AWS Partner Network (APN) Blog
Using Amazon SQS in a Multi-Tenant SaaS Solution
By Raju Patel, Sr. Partner SA, AWS SaaS Factory
 Modern applications often rely on queuing for service integrations, batch processing, or as part of workflow orchestration. Queues are key to adding scale and resiliency to your environment.
Modern applications often rely on queuing for service integrations, batch processing, or as part of workflow orchestration. Queues are key to adding scale and resiliency to your environment.
This is especially true in software-as-a-service (SaaS) environments, where you need to think about how your queuing strategy supports the workloads of a multi-tenant solution. You need to consider data isolation, performance, and operations when designing the queuing model of your SaaS application.
As a Partner Solutions Architect for AWS SaaS Factory, I have worked with many organizations on their journey to build and operate SaaS solutions on Amazon Web Services (AWS). I particularly enjoy helping organizations architect multi-tenant solutions to increase agility while considering tenant isolation and scalability.
In this post, I will explore some of the common scenarios used when building SaaS solutions with Amazon Simple Queue Service (SQS). I’ll show you how data isolation, scalability, and compliance requirements might influence the queuing model you select.
Included in the post is sample code to highlight the use of SQS in a multi-tenant solution.
The SaaS Queuing Challenge
To better understand the role of queues in a SaaS environment, let’s look at a sample use case. The conceptual diagram in Figure 1 is an example of an order management system that uses queues.
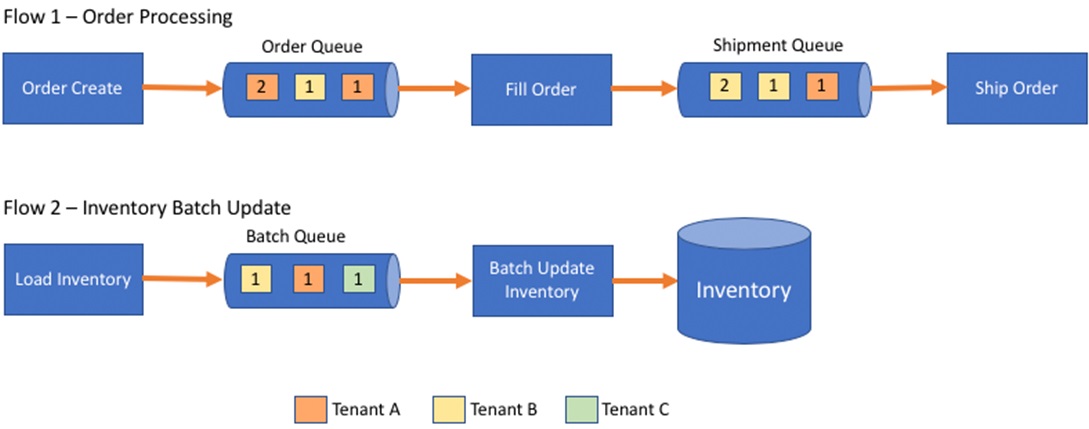
Figure 1 – Order management and inventory update flows using queues.
The first flow depicts the integration of order, create, fill, and ship services. The order and shipment queues receive messages from multiple tenants. The services, such as Fill Order and Ship order, could be running in a container in Amazon Elastic Kubernetes Service (Amazon EKS), or they could be running serverless in AWS Lambda.
The second flow in Figure 1 is for the inventory update, where a file is uploaded by a tenant and a message is placed in the queue to be processed. The Batch Update Inventory process picks up the message and loads the data from the file into the inventory table.
While queues are relatively straightforward, multi-tenancy adds some additional considerations that may shape how you approach your queue design.
For example, you could face issues with message latency if one tenant ends up generating a large volume of orders (relative to other tenants). These messages could cause a backup in the queue for other tenants, thereby degrading the level of service for the other tenants. This scenario, shown in Figure 2, is known as “noisy neighbor.”
