AWS Partner Network (APN) Blog
Using Computer Vision to Enable Digital Building Twins with NavVis and AWS
By David Sauerwein, Sr. Data Scientist – AWS
By Markus Winterholer, Delivery Practice Manager – AWS
By Simon Boehmer, Cloud Application Architect – AWS
By Ignacio Perez Hallerbach, VP Global Head of Partners & Platform – NavVis
 |
| NavVis |
 |
Managing existing brownfield buildings is a challenging task because teams usually lack accurate ground truth data. Object detection algorithms are a key technology to automate and scale the creation of a digital building twin, providing a solution to this challenge.
For detecting objects in indoor environments with machine learning, NavVis and Amazon Web Services (AWS) collaborated to build a digital building twin for a large industry customer.
This post covers the requirements for the customer’s application, as well as the main challenges for training, evaluation, and deploying custom object detection models on Amazon SageMaker. Additionally, it covers the management of multiple models and the integration into an existing digital twin initiative using a full serverless web application.
NavVis is an AWS Partner that supplies fast, reliable spatial data to service providers and enterprises seeking to capture photorealistic digital twins of the built environment. Its digital factory solutions enable greater organizational operability, productivity, agility, and profitability.
Digital Twins
Digital twins have become an inevitable tool for data-driven modeling and process optimization along the entire value chain. AWS has defined a 4-level framework to help customers categorize their digital twin use cases to best understand the data, models, and business processes needed to enable digital twin use cases.
Here, we have built an L2 Informative digital building twin. The web application shown in Figure 1 enables users to see detected points of interest on a floor plan.
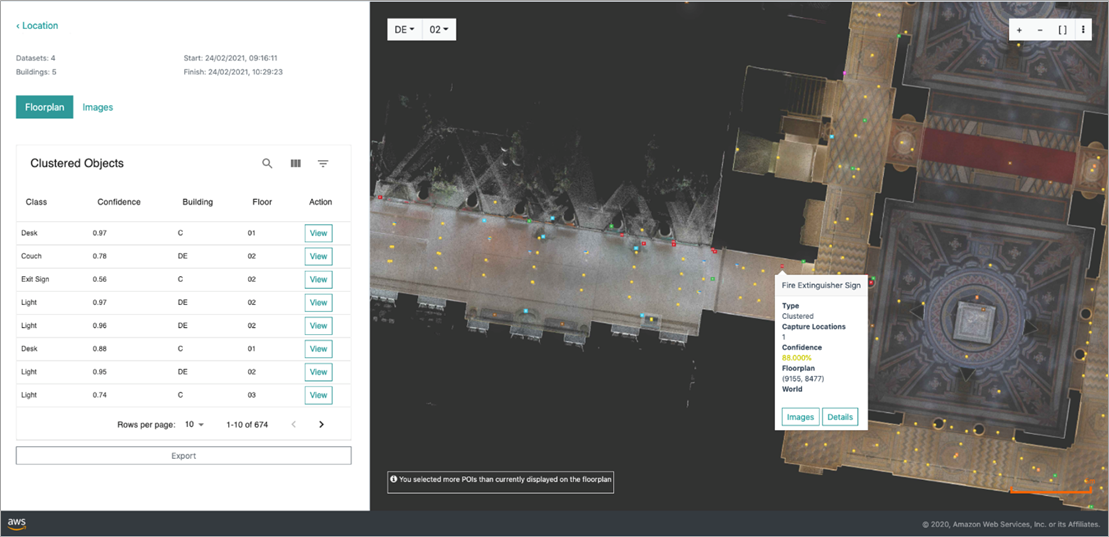
Figure 1 – Object detection web application.
The digital twins presented here use accurate 3D point cloud data and panoramic images provided by the NavVis Reality Capture Solution. To further populate the digital twins with object-level information, AWS Professional Services automated the object detection in the cloud.
A digital replica of a building that serves as a single source of truth for infrastructure data enables a large variety of use cases for modern facility management. Monitoring of infrastructure, building auditing, maintenance, performance and safety improvements, as well as compliance checks, can all be automated and supported with an accurate digital building twin.
Problem and Business Value
For newly-constructed buildings, a range of digital plans and inventory lists are available. Usually, the data is extracted from the construction plans as a planned model.
To validate that the assets are installed in the right place and quantity, a manual assessment is required to create an as-is building model. For existing brownfield buildings, the asset data and accurate plans represent a scarce article. Object-level information in the form of inventory lists is missing or outdated, and often entire plans of the site don’t reflect the latest state of the building.
