AWS Big Data Blog
Build a serverless transactional data lake with Apache Iceberg, Amazon EMR Serverless, and Amazon Athena
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Data lakes have served as a central repository to store structured and unstructured data at any scale and in various formats. However, as data processing at scale solutions grow, organizations need to build more and more features on top of their data lakes. One important feature is to run different workloads such as business intelligence (BI), Machine Learning (ML), Data Science and data exploration, and Change Data Capture (CDC) of transactional data, without having to maintain multiple copies of data. Additionally, the task of maintaining and managing files in the data lake can be tedious and sometimes complex.
Table formats like Apache Iceberg provide solutions to these issues. They enable transactions on top of data lakes and can simplify data storage, management, ingestion, and processing. These transactional data lakes combine features from both the data lake and the data warehouse. You can simplify your data strategy by running multiple workloads and applications on the same data in the same location. However, using these formats requires building, maintaining, and scaling infrastructure and integration connectors that can be time-consuming, challenging, and costly.
In this post, we show how you can build a serverless transactional data lake with Apache Iceberg on Amazon Simple Storage Service (Amazon S3) using Amazon EMR Serverless and Amazon Athena. We provide an example for data ingestion and querying using an ecommerce sales data lake.
Apache Iceberg overview
Iceberg is an open-source table format that brings the power of SQL tables to big data files. It enables ACID transactions on tables, allowing for concurrent data ingestion, updates, and queries, all while using familiar SQL. Iceberg employs internal metadata management that keeps track of data and empowers a set of rich features at scale. It allows you to time travel and roll back to old versions of committed data transactions, control the table’s schema evolution, easily compact data, and employ hidden partitioning for fast queries.
Iceberg manages files on behalf of the user and unlocks use cases such as:
- Concurrent data ingestion and querying, including streaming and CDC
- BI and reporting with expressive simple SQL
- Empowering ML feature stores and training sets
- Compliance and regulations workloads, such as GDPR find and forget
- Reinstating late-arriving data, which is dimensions data arriving later than the fact data. For example, the reason for a flight delay may arrive well after the fact that the fligh is delayed.
- Tracking data changes and rollback
Build your transactional data lake on AWS
You can build your modern data architecture with a scalable data lake that integrates seamlessly with an Amazon Redshift powered cloud warehouse. Moreover, many customers are looking for an architecture where they can combine the benefits of a data lake and a data warehouse in the same storage location. In the following figure, we show a comprehensive architecture that uses the modern data architecture strategy on AWS to build a fully featured transactional data lake. AWS provides flexibility and a wide breadth of features to ingest data, build AI and ML applications, and run analytics workloads without having to focus on the undifferentiated heavy lifting.
Data can be organized into three different zones, as shown in the following figure. The first zone is the raw zone, where data can be captured from the source as is. The transformed zone is an enterprise-wide zone to host cleaned and transformed data in order to serve multiple teams and use cases. Iceberg provides a table format on top of Amazon S3 in this zone to provide ACID transactions, but also to allow seamless file management and provide time travel and rollback capabilities. The business zone stores data specific to business cases and applications aggregated and computed from data in the transformed zone.
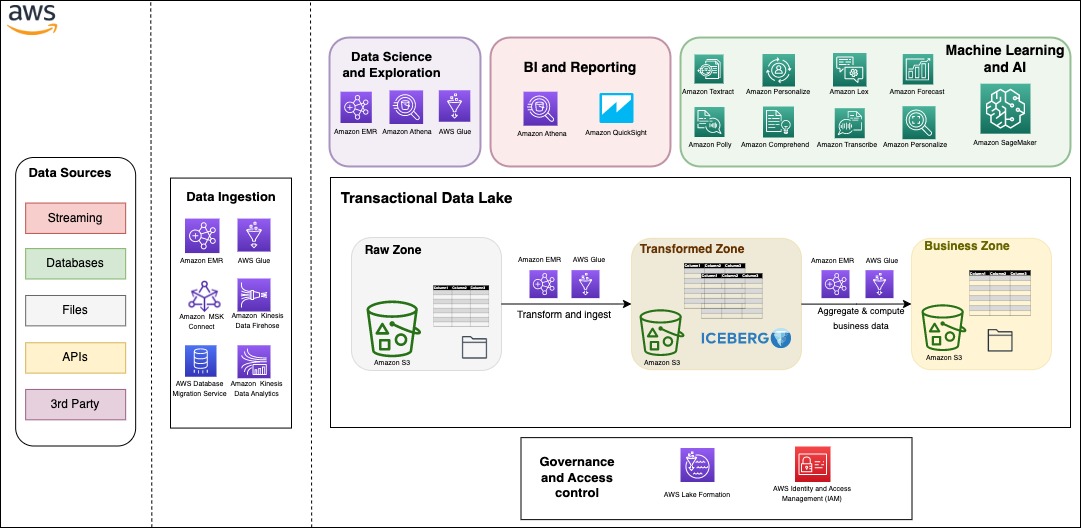
One important aspect to a successful data strategy for any organization is data governance. On AWS, you can implement a thorough governance strategy with fine-grained access control to the data lake with AWS Lake Formation.
