AWS Big Data Blog
Category: AWS Glue

Enterprise scale in-place migration to Apache Iceberg: Implementation guide
Organizations managing large-scale analytical workloads increasingly face challenges with traditional Apache Parquet-based data lakes with Hive-style partitioning, including slow queries, complex file management, and limited consistency guarantees. Apache Iceberg addresses these pain points by providing ACID transactions, seamless schema evolution, and point-in-time data recovery capabilities that transform how enterprises handle their data infrastructure. In this post, we demonstrate how you can achieve migration at scale from existing Parquet tables to Apache Iceberg tables. Using Amazon DynamoDB as a central orchestration mechanism, we show how you can implement in-place migrations that are highly configurable, repeatable, and fault-tolerant.
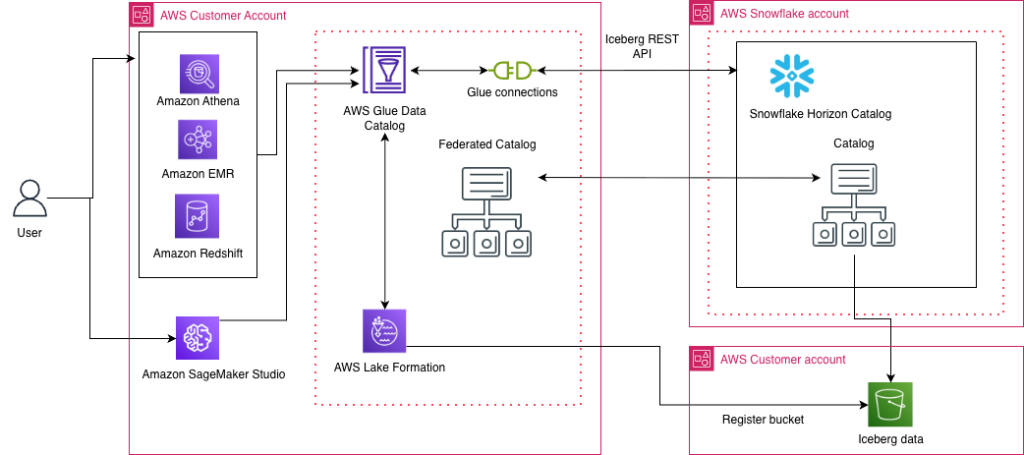
Access Snowflake Horizon Catalog data using catalog federation in the AWS Glue Data Catalog
AWS has introduced a new catalog federation feature that enables direct access to Snowflake Horizon Catalog data through AWS Glue Data Catalog. This integration allows organizations to discover and query data in Iceberg format while maintaining security through AWS Lake Formation. This post provides a step-by-step guide to establishing this integration, including configuring Snowflake Horizon Catalog, setting up authentication, creating necessary IAM roles, and implementing AWS Lake Formation permissions. Learn how to enable cross-platform analytics while maintaining robust security and governance across your data environment.
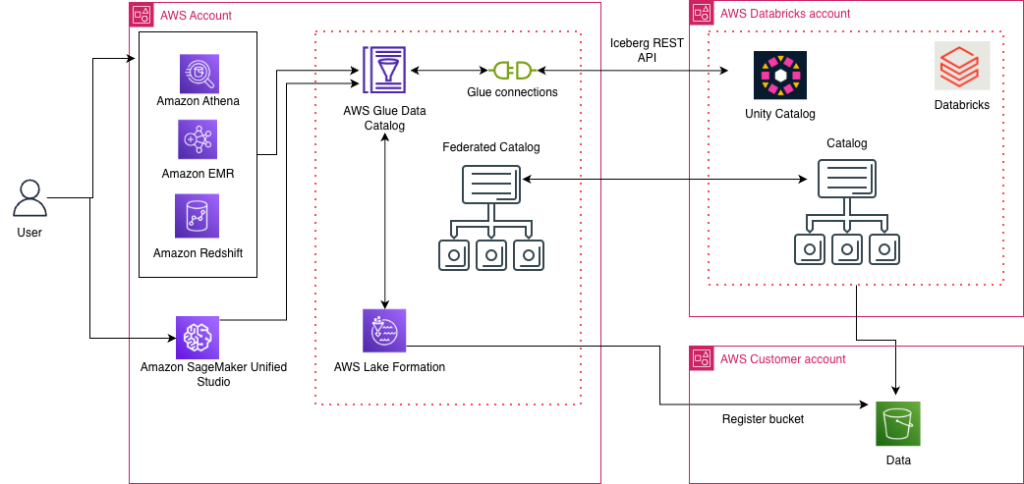
Access Databricks Unity Catalog data using catalog federation in the AWS Glue Data Catalog
AWS has launched the catalog federation capability, enabling direct access to Apache Iceberg tables managed in Databricks Unity Catalog through the AWS Glue Data Catalog. With this integration, you can discover and query Unity Catalog data in Iceberg format using an Iceberg REST API endpoint, while maintaining granular access controls through AWS Lake Formation. In this post, we demonstrate how to set up catalog federation between the Glue Data Catalog and Databricks Unity Catalog, enabling data querying using AWS analytics services.
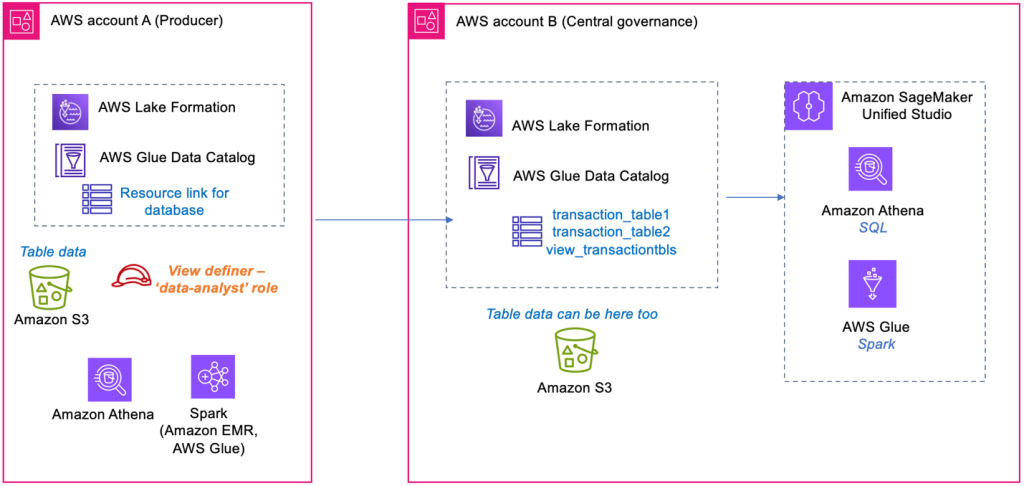
Create AWS Glue Data Catalog views using cross-account definer roles
In this post, we demonstrate how to use cross-account IAM definer roles with AWS Glue Data Catalog views. We show how data owner accounts can create and manage views in a central governance account while maintaining security and control over their data assets.