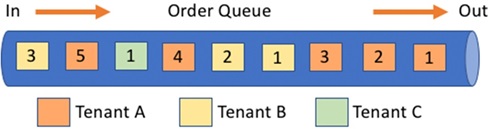
Figure 2 – Tenant A causing noisy neighbor.
Three different colors represent the messages from three SaaS tenants. As you’ll notice, Tenant A has more messages than the other tenants, causing Tenant C to wait for the messages ahead in the queue to be processed. This delay could introduce latency that would impact the experience other tenants are having with the system.
For the inventory update flow, you could face yet another kind of problem. If a file from Tenant B, for instance, has significantly more inventory items to be processed than the files of other tenants do, it could also impact the experience of the other tenants.
The challenge in designing multi-tenant solutions with queues is to find queuing strategies that satisfy multiple goals. You must overcome this noisy neighbor problem while continuing to meet the isolation requirements of tenants whose messages must not be co-mingled with those of other tenants for security and data protection.
At the same time, your approach must allow you to remain agile, simplify operations, and optimize costs.
There is no one-size-fits-all approach to designing the queues in a multi-tenant solution. Cloud-native architectures are often decomposed into various services and architectural components, each of which may play a different role in your system. As a result, the queuing requirements and strategy for each use case and elements of your system could vary.
Besides the variance in architectural components, your tenants may have different usage patterns and data volumes. Not only that, but some SaaS solutions may offer different subscription tiers (for example, Free, Professional, and Enterprise) which could be used to differentiate the experience of users.
You could also use these tiers to define the tolerance for noisy neighbor as part of the service level agreements (SLAs), which would impact the design of your queues. For instance, you could group tenants with similar tolerance requirements into the same queue.
SaaS Partitioning Models
Before we get further into multi-tenant queuing concepts, let’s explore some of the common strategies used to partition resources in SaaS environments. They are known as silo, pool, and bridge.
These core models are foundational to how we think about multi-tenant architecture strategies and, ultimately, represent the range of options you want to consider for your queuing model.
The bridge model is a mix of silo and pool models, in which some queues are shared and other queues are separate by tenant. In practice, due to the different architectural components and varying tenant requirements, most modern SaaS applications use a bridge model.
A more detailed review of these models is covered in the SaaS Storage Strategies whitepaper.
Let’s look at how silo, pool, and bridge queuing models can influence the scalability, data isolation, compliance, and tier functionality of a multi-tenant SaaS solution.
Silo Model
The silo model uses a separate queue for each tenant. This provides the highest level of isolation and data protection, but at higher cost, increased operational complexity, and lower agility.
To fully isolate the flow of messages for tenants, we create a separate SQS queue for each tenant. The separate queues keep any one tenant from creating a bottleneck that can impact other tenants.

Figure 3 – Silo SQS queues for load inventory.
Figure 3 shows a silo model that uses AWS Lambda, Amazon API Gateway, SQS, Amazon Cognito, AWS Key Management Service (AWS KMS), and AWS Identity and Access Management (IAM). These are the basic moving parts of our silo model.
A request comes through Amazon API Gateway and is processed by the load inventory Lambda function. This sends a message to an SQS queue to process downstream. Note that Tenant A and Tenant B each have their own SQS queues to prevent one tenant from impacting the other.
This approach relies on a tenant context that uses a JSON Web Token (JWT) to convey information about a given user and its relationship to a tenant.
If you are considering the silo model, you’ll also need to think about how you will enforce isolation and prevent cross-tenant access to tenant resources. The architecture in Figure 3 introduces some additional constructs that achieve this added layer of isolation.
For instance, when a tenant is onboarded, a role with IAM policies is set up for that tenant. That role limits permissions to the SQS setup to that tenant alone, and is associated with an Amazon Cognito identity pool. Amazon Cognito provides a JWT token with the tenant ID, and the JWT token is passed to the Lambda function, which can assume the role for the tenant and enforce the policies for that role.
