AWS Partner Network (APN) Blog
Gain 3x Higher Oracle RAC Database Performance on Amazon EC2 with R5b Instances and gp3 Storage
By Art Danielov, CEO and CTO – FlashGrid
 |
Oracle Database is at the heart of many mission-critical enterprise applications. Moving such applications to Amazon Web Services (AWS) offers multiple benefits, including agility, elasticity, and reliability.
Teams responsible for moving Oracle Databases often have a legitimate concern, however—will they be able to achieve the same level of database performance they’re getting in their current on-premises environments?
A poorly performing backend database makes the applications slow, no matter how much power or horizontal scaling the servers provide. Also, given the central role backed databases play, they often run on the fastest (and most expensive) hardware available: large servers, all-flash storage arrays, Oracle Exadata engineered systems, or even mainframes.
Can AWS match performance of those on-premises systems? The short answer is yes, in most cases. Amazon Elastic Compute Cloud (Amazon EC2) provides a multitude of high-performance server, network, and storage options that can match or exceed performance of the majority of existing on-premises systems.
Of course, the most demanding cases require more elaborate assessment and may require more sophisticated configurations. With new Amazon Elastic Block Store (EBS) and EC2 capabilities, even the simplest configurations can achieve higher performance levels.
At FlashGrid, when helping Oracle Database customers move to AWS, we see the most success come from simple and inexpensive solutions. In this post, I will explore how the new Amazon EBS gp3 general purpose volumes and Amazon EC2 R5b instances enable high-performance Oracle Databases.
FlashGrid is an AWS ISV Partner that enables running clustered Oracle RAC databases on AWS. This includes multi-Availability Zone (AZ) capability, retaining full control of the database software, infrastructure as code (IaC) deployment model, and 24/7 support.
Why Storage Performance Matters
It’s important to keep in mind the primary function of a database system is writing and retrieving data. The amount of computation can be significant and, of course, data retrieval doesn’t always require access to the persistent storage. In many cases, though, fast access to storage is critical for fast database performance.
How do we characterize storage performance? The following metrics provide sufficient information in majority of practical scenarios:
- Read IOPS: Small block (e.g. 8KB) read i/o operations per second.
- Write IOPS: Small block (e.g. 8KB) write i/o operations per second.
- Read MBPS: Amount of data read per second in large blocks (e.g. 1MB).
- Write MBPS: Amount of data written per second in large blocks (e.g. 1MB).
- Read Latency: How long it takes to read a small block (e.g. 8KB) of data.
- Write Latency: How long it takes to write a small block (e.g. 8KB) of data.
The majority of database administrators and system engineers are familiar with these metrics. But which ones should we pay more attention to when moving Oracle databases to AWS?
In FlashGrid’s four years of experience moving Oracle databases to AWS, we see a clear pattern of where the bottlenecks usually are and where they are not. Often, the actual bottlenecks are different from what our customers are initially concerned about.
Write IOPS and Write Latency in most cases are not a problem, even for a write-heavy OLTP workload, and even in a multi-AZ cluster. Write MBPS can be important for loading or restoring large databases, but are typically not a problem if Read MBPS are sufficient.
Read Latency is critical, meanwhile, but with SSD-based EBS volumes it’s never a problem if IOPS and MBPS are not saturated. This brings us to the most usual storage-related suspects in a poorly performing database: Read IOPS and Read MBPS.
If your Oracle AWR report shows User I/O at the top of the Wait Classes by Total Wait Time list, then it’s likely that insufficient Read IOPS and/or Read MBPS are creating the bottleneck. Note that you should expect some slowdown even if you are utilizing 50% of the available throughput.
Also, if Avg Wait for “db file sequential read” / “db file scattered read” / ”direct path read” events substantially exceed 1ms, this is an indicator that Read IOPS and/or Read MBPS are close to saturation. If your workload is bursty, this can happen at even lower average throughput utilization.
In short, undersize your Read IOPS or Read MBPS and your database will not perform. However, on AWS we don’t size Read and Write throughput separately. In practical terms, we just need to pay attention to the total amount of IOPS and MBPS available in your data disk groups.
How the New R5b Instance Type Helps
Let’s start with our observation that R5 has been the most popular Amazon EC2 instance family for running Oracle databases. The reason is an optimal (for most cases) ratio of memory-to-CPU size.
Now, the new R5b family offers the same sizing as R5, except that its storage throughput is more than 3x higher.
| R5 | R5b | |
| Storage Read/Write IOPS (max) | 80,000 IOPS | 260,000 IOPS |
| Storage Read/Write MBPS (max) | 2,375 MB/s | 7,500 MB/s |
The conclusion is simple: if your database performance has been limited by storage throughput, you can improve the performance with R5b instances. Or, if you had to use a more complex configuration to achieve the required throughput, you may be able to achieve it in a simpler configuration using EBS, for example, instead of local SSDs, or instead of multiple storage nodes.