Serverless architecture overview
In this section, we show you how to ingest and query data in your transactional data lake in a few steps. EMR Serverless is a serverless option that makes it easy for data analysts and engineers to run Spark-based analytics without configuring, managing, and scaling clusters or servers. You can run your Spark applications without having to plan capacity or provision infrastructure, while paying only for your usage. EMR Serverless supports Iceberg natively to create tables and query, merge, and insert data with Spark. In the following architecture diagram, Spark transformation jobs can load data from the raw zone or source, apply the cleaning and transformation logic, and ingest data in the transformed zone on Iceberg tables. Spark code can run instantaneously on an EMR Serverless application, which we demonstrate later in this post.
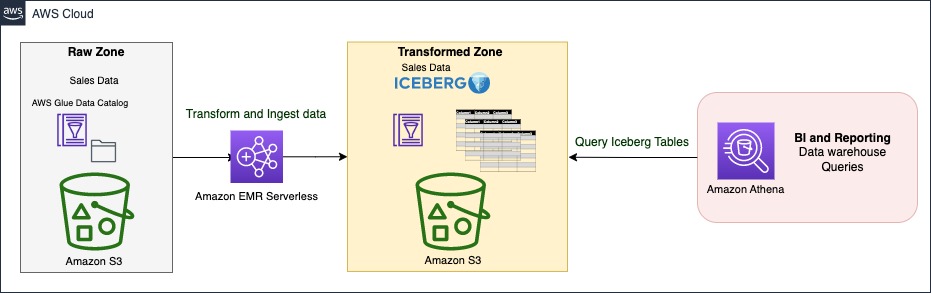
The Iceberg table is synced with the AWS Glue Data Catalog. The Data Catalog provides a central location to govern and keep track of the schema and metadata. With Iceberg, ingestion, update, and querying processes can benefit from atomicity, snapshot isolation, and managing concurrency to keep a consistent view of data.
Athena is a serverless, interactive analytics service built on open-source frameworks, supporting open-table and file formats. Athena provides a simplified, flexible way to analyze petabytes of data where it lives. To serve BI and reporting analysis, it allows you to build and run queries on Iceberg tables natively and integrates with a variety of BI tools.
Sales data model
Star schema and its variants are very popular for modeling data in data warehouses. They implement one or more fact tables and dimension tables. The fact table stores the main transactional data from the business logic with foreign keys to dimensional tables. Dimension tables hold additional complementary data to enrich the fact table.
In this post, we take the example of sales data from the TPC-DS benchmark. We zoom in on a subset of the schema with the web_sales fact table, as shown in the following figure. It stores numeric values about sales cost, ship cost, tax, and net profit. Additionally, it has foreign keys to dimensional tables like date_dim, time_dim, customer, and item. These dimensional tables store records that give more details. For instance, you can show when a sale took place by which customer for which item.
