AWS Big Data Blog
Category: AWS Glue

Improve DynamoDB analytics with AWS Glue zero-ETL schema and partition controls
In this post, you learn how to replicate Amazon DynamoDB data to Apache Iceberg tables in Amazon S3 through a zero-ETL integration. We walk through the challenges that the DynamoDB nested, schema-flexible data model introduces for analytics workloads, and show you how to configure schema unnesting and data partitioning for a sample product catalog table. We also cover how to query the replicated data in Amazon Athena using standard SQL.

Using Apache Sedona with AWS Glue to process billions of daily points from a geospatial dataset
In this post, we explore how to use Apache Sedona with AWS Glue to process and analyze massive geospatial datasets.

Building unified data pipelines with Apache Iceberg and Apache Flink
In this post, you build a unified pipeline using Apache Iceberg and Amazon Managed Service for Apache Flink that replaces the dual-pipeline approach. This walkthrough is for intermediate AWS users who are comfortable with Amazon Simple Storage Service (Amazon S3) and AWS Glue Data Catalog but new to streaming from Apache Iceberg tables.

Build AWS Glue Data Quality pipeline using Terraform
AWS Glue Data Quality is a feature of AWS Glue that helps maintain trust in your data and support better decision-making and analytics across your organization. You can use Terraform to deploy AWS Glue Data Quality pipelines. Using Terraform to deploy AWS Glue Data Quality pipeline enables IaC best practices to ensure consistent, version controlled and repeatable deployments across multiple environments, while fostering collaboration and reducing errors due to manual configuration. In this post, we explore two complementary methods for implementing AWS Glue Data Quality using Terraform.

Extract data from Amazon Aurora MySQL to Amazon S3 Tables in Apache Iceberg format
In this post, you learn how to set up an automated, end-to-end solution that extracts tables from Amazon Aurora MySQL Serverless v2 and writes them to Amazon S3 Tables in Apache Iceberg format using AWS Glue.

Implement a data mesh pattern in Amazon SageMaker Catalog without changing applications
In this post, we walk through simulating a scenario based on data producer and data consumer that exists before Amazon SageMaker Catalog adoption. We use a sample dataset to simulate existing data and an existing application using an AWS Lambda function, then implement a data mesh pattern using Amazon SageMaker Catalog while keeping your current data repositories and consumer applications unchanged.
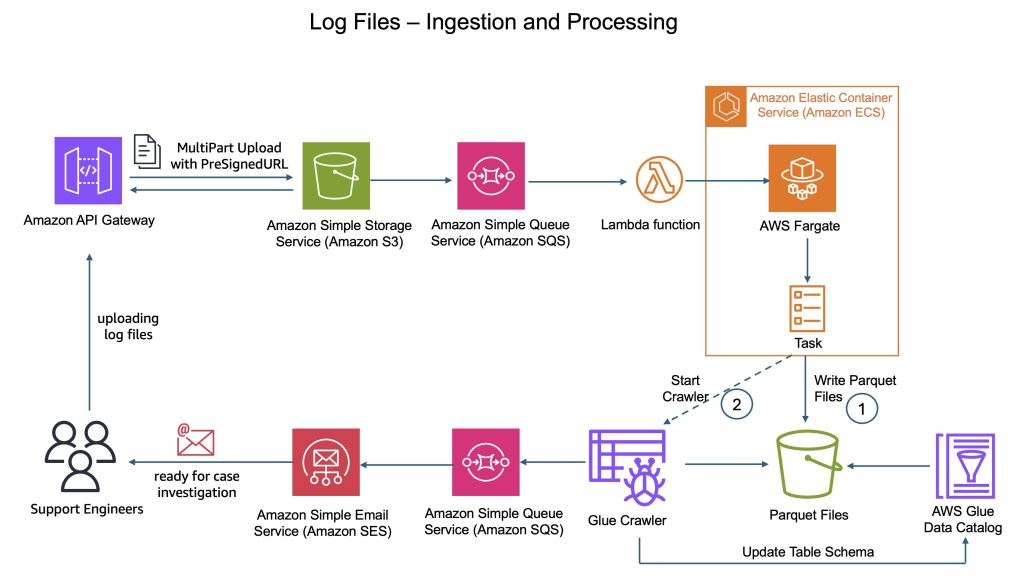
How CyberArk uses Apache Iceberg and Amazon Bedrock to deliver up to 4x support productivity
CyberArk is a global leader in identity security. Centered on intelligent privilege controls, it provides comprehensive security for human, machine, and AI identities across business applications, distributed workforces, and hybrid cloud environments. In this post, we show you how CyberArk redesigned their support operations by combining Iceberg’s intelligent metadata management with AI-powered automation from Amazon Bedrock. You’ll learn how to simplify data processing flows, automate log parsing for diverse formats, and build autonomous investigation workflows that scale automatically.