How the New gp3 EBS Volume Type Helps
Now, let’s consider how we should configure our Amazon EBS volumes to reach the 260,000 IOPS and 7,500 MBPS that the largest R5b instances provide.
The first choice we need to make is whether to use General Purpose SSD or Provisioned IOPS SSD volumes. The Provisioned IOPS SSD volumes offer higher IOPS per volume. However, Oracle ASM allows us to easily combine multiple volumes per disk group and leverage their total throughput.
Each gp3 volume can be configured with up to 16,000 IOPS and up to 1,000 MBPS each. Thus, 17 gp3 volumes let us reach the 260,000 IOPS cap for the largest R5b instances.
We only need eight gp3 volumes to reach the 7,500 MBPS instance maximum. With gp2, we would have to use 4x more volumes to reach the same MBPS because gp2 has only up to 250 MBPS per volume.
It’s also important that gp3 volumes, unlike gp2, allow us to configure the IOPS and MBPS independent of the volume capacity. While gp2 has the same maximum of IOPS per volume, the IOPS to capacity ratio is fixed at three IOPS/GB. With gp2, we may have to overprovision capacity (and pay for it) if we needed higher IOPS. No need for this with gp3.
You may ask, “Why not use io2 volumes that also allow configuring IOPS independent of the capacity?” Let’s look at how much it would cost with each volume type.
Here is our calculation of costs in US East (N. Virginia) for three different capacity/performance configurations.
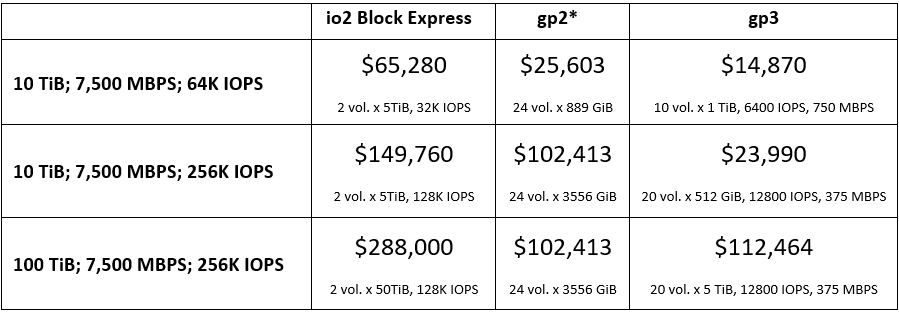
* All gp2 configurations have a practical limit of 6,000 MBPS because of 250 MBPS max per volume and limits on the number of volumes per EC2 instance.
We have included io2 Block Express because of better performance and better pricing compared to io2. Comparing gp3 against io2 Block Express, gp3 is a clear winner on the pricing front while providing the same total MBPS and IOPS.
Comparing gp3 against gp2, gp3 is a clear winner in configurations with smaller capacities because, with gp2, we have to provision excessive amount of unused capacity. With larger capacities, gp2 may seem to have some advantage, but even pushing the number of volumes per instance to the maximum allowed limit, we still can’t reach the 7,500 MBPS with gp2 because MBPS per volume are 4x lower.
Let’s also clarify regarding the durability of the EBS volumes. The io2 volumes provide higher 99.999% durability compared to the 99.98-99.99% durability of the gp3 volumes. However, in FlashGrid clusters we use two- or three-way data mirroring at the ASM disk group level.
Mirroring compensates for the lower durability of the gp3 volumes compared to io2, and in the case of multi-AZ deployment it also provides additional protection against a local disaster affecting one Availability Zone. This makes mirrored gp3 volumes perfectly suitable for mission-critical Oracle databases.
Multiplying Storage Throughput with Multiple Nodes
The per instance IOPS and MBPS are further multiplied by combining several nodes in a cluster. The most popular FlashGrid cluster configurations have two and three database nodes with EBS volumes directly attached to them.
FlashGrid Read-Local technology allows leveraging the total read IOPS and read MBPS aggregated over the two or three nodes.