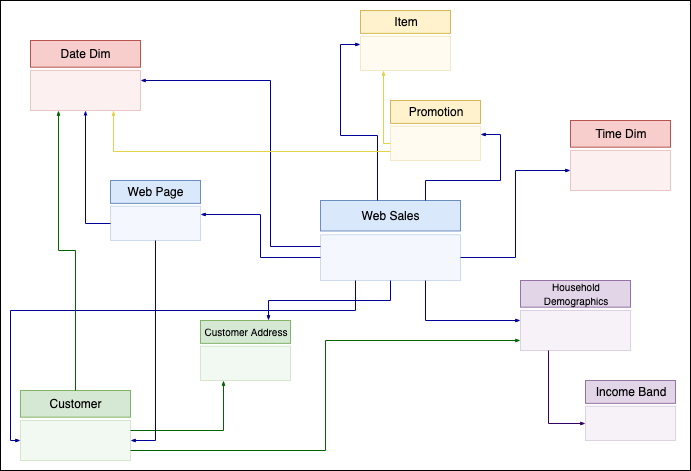
Dimension-based models have been used extensively to build data warehouses. In the following sections, we show how to implement such a model on top of Iceberg, providing data warehousing features on top of your data lake, and run different workloads in the same location. We provide a complete example of building a serverless architecture with data ingestion using EMR Serverless and Athena using TPC-DS queries.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account
- Basic knowledge about data management and SQL
Deploy solution resources with AWS CloudFormation
We provide an AWS CloudFormation template to deploy the data lake stack with the following resources:
- Two S3 buckets: one for scripts and query results, and one for the data lake storage
- An Athena workgroup
- An EMR Serverless application
- An AWS Glue database and tables on external public S3 buckets of TPC-DS data
- An AWS Glue database for the data lake
- An AWS Identity and Access Management (IAM) role and polices
Complete the following steps to create your resources:
- Launch the CloudFormation stack:
![]()
This automatically launches AWS CloudFormation in your AWS account with the CloudFormation template. It prompts you to sign in as needed.
- Keep the template settings as is.
- Check the I acknowledge that AWS CloudFormation might create IAM resources box.
- Choose Submit
When the stack creation is complete, check the Outputs tab of the stack to verify the resources created.
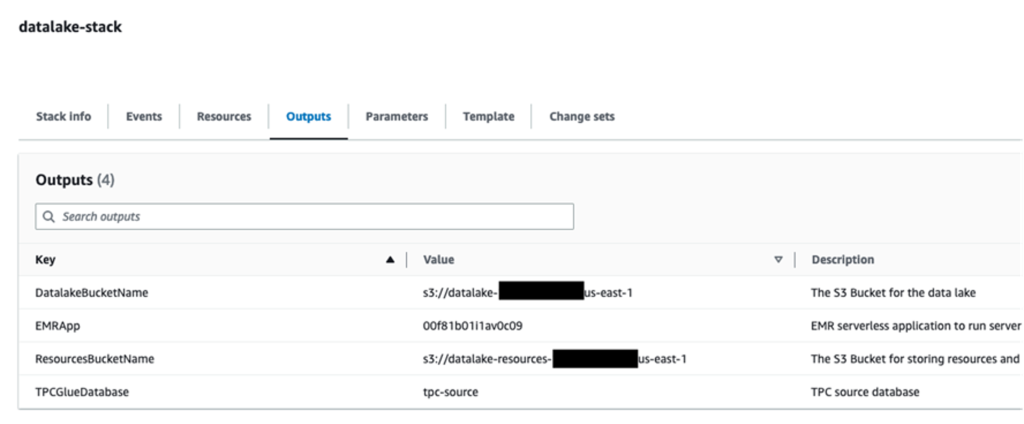
Upload Spark scripts to Amazon S3
Complete the following steps to upload your Spark scripts:
- Download the following scripts: ingest-iceberg.py and update-item.py.
- On the Amazon S3 console, go to the
datalake-resources-<AccountID>-us-east-1bucket you created earlier. - Create a new folder named
scripts. - Upload the two PySpark scripts:
ingest-iceberg.pyandupdate-item.py.
