AWS Partner Network (APN) Blog
Zero Friction AWS Lambda Instrumentation: A Practical Guide to Extensions
By Saar Tochner, Team Leader – Lumigo
 |
| Lumigo |
 |
As serverless architectures start to grow, finding the right troubleshooting approach becomes a business-critical aspect.
In this post, I will dive into the “instrumentation approach” and how to keep track of internal events within an AWS Lambda function, and how to export processed telemetry data.
In my role at Lumigo, an AWS DevOps Competency Partner whose software-as-a-service (SaaS) platform helps companies monitor and troubleshoot serverless applications, I lead a team of extremely talented developers that builds the instrumentation tools of Lumigo.
The goal of my team is to provide frictionless instrumentation methods that users can instantly use in their serverless production environments. Here, I’ll share the knowledge on extensions that we gathered while pursuing these methods.
As with any real-life project, we will handle legacy code, multiple code owners, and a huge stack of serverless technologies. Our goal is to write as little code as possible, avoid changing existing code, support cross-runtime Lambda functions, and have no latency impact.
Below is a practical guide on how to use AWS Lambda Extensions. We’ll follow a storyline of extracting internal events from Lambda functions, processing them, and sending telemetry data to external services.
Big ambitions require great technology. Extensions to the rescue!
What are Troubleshooting Capabilities?
In a nutshell, a blindfolded programmer cannot achieve greatness solve bugs.
While working on serverless architectures, asynchronous operations happen all the time. A Lambda function triggered Amazon API Gateway, and an Amazon Simple Queue Service (SQS) message was written to Amazon Simple Storage Service (Amazon S3), while an Amazon DynamoDB stream triggers a Lambda function, and so on.
Troubleshooting a serverless architecture means being able to track down all of these events into a single “flow,” where the exception (when occurred) is on one end of the flow and the cause is on the other.
The main issue here is the data. We need to:
- Collect every event which may be related or interesting.
- Preprocess inside the Lambda environment (apply compliance rules, limit the size).
- Export telemetry for further processing.
Considering a real-world approach, we should be able to do it everywhere:
- Cross runtimes – be independent of the Lambda function’s runtime.
- No latency impact – the Lambda function should respond as fast as before.
- Bulletproof – never change the Lambda function’s flow.
We’ll use internal and external extensions to achieve our goals, as shown in this Lumigo blog post. Following, I’ll discuss two interesting features that are the core of our implementation: post-execution processing and pre-execution processing with wrappers.
Post-Execution Processing with External Extensions
External extensions are hooks the Amazon Web Services (AWS) infrastructure provides inside the Lambda container. The code of the extension runs independently of the Lambda runtime process and is integrated into the Lambda lifecycle.
By communicating with the Lambda function, the extension can gather information and process it in the post-execution time. This occurs after the Lambda function has returned its response and before the extensions are finished running.
More information about the lifecycle of a Lambda function can be found in the AWS documentation.
Being an external process allows us to write it in our favorite language, and it will work on any Lambda runtime (assuming the extension is wrapped as an executable binary).
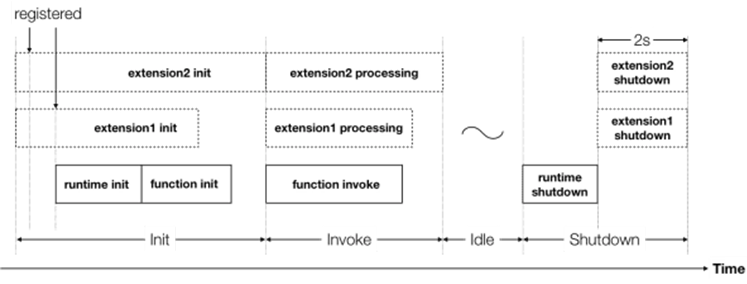
Figure 1 – AWS Lambda function lifecycle.
During the post-execution phase, we can process and export the telemetry data without interfering with the core invocation phase. Thus, we can avoid latency impact on the Lambda function, and the response will return as fast as it would without the extension.
At Lumigo, we use this phase to enforce privacy guarantees on the exported data (such as masking secrets and domains), and to ensure no private data escapes the Lambda environment. We use this timespan to limit data size and execute the exporting request itself.
Pre-Execution Processing with Wrappers
Wrappers, or internal extensions, are executable files that are executed during the container’s cold initialization, just before the runtime is initialized. It can be used to alter the runtime, modify environment variables, and execute code at the beginning of the process.
In our case, we use a wrapper to define the environment hooks that communicate with the external extension and transfer data. The external extension will later (in the post-execution time) take this data, process it, and export it.