To fill this data gap, the customer conducted yearly building reviews manually. However, these manual processes are error-prone and produce low-quality data that can only be used for a limited number of use cases and are hard to scale. The new solution creates high-density and high-quality data for a variety of stakeholders in an automated way.
The solution proves these manual building reviews can be substituted by a digital, computer vision-powered process. Automated data collection, inventory generation, and data review build a solid base for rich digital building twins.
This solution generates efficiencies in facility management and enables quick adaptation of buildings to users’ needs. It also enables the evaluation of the data quality of automatically created building inventory lists, and to assess a range of business cases designed around automated building reviews.
Goals and Requirements
A full machine learning (ML) pipeline is required to enable the automated detection of objects. The initial prototype is focused on detecting and reviewing 13 object classes, including smoke detectors, desks, lights, exit signs, and fire extinguishers.
These classes allow for the validation of a range of engrossing business cases, such as:
- Validating if exit signs are pointing to an emergency exit.
- Validating fire extinguishers are present under adequate signage.
- Validating if a smoke detector is in every room.
- Planning maintenance activities, such as counting lights, counting desks for cleaning, or counting plants for watering.
The figure below shows detected objects of interest in a building hallway. Fire extinguishers are detected below the signs, which is compliant with the security requirements.
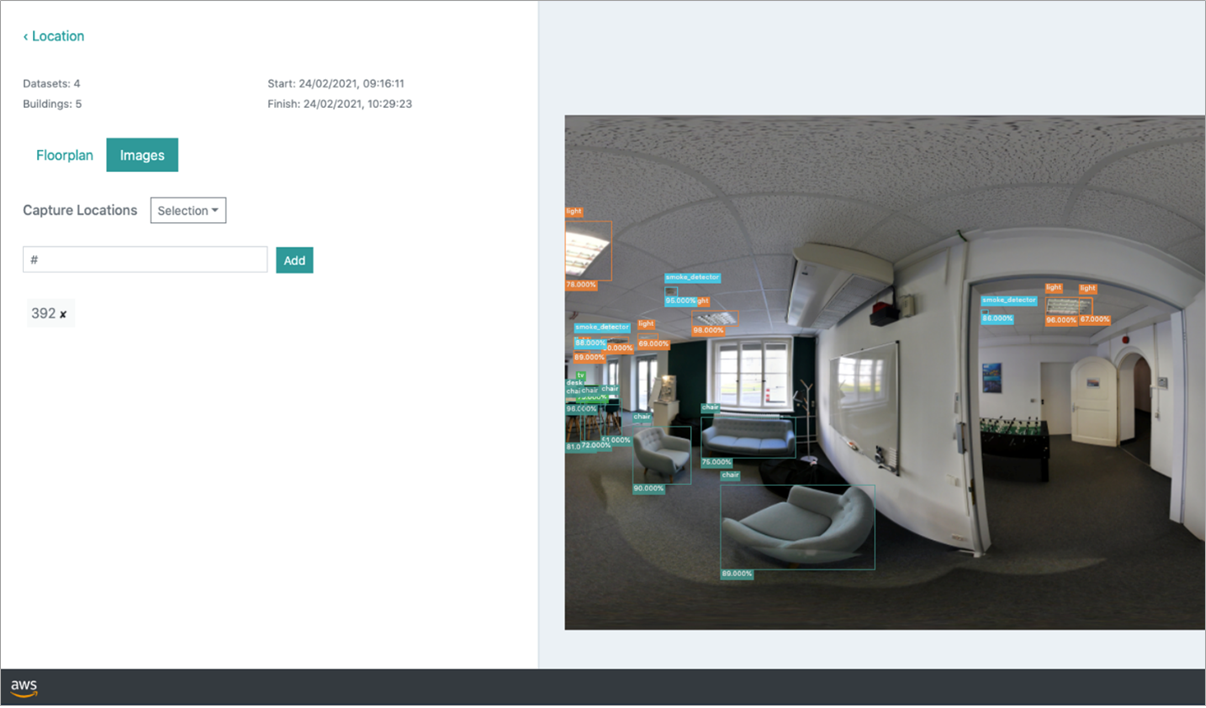
Figure 2 – Web application showing objects detected in a hallway.
In addition to that initial set of object classes, a requirement is the low cost of adding new classes from different locations. The flexibility and scalability of the solution is important because of the high variability of buildings, both in terms of layout and equipment.