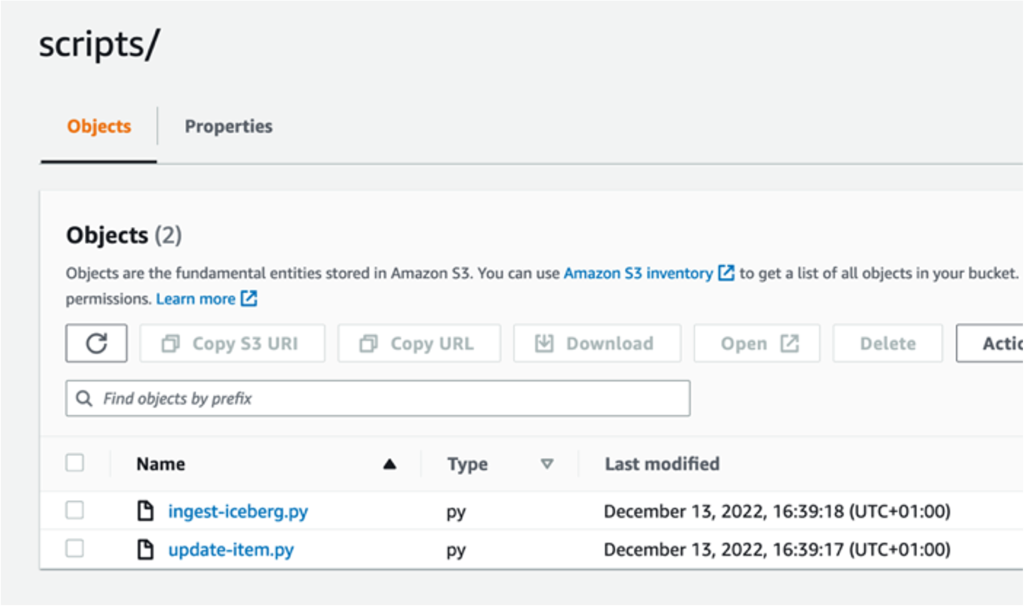
Create Iceberg tables and ingest TPC-DS data
To create your Iceberg tables and ingest the data, complete the following steps:
- On the Amazon EMR console, choose EMR Serverless in the navigation pane.
- Choose Manage applications.
- Choose the application
datalake-app.

- Choose Start application.
Once started, it will provision the pre-initialized capacity as configured at creation (one Spark driver and two Spark executors). The pre-initialized capacity are resources that will be provisioned when you start your application. They can be used instantly when you submit jobs. However, they incur charges even if they’re not used when the application is in a started state. By default, the application is set to stop when idle for 15 minutes.
Now that the EMR application has started, we can submit the Spark ingest job ingest-iceberg.py. The job creates the Iceberg tables and then loads data from the previously created AWS Glue Data Catalog tables on TPC-DS data in an external bucket.
- Navigate to the
datalake-app. - On the Job runs tab, choose Submit job.
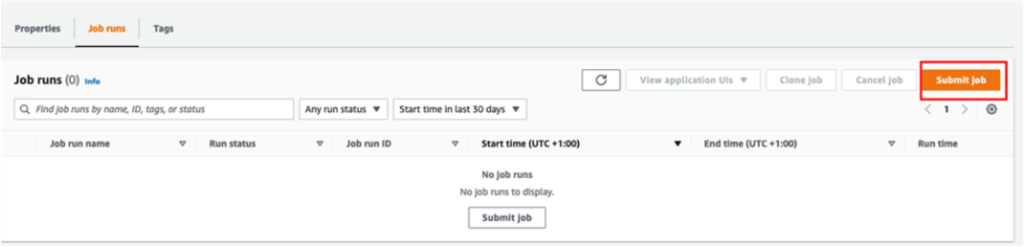
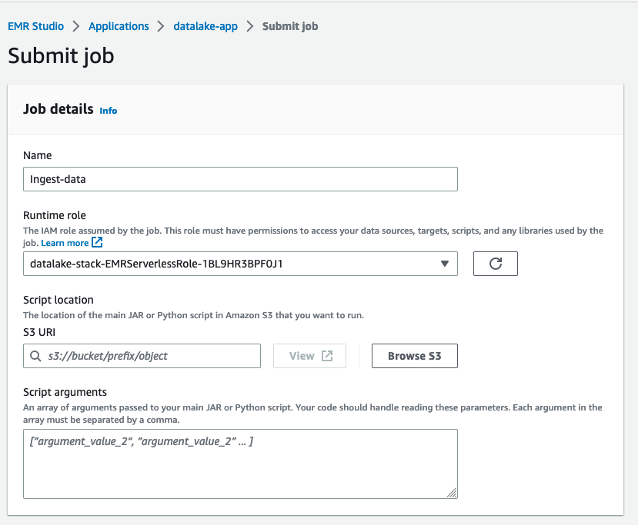
- For Name, enter
ingest-data. - For Runtime role, choose the IAM role created by the CloudFormation stack.
