AWS Big Data Blog
Category: Advanced (300)

Integrate Amazon Redshift native IdP federation with Microsoft Azure AD using a SQL client
June 2023: This post was reviewed and updated for accuracy. Amazon Redshift accelerates your time to insights with fast, easy, and secure cloud data warehousing at scale. Tens of thousands of customers rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries. The new Amazon Redshift native identity provider authentication simplifies […]

Integrate Amazon Redshift native IdP federation with Microsoft Azure AD and Power BI
June 2023: This post was reviewed and updated for accuracy. Amazon Redshift accelerates your time to insights with fast, easy, and secure cloud data warehousing at scale. Tens of thousands of customers rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries. As enterprise customers look to build their data warehouse […]

Introducing Protocol buffers (protobuf) schema support in AWS Glue Schema Registry
September 2025: This post was reviewed for accuracy. AWS Glue Schema Registry now supports Protocol buffers (protobuf) schemas in addition to JSON and Avro schemas. This allows application teams to use protobuf schemas to govern the evolution of streaming data and centrally control data quality from data streams to data lake. AWS Glue Schema Registry […]
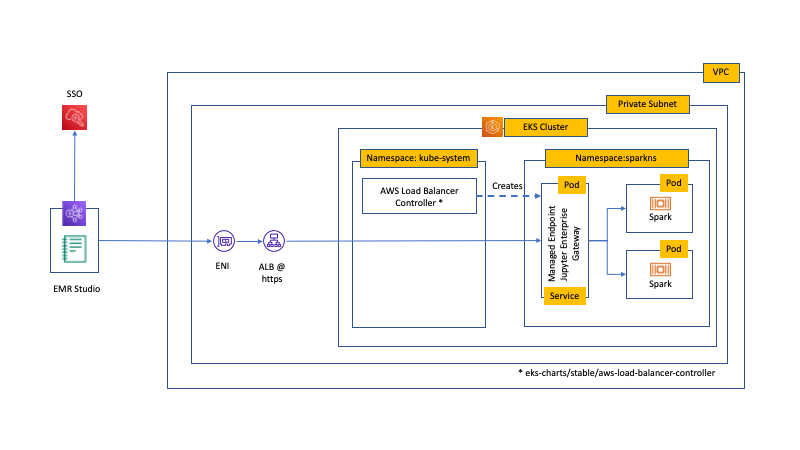
Configure Amazon EMR Studio and Amazon EKS to run notebooks with Amazon EMR on EKS
Amazon EMR on Amazon EKS provides a deployment option for Amazon EMR that allows you to run analytics workloads on Amazon Elastic Kubernetes Service (Amazon EKS). This is an attractive option because it allows you to run applications on a common pool of resources without having to provision infrastructure. In addition, you can use Amazon […]

Reduce costs and increase resource utilization of Apache Spark jobs on Kubernetes with Amazon EMR on Amazon EKS
Amazon EMR on Amazon EKS is a deployment option for Amazon EMR that allows you to run Apache Spark on Amazon Elastic Kubernetes Service (Amazon EKS). If you run open-source Apache Spark on Amazon EKS, you can now use Amazon EMR to automate provisioning and management, and run Apache Spark up to three times faster. […]

Run and debug Apache Spark applications on AWS with Amazon EMR on Amazon EKS
Customers today want to focus more on their core business model and less on the underlying infrastructure and operational burden. As customers migrate to the AWS Cloud, they’re realizing the benefits of being able to innovate faster on their own applications by relying on AWS to handle big data platforms, operations, and automation. Many of […]