The sample code later in this post shows you how to manage tenant context and assume a role using Amazon Cognito, JWTs, and custom claims.
The IAM policy for the role attached to the Amazon Cognito identity pool for Tenant A would look something like this:
“Effect”: “Allow”,
“Principal”: “*”,
“Action”: “sqs:SendMessage”,
“Resource”: “arn:aws:sqs:*:111122223333:TenantA-Inventory”
The disadvantage of a silo model is that it increases operational complexity and reduces agility, especially when the number of tenants or architectural components with queues grows.
With more moving parts, deployment and management gets harder. You wind up setting up the SQS queues for your development, test, and production environments, leaving you with an even larger number of queues to manage.
Having separate queues per tenant also means you need to think about how the consumers will be set up. If your consumers are Lambda functions, you can configure the Lambda function to trigger on events from multiple queues. Lambda functions can scale up to 1,000 concurrent executions based on the reserved concurrency settings and number of messages in the SQS queues.
If you’re using containers, you need to manage configuration information so the container services poll the appropriate SQS queues, and scale based on the number of messages in the queues.
Pool Model
Maximizing efficiency and agility is important for SaaS solutions. You can sometimes do that by sharing resources. Your tenant onboarding gets easier when there are fewer resources to provision for each tenant. You can achieve this by having tenants share SQS queues in a pool model.
The design goal of the pool model is for all tenants to share the queue resources with the assumption that message processing will be able to accommodate the scale and throughput requirements of that SaaS environment.
The challenge with pool, of course, is that any individual tenant can saturate the queue in a noisy neighbor scenario. There are multiple strategies you can use to address this problem.
One approach is to scale your pooled queue consumers based on the depth of messages in the queue. For instance, to scale Amazon Elastic Compute Cloud (Amazon EC2) instances based on SQS queue depth, take a look at scaling based on SQS. If you are using AWS Lambda, you can set provisioned concurrency.
Another approach is to have tenants share a queue based on their tier. The tier could define the allowed message rates, and your application would throttle the requests. This assumes each message has the same processing cost, or that this cost can at least be determined when the message is enqueued (to know find out many throttling units to consume).
Where necessary, there can be several queues for a tier and the tenants could be hashed into a small set of queues with messages going to the queue with the least depth. Take a look at Avoiding Insurmountable Queue Backlogs on the Amazon Builder’s Library for more details on this approach.
The following table is an example of establishing the limits per function based on tier of service.
| Function | Tier | Rate Per Minute |
| Create order | Free | 100 |
| Create order | Professional | 1,000 |
| Create order | Enterprise | 10,000 |
| PO integration | Free | 10 |
| PO integration | Professional | 100 |
| PO integration | Enterprise | 1,000 |
| Ship order | Free | 100 |
| Ship order | Professional | 1,000 |
| Ship order | Enterprise | 10,000 |
To keep the queue backlog from growing too big and prevent messages from causing a backlog to other tenants, you can use throttling in your SaaS application. The throttle limits could be based on the tier of service for the tenant.
Throttling has to be added on the message publisher services in your application. If you use services like Amazon API Gateway, you can set up usage plans to throttle requests. The usage plan can be tied to the tier of service for your tenant. Figure 4 shows a conceptual flow for throttling.
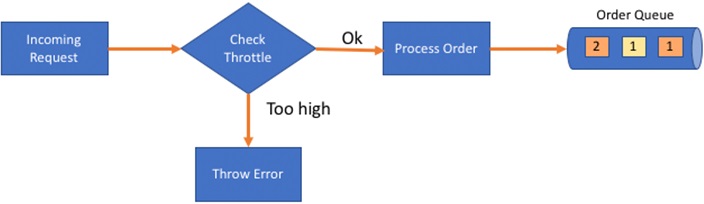
Figure 4 – Throttling requests.