- For Script location, enter the S3 path for your resource bucket (
datalake-resource-<####>-us-east-1>scripts>ingest-iceberg.py).
- Under Spark properties, choose Edit in text.
- Enter the following properties, replacing <BUCKET_NAME> with your data lake bucket name
datalake-<####>-us-east-1(not datalake-resources)
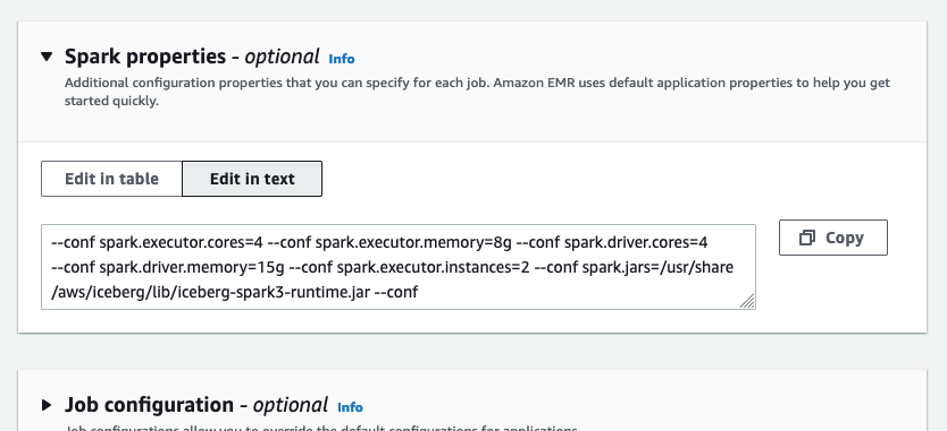
- Submit the job.
You can monitor the job progress. 
Query Iceberg tables
In this section, we provide examples of data warehouse queries from TPC-DS on the Iceberg tables.
- On the Athena console, open the query editor.
- For Workgroup, switch to
DatalakeWorkgroup.

- Choose Acknowledge.
 The queries in
The queries in DatalakeWorkgroup will run on Athena engine version 3.
- On the Saved queries tab, choose a query to run on your Iceberg tables.
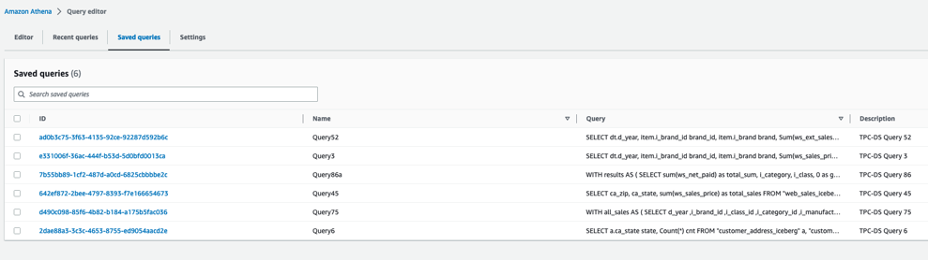 The following queries are listed:
The following queries are listed:
- Query3 – Report the total extended sales price per item brand of a specific manufacturer for all sales in a specific month of the year.
- Query45 – Report the total web sales for customers in specific zip codes, cities, counties, or states, or specific items for a given year and quarter.
- Query52 – Report the total of extended sales price for all items of a specific brand in a specific year and month.
- Query6 – List all the states with at least 10 customers who during a given month bought items with the price tag at least 20% higher than the average price of items in the same category.
- Query75 – For 2 consecutive years, track the sales of items by brand, class, and category.
- Query86a – Roll up the web sales for a given year by category and class, and rank the sales among peers within the parent. For each group, compute the sum of sales and location with the hierarchy and rank within the group.
These queries are examples of queries used in decision-making and reporting in an organization. You can run them in the order you want. For this post, we start with Query3.
- Before you run the query, confirm that Database is set to
datalake.

- Now you can run the query.

- Repeat these steps to run the other queries.
Update the item table
After running the queries, we prepare a batch of updates and inserts of records into the item table.
