AWS Partner Network (APN) Blog
Reinventing Relational Data Management Using AWS Big Data Services
 |
 |
By Arun Kannan, Solutions Architect at AWS
By Shankar Rajendran, Principal Architect at Cognizant
Today’s businesses deal with varieties of data, including structured datasets stored in various repositories like a relational databse management system (RDBMS) or enterprise resource planning (ERP); semi-structured datasets like web logs and click-stream datasets; and unstructured datasets like images and videos.
This variance necessitates that large organizations build a data lake, which are an architectural approach to storing different formats of data in a centralized repository. This can help you run different types of analytics, big data processing, real-time analytics, and machine learning to gain better insights from you data.
Amazon Web Services (AWS) provides a secure, scalable, comprehensive, and cost-effective portfolio of services that enable customers to build their data lake in the cloud and to analyze all of their data, including data from Internet of Things (IoT) devices with a variety of analytical approaches like machine learning.
Many organizations, however, continue to store critical but infrequently accessed data in commercial database engines like Oracle and Microsoft SQL Server. A good example is an audit management system where the audit data is stored either as Blob or CLOB in RDBMS.
This is a potential opportunity for organizations to securely migrate data to AWS, where the data is made available on Amazon Simple Storage Service (Amazon S3) using AWS Database Migration Service (DMS). AWS Big Data Services are leveraged to perform data transformation and analytics. The benefits of this approach include reducing operational costs and commercial database license costs.
Customer Success
While working with a large U.S.-based healthcare provider, AWS and Cognizant, an AWS Partner Network (APN) Premier Consulting Partner and Managed Service Provider (MSP), the customer was incurring escalated operational costs in managing their data and looking for solutions to address this.
Together, AWS and Cognizant identified the opportunity to migrate their audit management system, which was infrequently used and running on an on-premises Oracle database engine. A proof of concept (POC) was quickly built to demonstrate the ease of data migration to Amazon S3, the core storage component in an AWS data lake solution, by using AWS Database Migration Services.
The required data transformation was performed using AWS Glue. Reports were generated using their existing business intelligence (BI) tools using Amazon Athena ODBC drivers. The POC was successfully completed and qualified with the customer. Currently, Cognizant is working with them to migrate their audit management system to AWS data lake solution.
In this post, we offer an approach of migrating similar datasets to Amazon S3 using DMS, and using AWS analytics services for performance measurement and reporting. We’ll also discuss the migration using simple process flow and best practices that can be leveraged during the migration.
How We Built a Cost Optimized Solution
An approach that has worked for many companies adopting cloud technologies is to identify the critical but infrequently used datasets and determine the business impact before starting the actual migration process.
Here’s how we built this cost optimized solution for the customer:
Data Migration
The customer’s audit data stored on Oracle database was migrated to Amazon S3 using the Database Migration Service. To expedite this, several DMS tasks were executed for parallel migration of data to Amazon S3.
Data Discovery
AWS Glue simplified the time-consuming tasks of data discovery, which was done by crawling data sources and constructing a data catalog commonly known as AWS Glue Data Catalog. Metadata was stored as tables in the AWS Glue Data Catalog and used for the authoring process of the extract, transform, load (ETL) job.
Extract, Transform, Load (ETL)
AWS Glue was also used to author and schedule two specific jobs for ETL. The first was to encode the CLOB and Multiline data, and the second was to partition and convert the data to Parquet format. These steps improved cost efficiency while continuing to analyze data using various analytics tools.
Analytics
Amazon Athena makes it easy to analyze data in S3 using standard SQL. The data stored in Parquet format significantly reduces the time taken to analyze the data and the cost of querying. IBM Cognos or Business Object can use Athena ODBC drivers to explore and visualize the audit data.