A cost-optimized approach to data labeling and model training is emphasized in this solution by incorporating few-shot learning and pre-labeling.
To guarantee a level of modularity, the solution enables users to include multiple models that are specialized in different object types. The user also has to deal with numerous large image datasets; therefore, a streamlined management of new datasets and buildings is also a key requirement.
Eventually, a substantial number of objects from different sources is detected. For usability, the application has to be accessible through a web browser, allow the user to validate the results, integrate with the existing digital twin project, and ideally only incur costs when it’s actually used.
Next, we walk you through the following high-level components of the solution.
Data Acquisition
NavVis’ mobile mapping solutions played a key role when in capturing highly accurate 3D scans of the relevant indoor environments.
The data was captured using the NavVis M6 and NavVis VLX devices while continuously moving through the building. The scanning devices are equipped with a set of high-resolution cameras and LiDAR sensors. A single scan package contains 3D point cloud data, raw camera images, and panoramic images.
For training a 2D object detection model, the panoramic images were selected due to their smaller size, which could lead to less effort during the labeling phase.
The following image shows an example of the scanning process using NavVis VLX.

Figure 3 – Wearable mobile mapping system scanning process using NavVis VLX.
Image Tiling
The panoramic image resolution is 8192×4096 pixels, and size varies from 5-10 MB. Modern object detection frameworks expect smaller images. To address this problem, image tiling is introduced and images are resized to 2048×1024 pixels.
Then, a sliding window sized at 1024×1024 pixels extracts smaller tiles with 50% overlap, resulting in three images with annotations split accordingly. This is a sweet spot for available object detection methods that still avoids aggressive resizing, where small objects like smoke detectors or exit signs could disappear.

Figure 4 – Example of image tiling.
Pre-Labeling
To reduce the time effort and cost of training a custom object detection model, pre-labeling was introduced. Pre-labeling is a process of including a feedback loop in the labeling phase, as the initial model is trained using a small number of labeled images (approximately 100).
To achieve better generalization of a model trained on such a small dataset, new training examples are created out of the existing training dataset using image augmentation (such as rotating, cropping, shifting, and color modification). The model is used for initial population of the labeling tool with bounding boxes, converting the labeling task into refinement, where a user has to adjust existing boxes and labels, rather than starting from scratch.
Pre-labeling is based on periodically retraining the model after a new portion of labeled data is ready. The pre-labeling phase reduces the time needed to label a single panoramic image from approximately 20 minutes to five minutes.
Image Pre-Selection
Images taken from a building’s interior contain thousands of different objects. Labeling objects of interest means finding a few instances spread across hundreds of images. To improve efficiency, few-shot learning is introduced.
The method uses a pre-trained network, and freezes all but the classification layer such that the network can be fine-tuned using only a few samples of a novel class.
Detection accuracy of this model is not the priority since its sole purpose is to determine if an image contains a particular object. The confidence threshold is set to a low value, because some false positives are acceptable and the goal is to find as many objects as possible.
The trained model looks through a big dataset and selects images containing detections. Only selected images with accompanying bounding boxes are used for further refinement.
The image pre-selection phase reduces the number of images taken for further processing by up to 80%. Figure 4 shows results for the fire extinguisher class using the SSD ResNet50 FPN 1024×1024 model (TensorFlow2 implementation) with only eight training images.

Figure 5 – Example of image pre-selection.
Object Detection
The core of the solution is object detection, which determines what’s present in a picture and find its location. The model has to deal with a large variety in object sizes (from very big to very tiny) and an imbalanced dataset (such as over-represented class light and only a few examples of defibrillator) within a reasonable inference time.
YOLO (You Only Look Once) is a family of object detection models known for being highly performant yet incredibly small. Trained on a custom date, YOLOv5 outperformed EfficientDet and SSD families (implemented in TensorFlow2) and was selected as the main object detector.
