Learning-Modelle schnell vorzubereiten, zu entwickeln, zu trainieren und bereitzustellen.
Amazon SageMaker Autopilot
Amazon SageMaker Autopilot nimmt Ihnen die mühsame Arbeit ab, Machine-Learning-Modelle zu entwickeln, und hilft Ihnen, Modelle auf der Grundlage Ihrer Daten automatisch zu entwickeln und zu trainieren. Mit SageMaker Autopilot stellen Sie einen tabellarischen Datensatz zur Verfügung und wählen die Zielspalte für die Vorhersage aus (dabei kann es sich um eine Zahl oder eine Kategorie handeln). SageMaker Autopilot prüft automatisch verschiedene Lösungen, um das beste Ergebnis zu finden. Anschließend können Sie das Modell mit nur einem Klick direkt für die Produktion bereitstellen oder die empfohlenen Lösungen mit Amazon SageMaker Studio iterieren, um die Modellqualität weiter zu verbessern.
Amazon SageMaker Debugger
Amazon SageMaker Debugger erleichtert die Optimierung von Machine-Learning-Modellen, indem er Trainingsmetriken in Echtzeit erfasst und Warnungen sendet, wenn er Fehler entdeckt. Auf diese Weise können Sie ungenaue Modellvorhersagen, wie z. B. eine falsche Identifizierung eines Bildes, sofort korrigieren.
Amazon SageMaker bietet schnelle und einfache Methoden für das Training großer Deep-Learning-Modelle und -Datensätze. Die verteilten Trainingsbibliotheken von SageMaker trainieren große Datensätze schneller.
Beginnen Sie heute noch mit den ersten Schritten mit Amazon SageMaker, indem Sie ein AWS-Konto erstellen.