Run a Spark SQL-based ETL pipeline with Amazon EMR on Amazon EKS
Increasingly, a business’s success depends on its agility in transforming data into actionable insights, which requires efficient and automated data processes. In the previous post – Build a SQL-based ETL pipeline with Apache Spark on Amazon EKS, we described a common productivity issue in a modern data architecture. To address the challenge, we demonstrated how to utilize a declarative approach as the key enabler to improve efficiency, which resulted in a faster time to value for businesses. Generally speaking, managing applications declaratively in Kubernetes is a widely adopted best practice. You can use the same approach to build and deploy Spark applications with open-source or in-house build frameworks to achieve the same productivity goal.
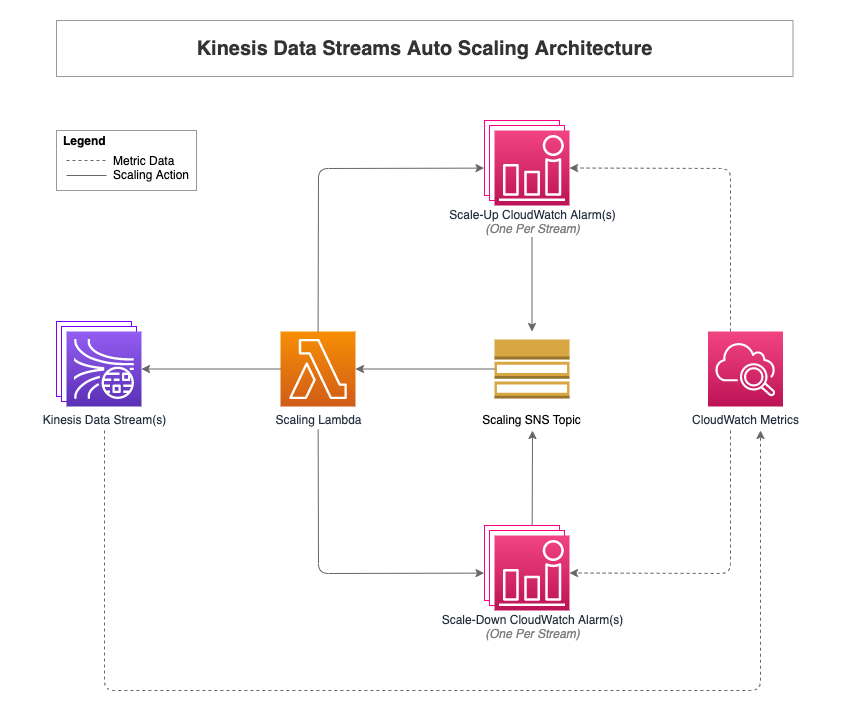
Auto scaling Amazon Kinesis Data Streams using Amazon CloudWatch and AWS Lambda
This post is co-written with Noah Mundahl, Director of Public Cloud Engineering at United Health Group. Update (03/09/2026): Amazon Kinesis Data Streams On-Demand Advantage mode is now the recommended way to natively auto scale your Amazon Kinesis Data Streams. In this post, we cover a solution to add auto scaling to Amazon Kinesis Data Streams. […]

Manage and process your big data workflows with Amazon MWAA and Amazon EMR on Amazon EKS
Many customers are gathering large amount of data, generated from different sources such as IoT devices, clickstream events from websites, and more. To efficiently extract insights from the data, you have to perform various transformations and apply different business logic on your data. These processes require complex workflow management to schedule jobs and manage dependencies […]
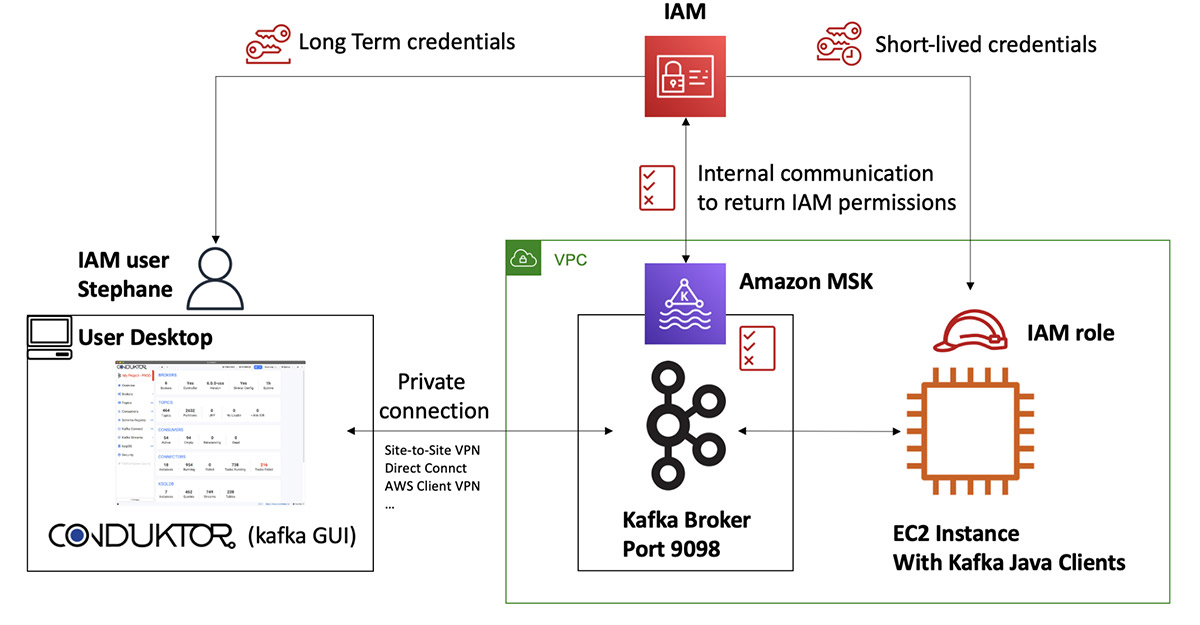
Securing Apache Kafka is easy and familiar with IAM Access Control for Amazon MSK
September 2025: This post was reviewed and updated for accuracy. AWS launched IAM Access Control for Amazon MSK, which is a security option offered at no additional cost that simplifies cluster authentication and Apache Kafka API authorization using AWS Identity and Access Management (IAM) roles or user policies to control access. This eliminates the need […]