AWS analytics at re:Invent 2025: Unifying Data, AI, and governance at scale
re:Invent 2025 showcased the bold Amazon Web Services (AWS) vision for the future of analytics, one where data warehouses, data lakes, and AI development converge into a seamless, open, intelligent platform, with Apache Iceberg compatibility at its core. Across over 18 major announcements spanning three weeks, AWS demonstrated how organizations can break down data silos, […]

Create and update Apache Iceberg tables with partitions in the AWS Glue Data Catalog using the AWS SDK and AWS CloudFormation
In this post, we show how to create and update Iceberg tables with partitions in the Data Catalog using the AWS SDK and AWS CloudFormation.

Introducing the Apache Spark troubleshooting agent for Amazon EMR and AWS Glue
In this post, we show you how the Apache Spark troubleshooting agent helps analyze Apache Spark issues by providing detailed root causes and actionable recommendations. You’ll learn how to streamline your troubleshooting workflow by integrating this agent with your existing monitoring solutions across Amazon EMR and AWS Glue.

Introducing Apache Iceberg materialized views in AWS Glue Data Catalog
Hundreds of thousands of customers build artificial intelligence and machine learning (AI/ML) and analytics applications on AWS, frequently transforming data through multiple stages for improved query performance—from raw data to processed datasets to final analytical tables. Data engineers must solve complex problems, including detecting what data has changed in base tables, writing and maintaining transformation […]

Introducing AWS Glue 5.1 for Apache Spark
AWS recently announced Glue 5.1, a new version of AWS Glue that accelerates data integration workloads in AWS. AWS Glue 5.1 upgrades the Spark engines to Apache Spark 3.5.6, giving you newer Spark release along with the newer dependent libraries so you can develop, run, and scale your data integration workloads and get insights faster. In this post, we describe what’s new in AWS Glue 5.1, key highlights on Spark and related libraries, and how to get started on AWS Glue 5.1.

SAP data ingestion and replication with AWS Glue zero-ETL
AWS Glue zero-ETL with SAP now supports data ingestion and replication from SAP data sources such as Operational Data Provisioning (ODP) managed SAP Business Warehouse (BW) extractors, Advanced Business Application Programming (ABAP), Core Data Services (CDS) views, and other non-ODP data sources. Zero-ETL data replication and schema synchronization writes extracted data to AWS services like Amazon Redshift, Amazon SageMaker lakehouse, and Amazon S3 Tables, alleviating the need for manual pipeline development. In this post, we show how to create and monitor a zero-ETL integration with various ODP and non-ODP SAP sources.