Build a data pipeline from Google Search Console to Amazon Redshift using AWS Glue
In this post, we explore how AWS Glue extract, transform, and load (ETL) capabilities connect Google applications and Amazon Redshift, helping you unlock deeper insights and drive data-informed decisions through automated data pipeline management. We walk you through the process of using AWS Glue to integrate data from Google Search Console and write it to Amazon Redshift.
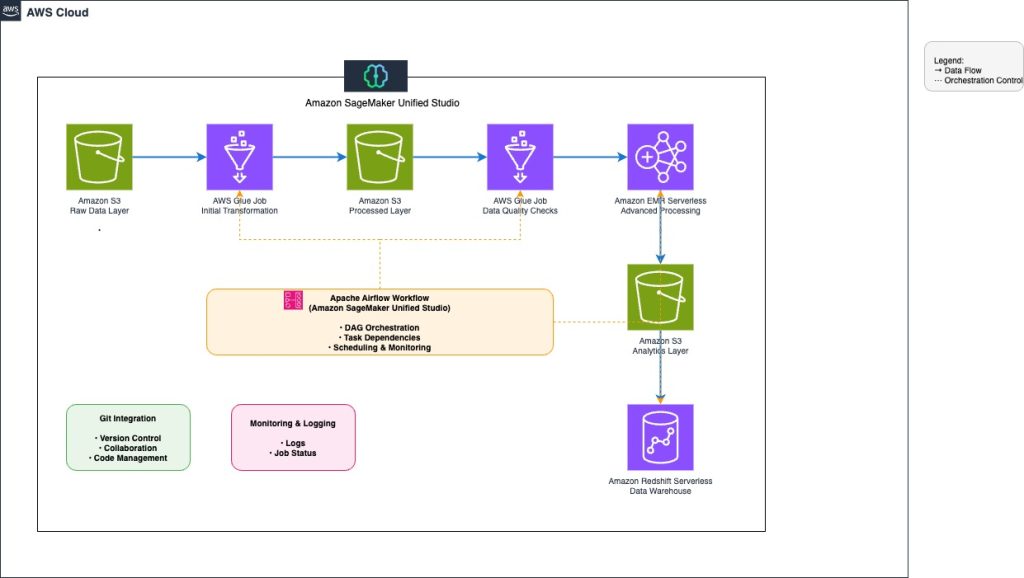
Orchestrate end-to-end scalable ETL pipeline with Amazon SageMaker workflows
This post explores how to build and manage a comprehensive extract, transform, and load (ETL) pipeline using SageMaker Unified Studio workflows through a code-based approach. We demonstrate how to use a single, integrated interface to handle all aspects of data processing, from preparation to orchestration, by using AWS services including Amazon EMR, AWS Glue, Amazon Redshift, and Amazon MWAA. This solution streamlines the data pipeline through a single UI.

Enable strategic data quality management with AWS Glue DQDL labels
AWS Glue DQDL labels add organizational context to data quality management by attaching business metadata directly to validation rules. In this post, we highlight the new DQDL labels feature, which enhances how you organize, prioritize, and operationalize your data quality efforts at scale. We show how labels such as business criticality, compliance requirements, team ownership, or data domain can be attached to data quality rules to streamline triage and analysis. You’ll learn how to quickly surface targeted insights (for example, “all high-priority customer data failures owned by marketing” or “GDPR-related issues from our Salesforce ingestion pipeline”) and how DQDL labels can help teams improve accountability and accelerate remediation workflows.