This is a critical phase where we add some code lines that run in the Lambda function itself. More information about the communication methods between the internal and external extensions will be discussed in the next section.
At Lumigo, we’re wrapping all the HTTP requests of the Lambda function. When a Lambda function creates a request, we catch it and send it to the external extension. Using these sensors, we can reconstruct the full “flow” of the serverless architecture.
Extensions and Hooks Communication
To “move” the CPU or time-extensive logic from the execution phase to the post-execution phase, we must transfer the event’s data from the runtime’s process to the extension process.
There are different architectures that fit this use case and each has its own pros and cons.
Following, we’ll compare the most popular approaches: server-client, file system, and plain IPC.
In the performance tests, we transferred 1MB of data and checked it with Lambda function memory sizes: 128MB, 256MB, and 512MB.
- Server-client communication: The external extension serves as the server, and the hooks post data to it. An obvious pro here is that this is the most simple and elegant method. Another pro is reliability (the extension can return an acknowledgment, or ACK) which is achieved using TCP.
.
On the other hand, the performances are low: 80ms (128MB), 38ms (256MB), and 10ms (512MB). Slow or malfunctioned extensions may damage the execution time even more (due to the wait for an ACK).
. - File-system communication: The hooks write data to a special directory, and the extension reads from it only during the post-execution time. The biggest pro here is the lack of coupling between the two processes. The Lambda function’s main process will never be affected if the extension malfunctions.
.
On the other hand, the API should be implemented with care (in order to avoid miscommunication that may cause timeouts) and there is no reliability. The performances are much better here, with: 5.56ms (128MB), 3ms (256MB), and 1ms (512MB).
. - Intra-process-communication (IPC): The extensions and hooks communicate over operating system (OS) syscalls. This is a very raw method and, thus, very fast (2-3 microseconds), but it’s hard to implement and doesn’t have any out-of-the-box reliable communication.
To sum it up, there are many different architectures with their own pros and cons. Your specific use case should inform the choice of one over the other. A brief summary can be found in the following table:
| Performance (128 / 256 /512MB) | Reliability | Internal-External Decoupling | Implementation Size | |
| Server-Client | 80 / 38 /10ms | Yes | No | Small |
| File-System | 5.56 / 3 / 1ms | No | Yes | Medium |
| IPC | ~2.5 μs | No (no out-of-the-box solution) | No | Large |
At Lumigo, we decided to use the file-system approach, as it’s relatively clean to implement and ensures high decoupling between the processes. This way, we answer to both performance and isolation requirements, and also write elegant code that can be maintained better.
Implementation
External Extension
An external extension is an executable file that contains two important parts: the register and the extension loop.
We decided to write our extension in a higher-level language (Node.js 14.x) and compiled it into an executable that could be run in the Lambda runtime environment.
In order for the Lambda service to identify this file as an extension, it needs to be executable and packed inside a layer, under a directory named ‘extensions’.
Register happens in the bootstrap time of the container and is the first communication with the Lambda service:
Note that a common fallback here is the “extension-name” should be equal to the name of the file. More information can be found in the AWS documentation.
Next, the extension loop queries for the next event from the Lambda service:
This ‘urlopen’ request blocks the execution of the program when there’s no waiting invocation.
Note there is no need to define a timeout here; the container is being halted when there is no invocation, so this call will not get enough CPU to reach its timeout.
More in-depth code examples can be found in AWS official samples.
Internal Extension
In general, a do-nothing internal extension is much simpler and looks like this:
In order for the Lambda service to use this wrapper script, we need to add the environment variable AWS_LAMBDA_EXEC_WRAPPER with the path to this file.
At Lumigo, we use different methods to wrap the HTTP requests in different runtimes. For example, in the pythonic wrapper, we use the library wrapt to keep track of the most commonly-used function for HTTP communication (used by AWS SDK, requests, and many others):
Conclusion
Using the advanced tools that AWS Lambda provides, you can create robust mechanisms that answer core demands in serverless architectures.
In this post, I explored how to use external and internal extensions to create an instrumentation tool that extracts data from the Lambda function, processes, and exports it, and with almost no latency hit.
I also showed how most of the code could be written just once, in the external extension part, thus avoiding unnecessary code repetition and allowing fast adoption across different runtimes in the project.
Check out Lumigo’s serverless solution to learn more. We already implemented all of the above, and more, to provide you with a full monitoring and troubleshooting solution, tailored to fit your serverless architectures.
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
.

.
Lumigo – AWS Partner Spotlight
Lumigo is an AWS Competency Partner whose SaaS platform helps companies monitor and troubleshoot serverless applications.
Contact Lumigo | Partner Overview | AWS Marketplace
*Already worked with Lumigo? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.