AWS Big Data Blog
Category: Advanced (300)

How to choose the right Amazon MSK cluster type for you
March 2025: This post was reviewed and updated for accuracy. Amazon Managed Streaming for Apache Kafka (Amazon MSK) is an AWS streaming data service that manages Apache Kafka infrastructure and operations, making it easy for developers and DevOps managers to run Apache Kafka applications and Kafka Connect connectors on AWS, without the need to become […]
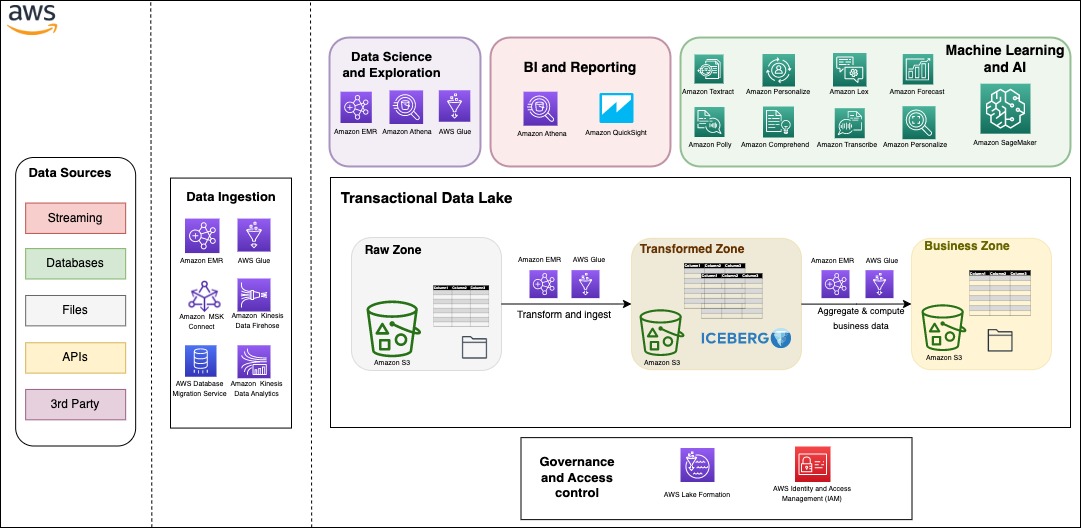
Build a serverless transactional data lake with Apache Iceberg, Amazon EMR Serverless, and Amazon Athena
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Data lakes have served as a central repository to store structured and unstructured data at any scale and in various formats. However, as data processing at scale solutions grow, organizations need […]

Enhance your analytics embedding experience with the new Amazon QuickSight JavaScript SDK
Amazon QuickSight is a fully managed, cloud-native business intelligence (BI) service that makes it easy to connect to your data, create interactive dashboards and reports, and share these with tens of thousands of users, either within QuickSight or embedded in your application or website. QuickSight recently launched a new major version of its Embedding SDK […]

Simplify data loading into Type 2 slowly changing dimensions in Amazon Redshift
Thousands of customers rely on Amazon Redshift to build data warehouses to accelerate time to insights with fast, simple, and secure analytics at scale and analyze data from terabytes to petabytes by running complex analytical queries. Organizations create data marts, which are subsets of the data warehouse and usually oriented for gaining analytical insights specific […]

Build an end-to-end change data capture with Amazon MSK Connect and AWS Glue Schema Registry
The value of data is time sensitive. Real-time processing makes data-driven decisions accurate and actionable in seconds or minutes instead of hours or days. Change data capture (CDC) refers to the process of identifying and capturing changes made to data in a database and then delivering those changes in real time to a downstream system. […]

Improve productivity by using keyboard shortcuts in Amazon Athena query editor
Amazon Athena is a serverless, interactive analytics service built on open-source frameworks, supporting open-table and file formats. Athena provides a simplified, flexible way to analyze petabytes of data where it lives. You can analyze data or build applications from an Amazon Simple Storage Service (Amazon S3) data lake and over 25 data sources, including on-premises […]

Use Apache Iceberg in a data lake to support incremental data processing
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. It adds tables to compute engines including Spark, Trino, PrestoDB, Flink, and Hive using a high-performance table format that works just like a SQL table. Iceberg has […]

Reduce Amazon EMR cluster costs by up to 19% with new enhancements in Amazon EMR Managed Scaling
In June 2020, AWS announced the general availability of Amazon EMR Managed Scaling. With EMR Managed Scaling, you specify the minimum and maximum compute limits for your clusters, and Amazon EMR automatically resizes your cluster for optimal performance and resource utilization. EMR Managed Scaling constantly monitors key workload-related metrics and uses an algorithm that optimizes the […]

Simplify Online Analytical Processing (OLAP) queries in Amazon Redshift using new SQL constructs such as ROLLUP, CUBE, and GROUPING SETS
Amazon Redshift is a fully managed, petabyte-scale, massively parallel data warehouse that makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. We are continuously investing to make analytics easy with Redshift by simplifying SQL constructs and adding new operators. Now we are adding […]

Build a real-time GDPR-aligned Apache Iceberg data lake
Data lakes are a popular choice for today’s organizations to store their data around their business activities. As a best practice of a data lake design, data should be immutable once stored. But regulations such as the General Data Protection Regulation (GDPR) have created obligations for data operators who must be able to erase or […]