AWS Big Data Blog
Category: Amazon CloudWatch

Set up production-ready monitoring for Amazon MSK using CloudWatch alarms
In this post, I show you how to implement effective monitoring for your Kafka clusters using Amazon MSK and Amazon CloudWatch. You’ll learn how to track critical metrics like broker health, resource utilization, and consumer lag, and set up automated alerts to prevent operational issues.

Best practices for right-sizing Amazon OpenSearch Service domains
In this post, we guide you through the steps to determine if your OpenSearch Service domain is right-sized, using AWS tools and best practices to optimize your configuration for workloads like log analytics, search, vector search, or synthetic data testing.

Amazon OpenSearch Ingestion 101: Set CloudWatch alarms for key metrics
This post provides an in-depth look at setting up Amazon CloudWatch alarms for OpenSearch Ingestion pipelines. It goes beyond our recommended alarms to help identify bottlenecks in the pipeline, whether that’s in the sink, the OpenSearch clusters data is being sent to, the processors, or the pipeline not pulling or accepting enough from the source. This post will help you proactively monitor and troubleshoot your OpenSearch Ingestion pipelines.
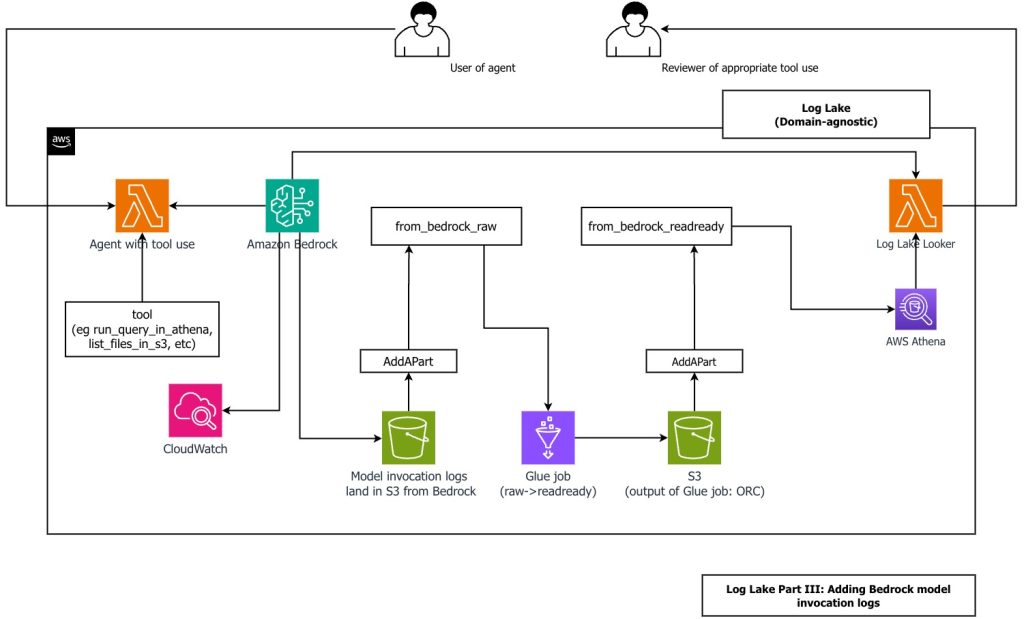
Create a customizable cross-company log lake, Part II: Build and add Amazon Bedrock
In this post, you learn how to build Log Lake, a customizable cross-company data lake for compliance-related use cases that combines AWS CloudTrail and Amazon CloudWatch logs. You’ll discover how to set up separate tables for writing and reading, implement event-driven partition management using AWS Lambda, and transform raw JSON files into read-optimized Apache ORC format using AWS Glue jobs. Additionally, you’ll see how to extend Log Lake by adding Amazon Bedrock model invocation logs to enable human review of agent actions with elevated permissions, and how to use an AI agent to query your log data without writing SQL.

Amazon OpenSearch Serverless monitoring: A CloudWatch setup guide
In this post, we explore commonly used Amazon CloudWatch metrics and alarms for OpenSearch Serverless, walking through the process of selecting relevant metrics, setting appropriate thresholds, and configuring alerts. This guide will provide you with a comprehensive monitoring strategy that complements the serverless nature of your OpenSearch deployment while maintaining full operational visibility.

Automate and orchestrate Amazon EMR jobs using AWS Step Functions and Amazon EventBridge
In this post, we discuss how to build a fully automated, scheduled Spark processing pipeline using Amazon EMR on EC2, orchestrated with Step Functions and triggered by EventBridge. We walk through how to deploy this solution using AWS CloudFormation, processes COVID-19 public dataset data in Amazon Simple Storage Service (Amazon S3), and store the aggregated results in Amazon S3.

Amazon EMR Serverless observability, Part 1: Monitor Amazon EMR Serverless workers in near real time using Amazon CloudWatch
We have launched job worker metrics in Amazon CloudWatch for EMR Serverless. This feature allows you to monitor vCPUs, memory, ephemeral storage, and disk I/O allocation and usage metrics at an aggregate worker level for your Spark and Hive jobs. This post is part of a series about EMR Serverless observability. In this post, we discuss how to use these CloudWatch metrics to monitor EMR Serverless workers in near real time.

Create a customizable cross-company log lake for compliance, Part I: Business Background
As builders, sometimes you want to dissect a customer experience, find problems, and figure out ways to make it better. That means going a layer down to mix and match primitives together to get more comprehensive features and more customization, flexibility, and freedom. In this post, we introduce Log Lake, a do-it-yourself data lake based on logs from CloudWatch and AWS CloudTrail.

Deliver Amazon CloudWatch logs to Amazon OpenSearch Serverless
In this blog post, we will show how to use Amazon OpenSearch Ingestion to deliver CloudWatch logs to OpenSearch Serverless in near real-time. We outline a mechanism to connect a Lambda subscription filter with OpenSearch Ingestion and deliver logs to OpenSearch Serverless without explicitly needing a separate subscription filter for it.

Disaster recovery strategies for Amazon MWAA – Part 1
In the dynamic world of cloud computing, ensuring the resilience and availability of critical applications is paramount. Disaster recovery (DR) is the process by which an organization anticipates and addresses technology-related disasters. For organizations implementing critical workload orchestration using Amazon Managed Workflows for Apache Airflow (Amazon MWAA), it is crucial to have a DR plan […]