AWS Big Data Blog

Author: Dhiraj Thakur
Dhiraj Thakur is a Solutions Architect with Amazon Web Services. He works with AWS customers and partners to provide guidance on enterprise cloud adoption, migration, and strategy. He is passionate about technology and enjoys building and experimenting in the analytics and AI/ML space.

Build a real-time GDPR-aligned Apache Iceberg data lake
Data lakes are a popular choice for today’s organizations to store their data around their business activities. As a best practice of a data lake design, data should be immutable once stored. But regulations such as the General Data Protection Regulation (GDPR) have created obligations for data operators who must be able to erase or […]

Create single output files for recipe jobs using AWS Glue DataBrew
July 2023: This post was reviewed for accuracy. AWS Glue DataBrew offers over 350 pre-built transformations to automate data preparation tasks (such as filtering anomalies, standardizing formats, and correcting invalid values) that would otherwise require days or weeks writing hand-coded transformations. You can now choose single or multiple output files instead of autogenerated files for […]

Write prepared data directly into JDBC-supported destinations using AWS Glue DataBrew
July 2023: This post was reviewed for accuracy. AWS Glue DataBrew offers over 250 pre-built transformations to automate data preparation tasks (such as filtering anomalies, standardizing formats, and correcting invalid values) that would otherwise require days or weeks writing hand-coded transformations. You can now write cleaned and normalized data directly into JDBC-supported databases and data […]
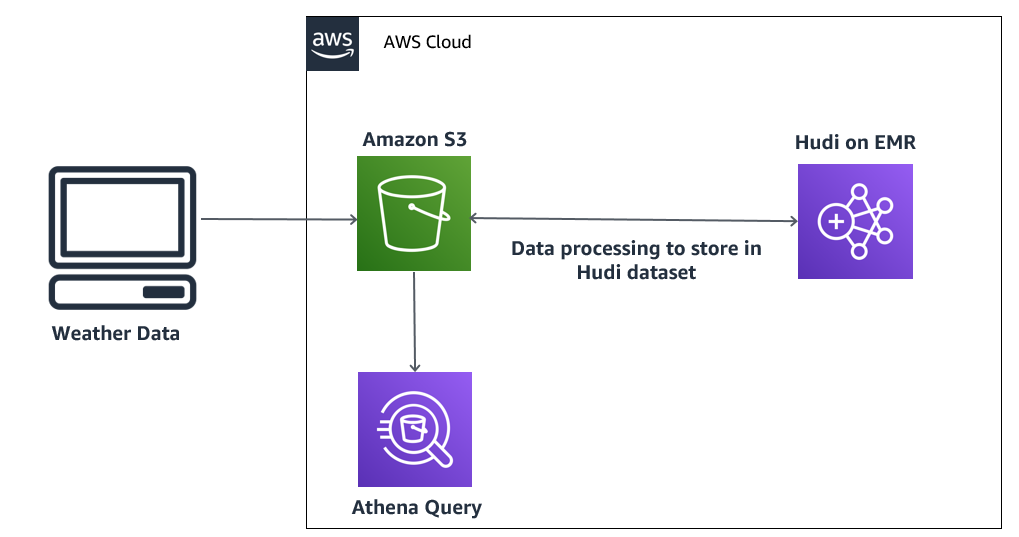
Query an Apache Hudi dataset in an Amazon S3 data lake with Amazon Athena part 1: Read-optimized queries
July 2023: This post was reviewed for accuracy. On July 16, 2021, Amazon Athena upgraded its Apache Hudi integration with new features and support for Hudi’s latest 0.8.0 release. Hudi is an open-source storage management framework that provides incremental data processing primitives for Hadoop-compatible data lakes. This upgraded integration adds the latest community improvements to […]
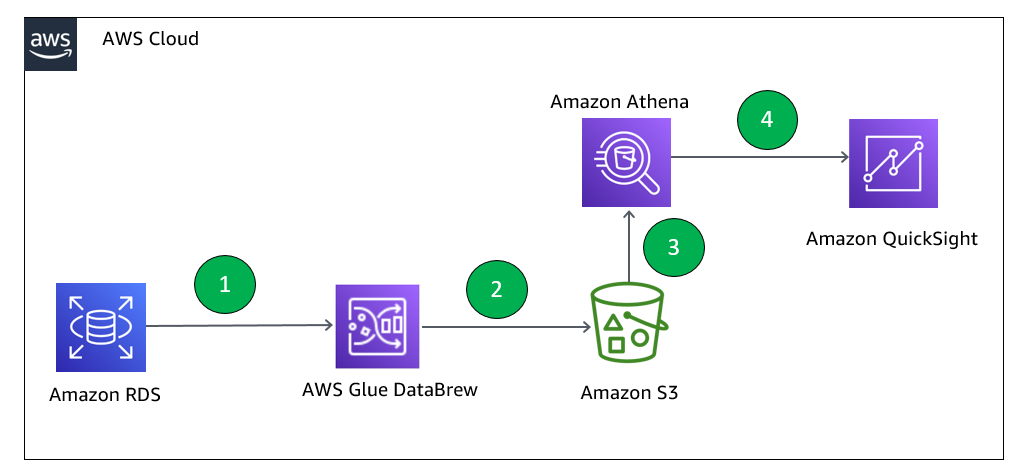
Data preparation using an Amazon RDS for MySQL database with AWS Glue DataBrew
With AWS Glue DataBrew, data analysts and data scientists can easily access and visually explore any amount of data across their organization directly from their Amazon Simple Storage Service (Amazon S3) data lake, Amazon Redshift data warehouse, or Amazon Aurora and Amazon Relational Database Service (Amazon RDS) databases. You can choose from over 250 built-in […]

Data preparation using Amazon Redshift with AWS Glue DataBrew
July 2023: This post was reviewed for accuracy. With AWS Glue DataBrew, data analysts and data scientists can easily access and visually explore any amount of data across their organization directly from their Amazon Simple Storage Service (Amazon S3) data lake, Amazon Redshift data warehouse, Amazon Aurora, and other Amazon Relational Database Service (Amazon RDS) databases. You can choose from over […]

Build a data lake using Amazon Kinesis Data Streams for Amazon DynamoDB and Apache Hudi
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. July 2023: This post was reviewed for accuracy. Amazon DynamoDB helps you capture high-velocity data such as clickstream data to form customized user profiles and online order […]

Building AWS Data Lake visualizations with Amazon Athena and Tableau
July 2023: This post was reviewed for accuracy. Amazon Athena is an interactive query service that makes it easy to analyze data in a data lake using standard SQL. One of the key elements of Athena is that you only pay for the queries you run. This is an attractive feature because there is no […]