Maximum theoretical EBS read throughput in a FlashGrid cluster:
- Two RAC nodes: 520K IOPS and 15,000 MBPS
- Three RAC nodes: 780K IOPS and 22,500 MBPS
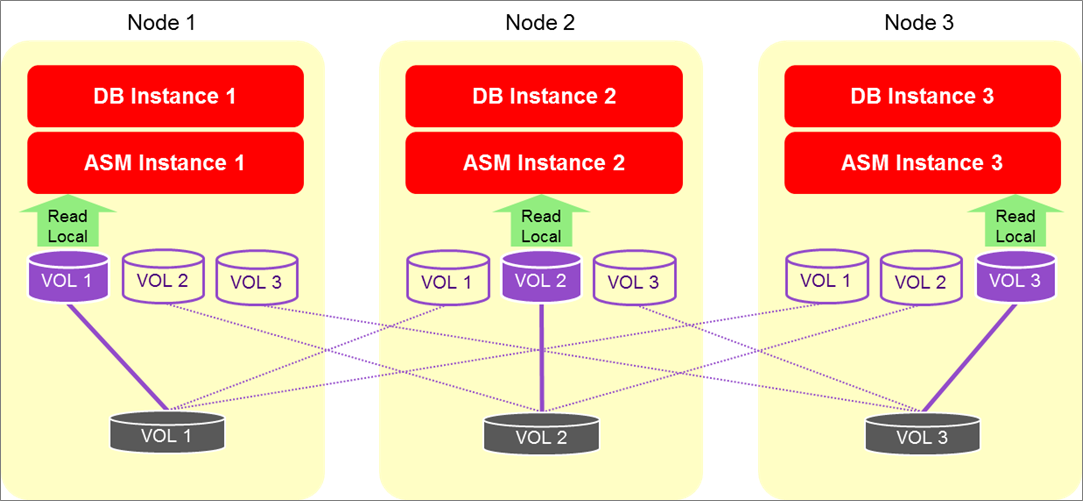
Figure 1 – Concurrent reads on multiple nodes.
Measuring Storage Throughput
Let’s measure the actual storage throughput we are getting through the database stack. The easiest way to do this is by calling the DBMS_RESOURCE_MANAGER.CALIBRATE_IO procedure that’s built into Oracle database using the following SQL code:
The following parameters are used in the SQL code:
<number of disks> – the total number of disks in the disk group used for the database files.
<max latency> – the maximum allowed latency in milliseconds, for example, 10.
At FlashGrid, we have measured the following results with r5b.24xlarge database nodes and with (20) gp3 volumes per database node configured with 16,000 IOPS and 1000 MBPS each:
| Cluster configuration | Max IOPS | Latency (ms) | Max MBPS |
| 2 RAC database nodes | 456,886 | 0.424 | 14,631 |
| 3 RAC database nodes | 672,931 | 0.424 | 21,934 |
The measured Max IOPS are at 87% of the theoretical maximum, while Max MBPS are at >97%. These results show the storage performs as advertised and also the software stack can actually utilize the available storage performance.
Deploy a Cluster to See it Working
You can easily deploy a FlashGrid cluster with Oracle RAC in less than two hours. The deployment is done using an AWS CloudFormation template and includes installation of Oracle software.
Follow instructions in the deployment guide and make the following selections:
- On the Nodes tab in FlashGrid Launcher, select one of the R5b instance sizes for database nodes.
- On the Storage tab in FlashGrid Launcher, make sure to configure the DATA disk group with the number of disks and IOPS and MBPS for each disk such that their total throughput matches the throughput of the selected instance size.
After deploying a cluster, you can create a database or restore an existing database from backup following standard Oracle procedures.
Real-World Use Case
One of FlashGrid’s customers is a sportswear vendor whose Oracle ecommerce system runs on a three-node RAC cluster on AWS. During the 2020 holiday season, the vendor had a record number of purchases from their online store. As a result, the peak storage throughput utilization started exceeding 50% of what their r5.12xlarge instances and gp2 volumes were able to provide.
This became an obvious challenge for the 2021 holiday season that is expected to produce even higher load.
Simply doubling the amount of gp2 storage and doubling the instance sizes to r5.24xlarge would provide sufficient storage throughput, but it would also double the Amazon EC2 and EBS costs and leave the extra CPU and memory resources underutilized.
The new r5b instance type arrived just in time. Switching from r5.12xlarge to r5b.12xlarge and from gp2 to gp3 volumes allowed the customer to triple storage throughput while keeping the total cost at roughly the same level.
Summary
Performance of Oracle databases in many cases critically depends on performance of the underlying storage.
The new Amazon EC2 R5b instance type allows you to achieve 3x times higher storage throughput without adding any extra complexity. The new Amazon EBS gp3 volume type, meanwhile, allows achieving those maximum throughput levels at a very reasonable cost.
Combining clustered R5b instances and multiple gp3 volumes per instance in a FlashGrid-engineered cloud system vastly expands the possibilities for implementing high performance databases on AWS, and for migrating from existing high-end on-premises systems.
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
.

.
FlashGrid – AWS Partner Spotlight
FlashGrid is an AWS ISV Partner that enables running clustered Oracle RAC databases on AWS.
Contact FlashGrid | Partner Overview | AWS Marketplace
*Already worked with FlashGrid? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.