In a pool model, you also need to consider data isolation. With a shared SQS queue, IAM policies don’t help much to scope and control access. This means you have to use an authorization model in your application’s services.
One approach for isolating data in a pool model is to use the Message Attribute in the SQS message and pass the tenant ID. Your service would rely on the JWT token to control injection and processing of tenant messages.
When a user is authenticated, the tenant context is established with the tenant ID and passed in the JWT token. In the service, the tenant_id is read from the claims in the JWT token. This ensures a sender cannot just introduce its own tenant ID. The consumer of the message would use the tenant_id attribute to construct the tenant context.
Besides having to design to prevent noisy neighbor, the downside of a pool model is that if a tenant has compliance or regulatory requirements requiring isolation, no separate queue is available.
Sample Code for Pool Model
Here is some code from the sample queueing application (see link at end of this post) that grabs tenant_id from the claims in the JWT and sets it in the Message Attribute.
Bridge Model
In your SaaS solution, a small subset of tenants may have unique regulatory requirements. Or, some part of the application is better suited for separation by tenant, and it’s necessary to set up a separate SQS queue per tenant (silo).
At the same time, other parts of the application may be better suited for a pool model for more agility and efficiency.
Having a mix of the both the silo and pool model is known as the bridge model.
For instance, let’s say you are integrating to external applications and you want to deliver messages to an SQS queue and allow the tenants to access the messages. In this scenario, a pool model is not feasible because you want to limit access to messages only for that tenant. This could be a scenario where using a silo model for part of the application makes sense.
Figure 5 shows a conceptual diagram of a bridge model that uses a pooled model for queuing of order messages and a silo model for queuing of purchase order messages for tenant integration. In the pool model, there are multiple queues to prevent noisy neighbor situations.
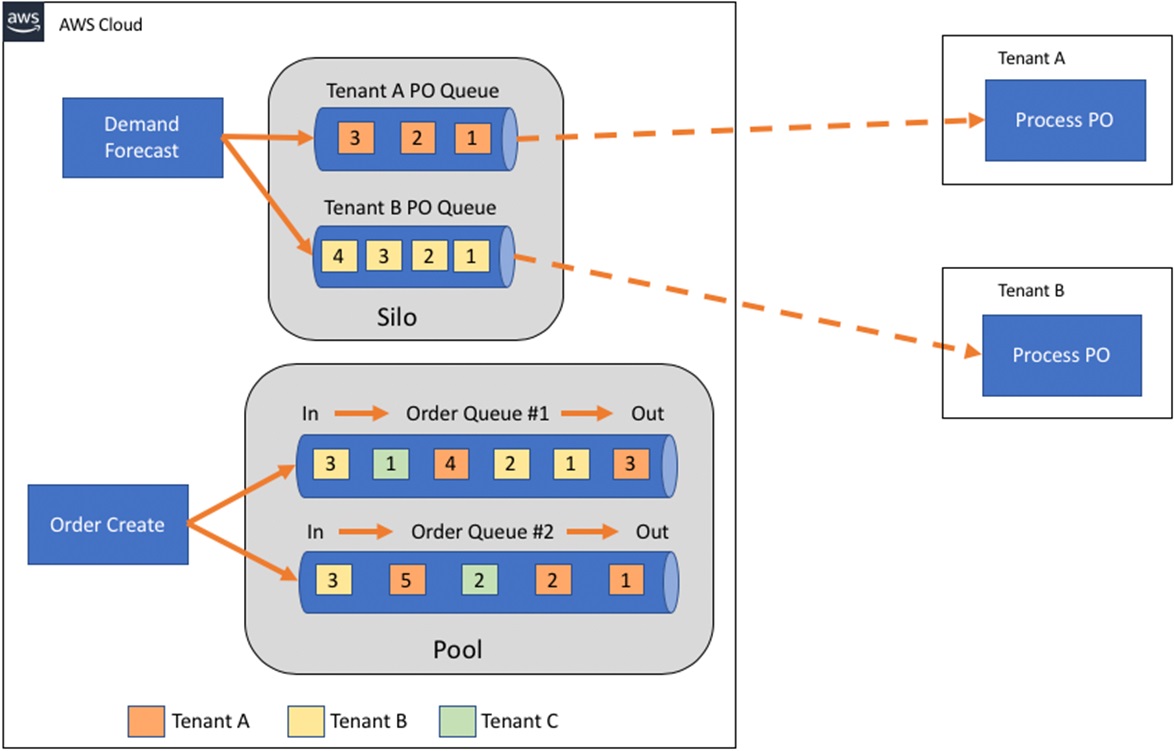
Figure 5 – Conceptual diagram of bridge model.