- First, run the following query to count the number of records in the
itemIceberg table:
This should return 102,000 records.
- Select item records with a price higher than $90:
This will return 1,112 records.
The update-item.py job takes these 1,112 records, modifies 11 records to change the name of the brand to Unknown, and changes the remaining 1,101 records’ i_item_id key to flag them as new records. As a result, a batch of 11 updates and 1,101 inserts are merged into the item_iceberg table.
The 11 records to be updated are those with price higher than $90, and the brand name starts with corpnameless.
- Run the following query:
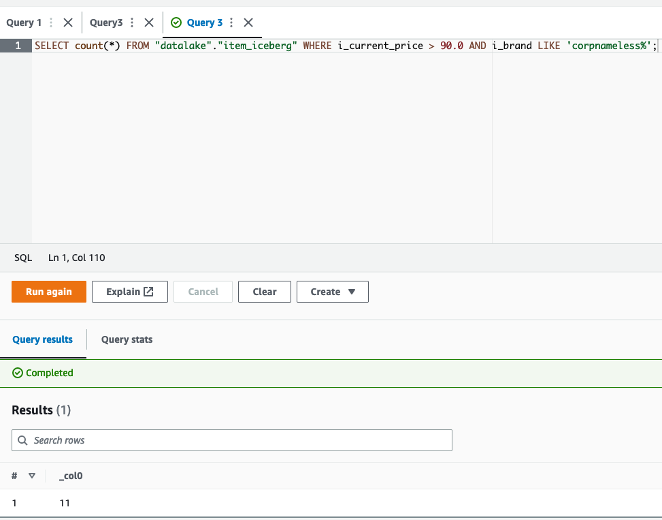
The result is 11 records. The item_update.py job replaces the brand name with Unknown and merges the batch into the Iceberg table.
Now you can return to the EMR Serverless console and run the job on the EMR Serverless application.
- On the application details page, choose Submit job.
- For Name, enter
update-item-job. - For Runtime role¸ use the same role that you used previously.
- For S3 URI, enter the
update-item.pyscript location.
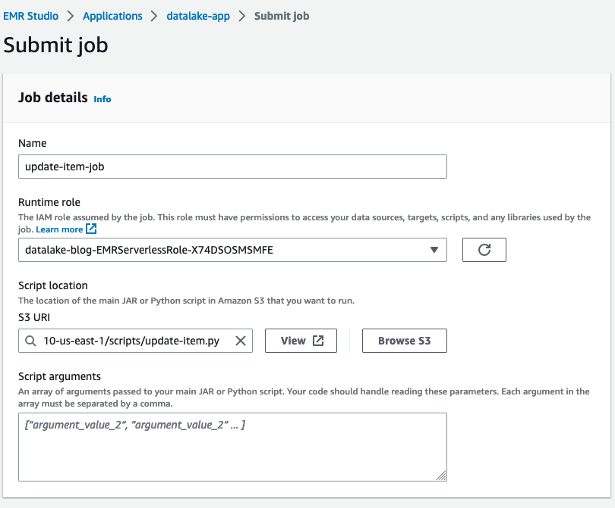
- Under Spark properties, choose Edit in text.
- Enter the following properties, replacing the <BUCKET-NAME> with your own
datalake-<####>-us-east-1:
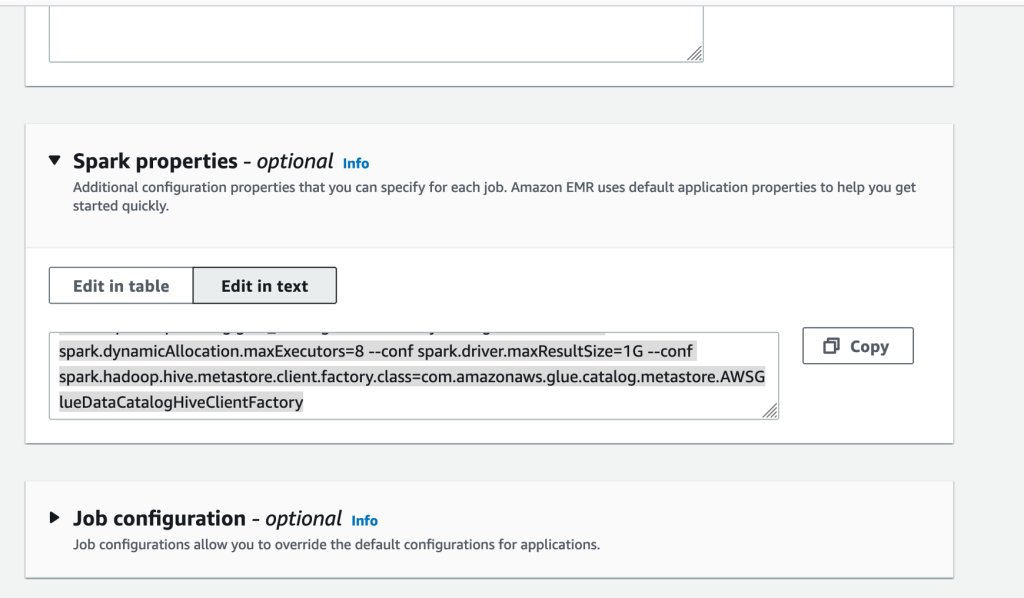
- Then submit the job.

