Amazon Redshift
Meilleur rapport qualité-prix pour l'entreposage de données dans le cloudPourquoi Amazon Redshift ?
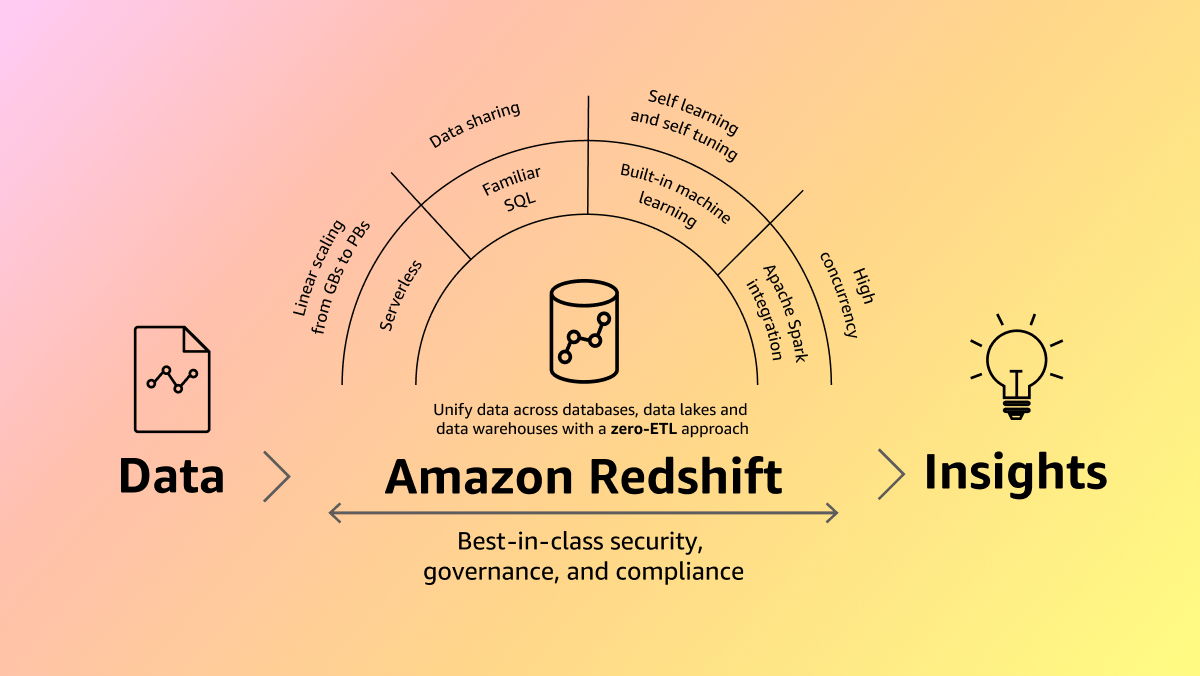
Des dizaines de milliers de clients utilisent Amazon Redshift chaque jour pour moderniser leurs charges de travail d'analytique des données et fournir des informations utiles à leurs activités. Grâce à une architecture de traitement massivement parallèle (MPP) entièrement gérée, à technologie d'IA, Amazon Redshift facilite la prise de décisions commerciales rapidement et à moindre coût. L'approche zéro ETL d'AWS unifie toutes vos données pour des analytiques puissantes, des cas d'utilisation en temps quasi réel et des applications d'IA/ML. Partagez des données et collaborez facilement et en toute sécurité au sein des organisations, entre les régions AWS et même avec des fournisseurs de données tiers, grâce à des fonctionnalités de sécurité de pointe et à une gouvernance précise.
Avantages
Fonctionnement
Cas d'utilisation
Amazon Redshift sans serveur
Exécutez et mettez à l'échelle facilement l'analytique en quelques secondes sans approvisionnement ni gestion d'un entrepôt des données.