Monitoring SaaS Queues
Regardless of your model for SQS in the multi-tenant solution, ensuring a consistent tenant experience requires monitoring and metrics. Amazon CloudWatch has SQS metrics to let you monitor queues. This is good for overall queue metrics, but it won’t give you much visibility at a tenant level in a pool where queues are shared.
For a pool model, you have to collect tenant-specific metrics by instrumenting your code to log events and analyze the metrics. SQS provides the timestamp of when each message reaches the queue. With the timestamp information, every time you take a message off the queue, you can log and analyze metrics such as latency.
Metrics such as queue depth, age of the oldest message (for example, to catch edge cases like poison pill), and average time a message is in the queue per tenant, are valuable for visibility to the health of the solution. You can use these metrics to refine your queuing model to deliver consistent experience for all your tenants.
You can also set up custom alarms in CloudWatch to be alerted when one of your tenants may be impacted.
Having metrics on the performance of the queues helps you scale the solution to meet the needs of your tenants. This could mean adding queues or separating a tenant into their own queue.
Encryption
For compliance or regulatory reasons, you may need to encrypt the data flowing through the SQS queue. SQS supports encryption using a key from AWS KMS for the entire queue, which means all the messages in the SQS queue are encrypted using a single encryption key.
In cases where the data has to be encrypted using a tenant managed key, the encryption strategy depends on whether you are using a silo or a pool model. For a silo model, since each tenant already uses a separate SQS queue, using the encryption key from AWS KMS will meet the requirements.
To use a tenant managed key in a pool model, you need client-side encryption. This means the producer and consumer must use client libraries to encrypt and decrypt the messages. While client-side encryption and decryption offer isolation, they add complexity and possible performance overhead to your application. Even with client libraries to encrypt and decrypt messages, you could use AWS KMS to manage the keys.
AWS KMS supports auto-rotation of the keys it manages. Alternatively, the keys can be customer-managed, meaning tenants could manage their own keys. To use a customer-managed key in AWS KMS, your SaaS solution needs to expose functionality for a tenant to manage their own key. This would involve having ability to update a key and to rotate a key.
Cost
As part of your SaaS queuing strategy, you also need to think about how each approach impacts the cost of your solution.
The pricing for SQS is based on API calls, not the number of queues. There is a charge for each API call after the first one million monthly requests. Look for ways to minimize API calls when deciding between silo and pool, and when designing your solution.
In a silo model, you could end up with increased costs from polling many SQS queues, or if the messages are delivered infrequently and the batch size averages less than 10.
The pool model with shared queues should result in fewer number of SQS queues to manage, and optimizes the use of your resources. With fewer SQS queues to poll, it would reduce API calls and CPU cycles compared to the silo model. Batch processing of messages is more likely to pick up multiple messages, which also helps minimize costs.
If you need to charge tenants based on a consumption model, then you must measure consumption of the SQS queues. In a silo model, you achieve this by applying cost allocation tags to each SQS queue, and use the tags to report costs. The tag could be the name of the tenant, and the value would be the tenant ID.
By using cost allocation tags, there’s no need to collect additional metrics and usage when operating with a silo model.