- After the job finishes successfully, return to the Athena console and run the following query:
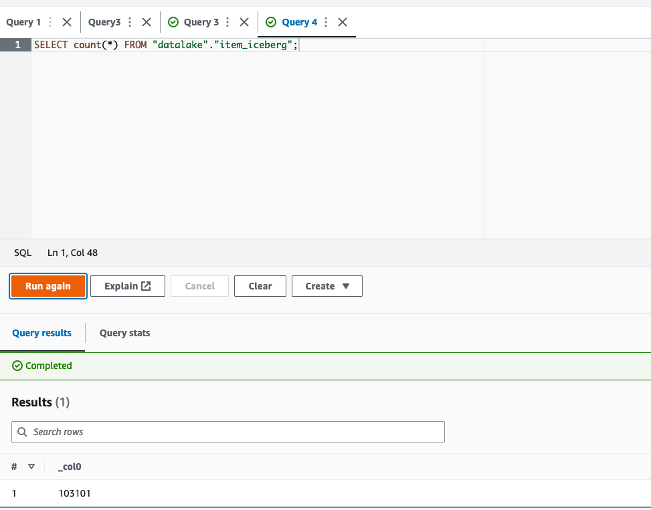
The returned result is 103,101 = 102,000 + (1,112 – 11). The batch was merged successfully.
Time travel
To run a time travel query, complete the following steps:
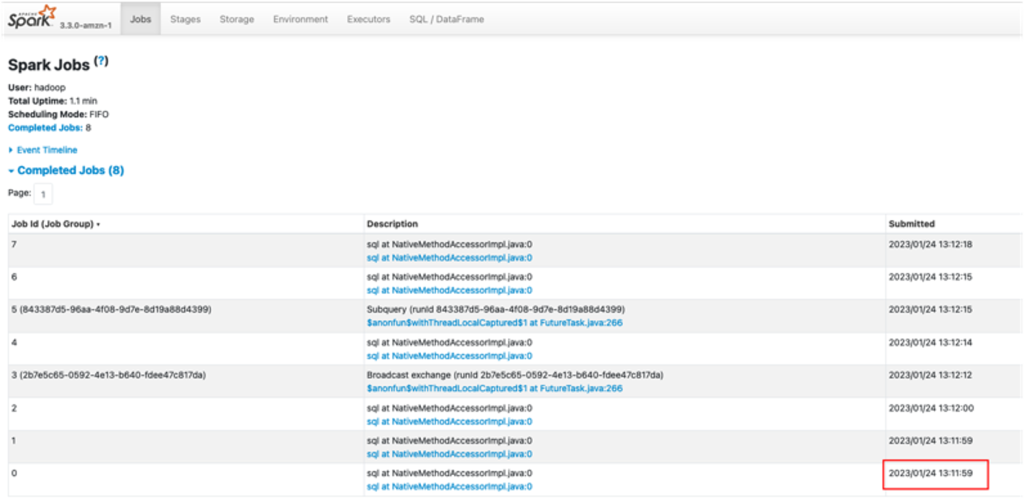
- Get the timestamp of the job run via the application details page on the EMR Serverless console, or the Spark UI on the History Server, as shown in the following screenshot.