Here’s the architecture for our cost optimized RDMS:
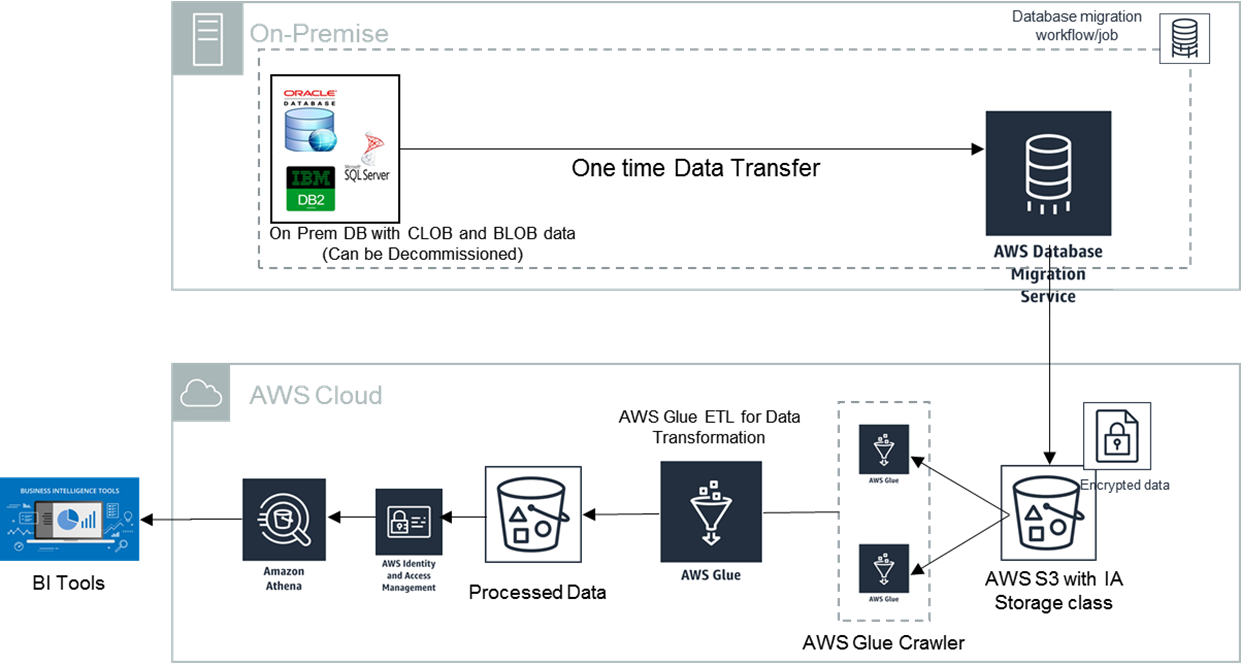
Figure 1 – Architecture for the cost optimized RDMS.
In the above data lake approach, Amazon S3 is the central storage reposistory to store data in any format. The architecture uses DMS to migrate or ingest the dataset from on premises database to S3. The data can be catalogued using AWS Glue crawler and run ETL jobs to cleanse the data by encoding the CLOB data and multiline data.
Another ETL job further cleanses the data by removing any duplicates and dummy records before converting storing the data in Parquet format.
The diagram in Figure 2 illustrates the migration strategy followed during the migration of data.

Figure 2 – Migration strategy followed during the migration of data.
What We Learned From the Migration
Migrating data from relational databases to an Amazon S3 object store involves several meticulous processes to organize the data stored in the target system. Here are some best practices we learned that you can follow for quicker data retrieval in a cost effective way.
Data Migration Strategy
Data migration strategy is a critical step in the migration of data to S3 using DMS. Key aspects in the data migration are:
- Classify the table based on the size of the table.
- Identify columns in the table with multi-line or CLOB columns to apply 64-bit encoding during the ETL process.
- Identify partitioned keys for the target, based on frequently-used queries or on reporting requirements.
- Identify the number of parallelized DMS tasks required to transfer the data.
- Define the validation strategy post migration of data to the target system.
Data Transformation
The data transformation process is necessary to improve the performance of the query. Here are key aspects in data transformation:
- Use AWS Glue to partition the data and store it in S3 in Parquet format.
- Use the ETL process for encoding the multi-line data or CLOB data to query effectively using Amazon Athena. The columns in the table need to be decoded while querying the data with Athena or other SQL tools.
How We Built a Cost Optimized Solution
Using the AWS TCO (Total Cost of Ownership) Calculator, we found the cost for one server with two CPU cores, 32 GB of memory, and one TB is about US $4,800 per month, excluding the database licensing cost and other infrastructure and operational costs. Estimated annual costs for the above scenario, including the infrastructure, software, and operation costs, was $71,000.
After using the solution proposed by Cognizant, the customer’s monthly cost was reduced to a few hundred dollars. This cost is inclusive of running the data lake and analytics using AWS Big Data services like Amazon Athena.
Through this revised approach towards running the audit management system, once the solution is fully implemented, the customer will benefit from an overall reduction in excess of 80 percent in TCO.
Results
As a result of the new data lake solution, post-migration the data is readily available and users can access it using various patterns like executing ad hoc queries using Amazon Athena, or deliver reports using BI tools.
Notably, this solution is highly-scalable to deliver consistent results within agreed time limits even during the peak loads. The solution is cost optimized and eliminates the licenses of commercial database and decommission the on premises.
Finally, the solution requires lower maintenance activities and leads to higher business resilience due to reduced downtime.
Conclusion
In this post, we have discussed the approach of building a data lake solution to migration of critical but infrequently accessed datasets like audit management systems that are typically stored in RDMBS as BLOB or CLOB data.
We also discussed the simple process flow about the actual activities to be carried out during the migration activities. We outlined the strategy, best practices specific to data migration, and transformation activities. The post also outlines key benefits and results achieved by the customer implementing the data lake architecture .
Learn more about how Cognizant is modernizing infrastructure for an always-on business.
.
|
Cognizant – APN Partner Spotlight
Cognizant is an APN Premier Consulting Partner. They transform customers’ business, operating, and technology models for the digital era by helping organizations envision, build, and run more innovative and efficient businesses.
Contact Cognizant | Practice Overview | Customer Success | Buy on Marketplace
*Already worked with Cognizant? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.