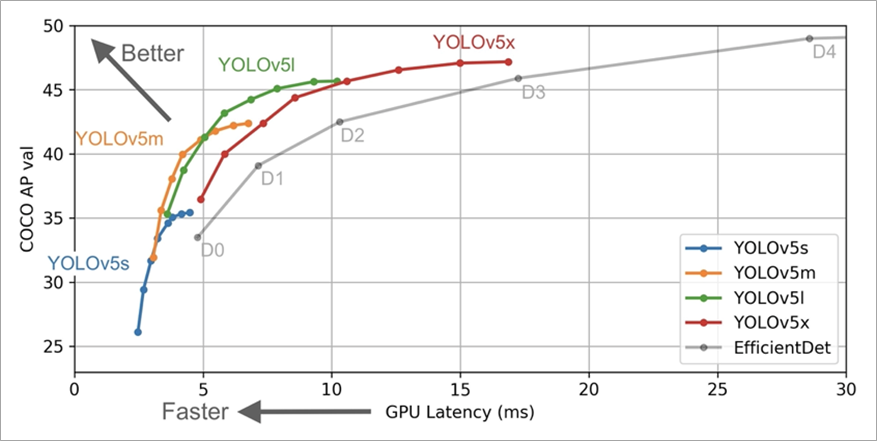
Figure 6 – Comparison of YOLOv5 with other frameworks.
Amazon SageMaker multi-GPU instances can speed up the computationally costly model training process. With an ml.p3.8xlarge instance, training with over 2,200 images is complete in under one hour, allowing for multiple training and evaluation sessions in a single day.
Mean average precision (mAP) for all classes is 81.6%, which is high, but single-image results aren’t very reflective in this case. Due to the iterative nature of the data acquisition (the robot is moving across the building and taking pictures with fixed time intervals), there’s usually more than one chance to spot a single object. The model is optimized for high precision, and multiple detections of a single instance are clustered in the postprocessing phase.
To enrich the detection capabilities of the system, Amazon Rekognition was included as another model, allowing it to find objects like door or staircase in the images. Amazon Rekognition is a cloud-based software-as-a-service (SaaS) computer vision platform.
Web Application
To enable users to easily use this solution for building inventory creation and visualization of the object detection pipeline results, a fully AWS-powered web application was built. The application is used to upload new scans, start a detection run with specific object detection models, evaluate and refine results, and export selected objects of interest to adjacent tools.
The serverless application uses the following AWS services:
- Deployment and hosting: AWS Amplify, AWS CloudFormation, and AWS CodePipeline
- User management: Amazon Cognito
- Backend: Amazon API Gateway, AWS Lambda, and AWS Step Functions
- Data persistence: Amazon DynamoDB
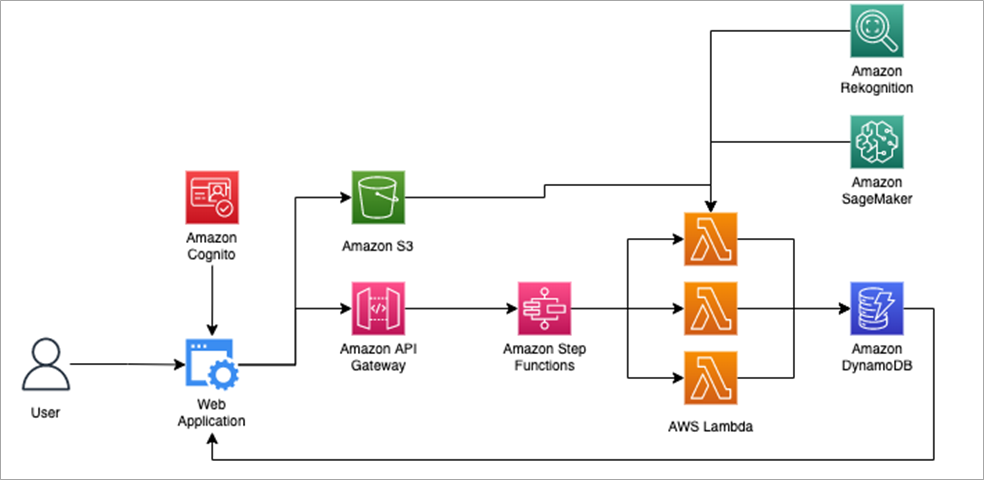
Figure 7 – Overall solution architecture.
Conclusion
In this post, we discussed how NavVis and AWS used object detection algorithms to create a digital building twin with object-level information.
Cost-intensive and slow, manual building inspections are replaced by highly scalable machine learning solutions in the cloud. The modular design of the solution makes it easy to onboard new datasets and models and extend its capabilities over time.
This shows that ML can play a significant role in driving efficiencies in facility management and help adapt buildings to customer’s needs.
.

.
NavVis – AWS Partner Spotlight
NavVis is an AWS Partner that supplies fast, reliable spatial data to service providers and enterprises seeking to capture photorealistic digital twins of the built environment. Its digital factory solutions enable greater organizational operability, productivity, agility, and profitability.