This time could be just minutes before you ran the update Spark job.
- Convert the timestamp from the format
YYYY/MM/DD hh:mm:ss to YYYY-MM-DDThh:mm:ss.sTZDwith time zone. For example, from2023/02/20 14:40:41to2023-02-20 14:40:41.000 UTC. - On the Athena console, run the following query to count the
itemtable records at a time before the update job, replacing <TRAVEL_TIME> with your time:
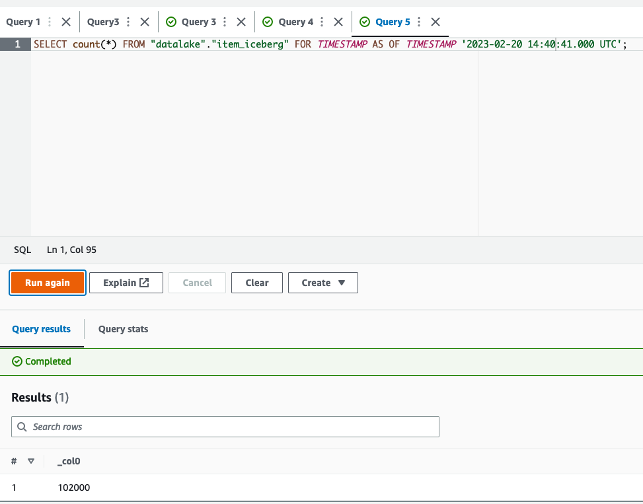
The query will give 102,000 as a result, the expected table size before running the update job.
- Now you can run a query with a timestamp after the successful run of the update job (for example,
2023-02-20 15:06:00.000 UTC):
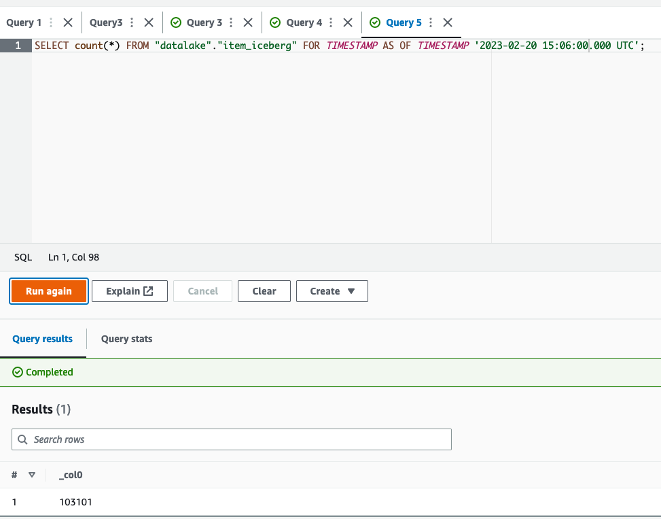
The query will now give 103,101 as the size of the table at that time, after the update job successfully finished.
Additionally, you can query in Athena based on the version ID of a snapshot in Iceberg. However, for more advanced use cases, such as to roll back to a given version or to find version IDs, you can use Iceberg’s SDK or Spark on Amazon EMR.
Clean up
Complete the following steps to clean up your resources:
- On the Amazon S3 console, empty your buckets.
- On the Athena console, delete the workgroup
DatalakeWorkgroup. - On the EMR Studio console, stop the application
datalake-app. - On the AWS CloudFormation console, delete the CloudFormation stack.
Conclusion
In this post, we created a serverless transactional data lake with Iceberg tables, EMR Serverless, and Athena. We used TPC-DS sales data with 10 GB data and more than 7 million records in the fact table. We demonstrated how straightforward it is to rely on SQL and Spark to run serverless jobs for data ingestion and upserts. Moreover, we showed how to run complex BI queries directly on Iceberg tables from Athena for reporting.
You can start building your serverless transactional data lake on AWS today, and dive deep into the features and optimizations Iceberg provides to build analytics applications more easily. Iceberg can also help you in the future to improve performance and reduce costs.
About the Author

Houssem is a Specialist Solutions Architect at AWS with a focus on analytics. He is passionate about data and emerging technologies in analytics. He holds a PhD on data management in the cloud. Prior to joining AWS, he worked on several big data projects and published several research papers in international conferences and venues.