In a pool model, calculating for SQS queues by tenant is more challenging due to the SQS queue being shared. Cost allocation tags don’t help much in a shared queue. Instead, you must capture metrics on calls per tenant. Modify your application to log publish and subscribe events with tenant IDs, and use that data to allocate costs by tenant.
Queuing Sample Code
I have written some sample code in Python to demonstrate the concepts we just discussed. The solution can be deployed using AWS Serverless Application Model (SAM) in your own AWS account. The architecture deployed in the sample is shown here.
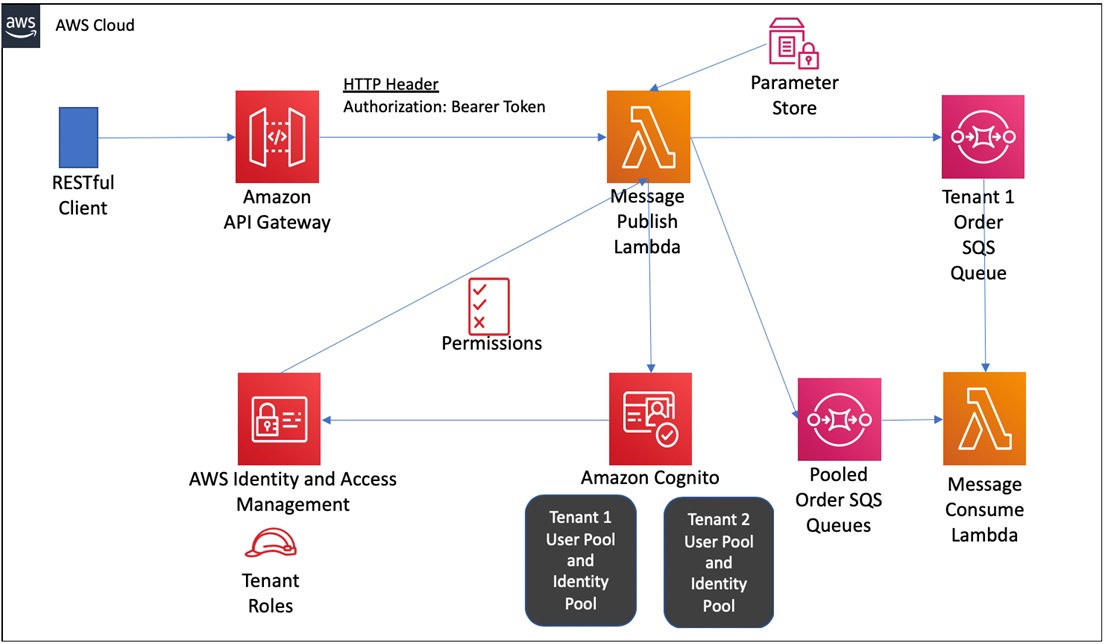
Figure 6 – Sample application architecture.
The sample code is available in the AWS SaaS Factory Github.
Conclusion
A thoughtful queuing strategy is essential for providing scale and resilience to the service integration, batch processing, and workflow orchestration of multi-tenant SaaS applications. Silo, pool, and bridge queuing models each affect the agility, efficiency, and cost of your business differently.
To choose the right queuing model, you must understand the data isolation, scalability, and compliance requirements of your application, and you must consider encryption requirements and cost.
Here are some additional resources to help you get started:
- Modeling SaaS tenant profiles on AWS
- Solving complex ordering challenges with Amazon SQS FIFO queues
- Avoiding insurmountable queue backlogs

About AWS SaaS Factory
AWS SaaS Factory helps organizations at any stage of the SaaS journey. Whether looking to build new products, migrate existing applications, or optimize SaaS solutions on AWS, we can help. Visit the AWS SaaS Factory Insights Hub to discover more technical and business content and best practices.
SaaS builders are encouraged to reach out to their account representative to inquire about engagement models and to work with the AWS SaaS Factory team.
Sign up to stay informed about the latest SaaS on AWS news, resources, and events.