AWS Big Data Blog
Category: AWS Glue

Building an ad-to-order conversion engine with Amazon Kinesis, AWS Glue, and Amazon QuickSight
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Businesses in ecommerce have the challenge of measuring their ad-to-order conversion ratio for ads or promotional campaigns displayed on a webpage. Tracking the number of users that […]

Preparing data for ML models using AWS Glue DataBrew in a Jupyter notebook
AWS Glue DataBrew is a new visual data preparation tool that makes it easy for data analysts and data scientists to clean and normalize data to prepare it for analytics and machine learning (ML). In this post, we examine a sample ML use case and show how to use DataBrew and a Jupyter notebook to […]

Enabling self-service data publication to your data lake using AWS Glue DataBrew
Data lakes have been providing a level of flexibility to organizations unparalleled to anything before them. Having the ability to load and query data in place—and in its natural form—has led to an explosion of data lake deployments that have allowed organizations to accelerate against their data strategy faster than ever before. Most organizations have […]

Data monetization and customer experience optimization using telco data assets: Part 1
The landscape of the telecommunications industry is changing rapidly. For telecom service providers (TSPs), revenue from core voice and data services continues to shrink due to regulatory pressure and emerging OTT players that offer an attractive alternative. Despite increasing demand from customers for bandwidth, speed, and efficiency, TSPs are finding that ROI from implementing new […]

Keeping your data lake clean and compliant with Amazon Athena
June 2025: This post has been reviewed for accuracy and the following updates have been made: added new function to retrieve SQL query in the Lambda code; upgraded Python’s run time and version of sqlparse in the Lambda deployment package; added and removed actions in the Lambda policy; updated the CloudFormation template to reflect policy […]
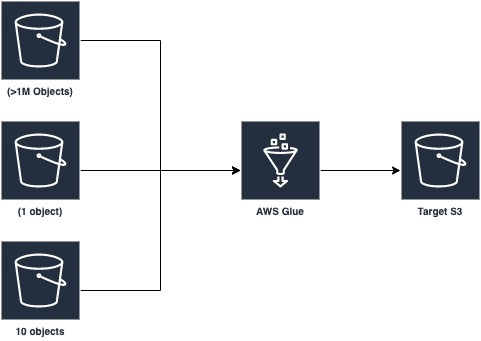
Optimizing Spark applications with workload partitioning in AWS Glue
AWS Glue provides a serverless environment to prepare (extract and transform) and load large amounts of datasets from a variety of sources for analytics and data processing with Apache Spark ETL jobs. This posts discusses a new AWS Glue Spark runtime optimization that helps developers of Apache Spark applications and ETL jobs, big data architects, […]

Data preprocessing for machine learning on Amazon EMR made easy with AWS Glue DataBrew
The machine learning (ML) lifecycle consists of several key phases: data collection, data preparation, feature engineering, model training, model evaluation, and model deployment. The data preparation and feature engineering phases ensure an ML model is given high-quality data that is relevant to the model’s purpose. Because most raw datasets require multiple cleaning steps (such as […]

Managing COVID-19 exposure with crowd tracing
This is a guest blog post by AWS partner Aspire Ventures As we enter winter, with fewer options to be outdoors, our personal choices can impact our risk of contracting the COVID-19 virus even more. The New England Journal of Medicine publication showed real-world examples of the effectiveness of masks and social distancing in mitigating […]

Building Python modules from a wheel for Spark ETL workloads using AWS Glue 2.0
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load your data for analytics. AWS Glue 2.0 features an upgraded infrastructure for running Apache Spark ETL jobs in AWS Glue with reduced startup times. With reduced startup delay time and lower minimum billing duration, overall […]

Creating a source to Lakehouse data replication pipe using Apache Hudi, AWS Glue, AWS DMS, and Amazon Redshift
February 2021 update – Please refer to the post Writing to Apache Hudi tables using AWS Glue Custom Connector to learn about an easier mechanism to write to Hudi tables using AWS Glue Custom Connector. In this post, we include the modified Apache Hudi JARs as an external dependency. The AWS Glue Custom Connector feature […]