AWS Big Data Blog
Category: Best Practices

Power enterprise-grade Data Vaults with Amazon Redshift – Part 1
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x better price-performance than other cloud data warehouses. As with all AWS […]
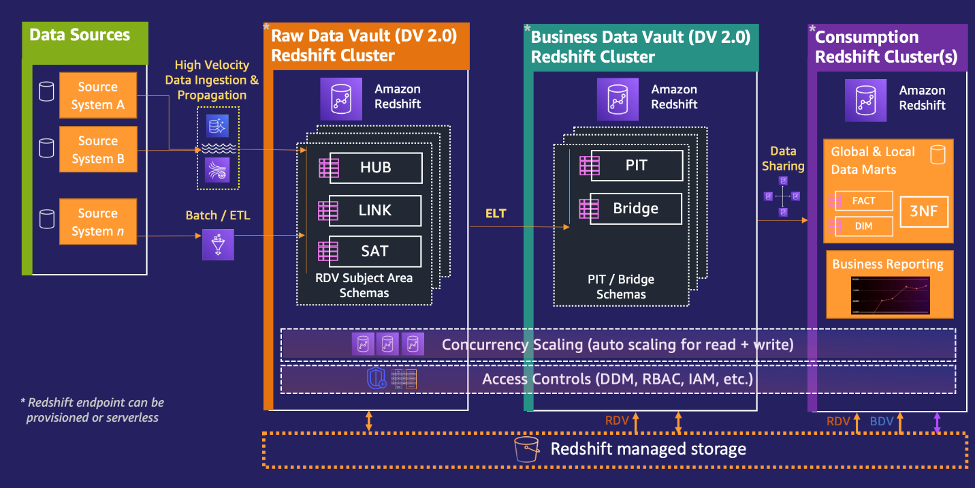
Power enterprise-grade Data Vaults with Amazon Redshift – Part 2
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x better price-performance than any other cloud data warehouses. As with all […]
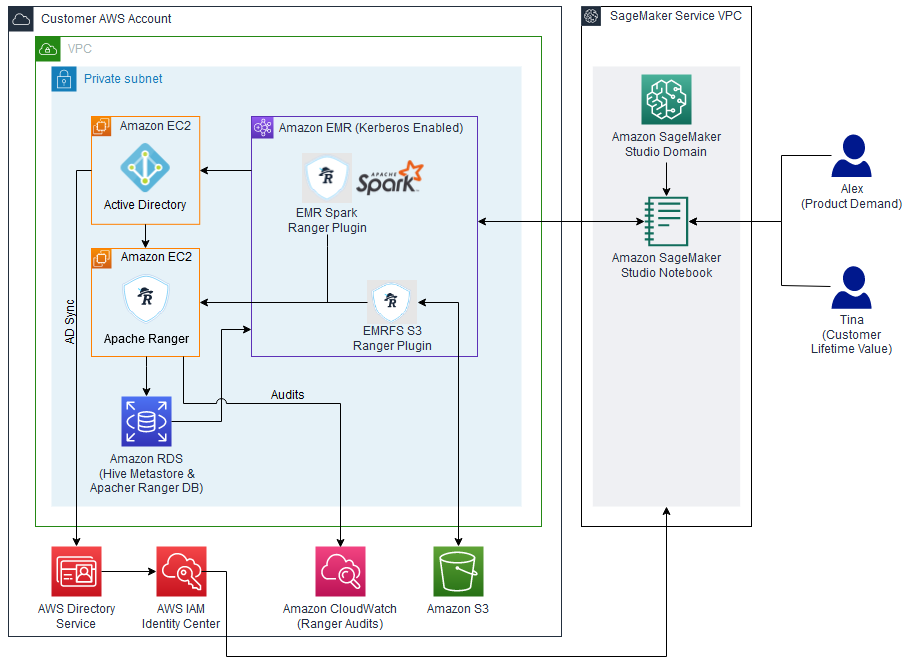
Implement fine-grained access control in Amazon SageMaker Studio and Amazon EMR using Apache Ranger and Microsoft Active Directory
In this post, we show how you can authenticate into SageMaker Studio using an existing Active Directory (AD), with authorized access to both Amazon S3 and Hive cataloged data using AD entitlements via Apache Ranger integration and AWS IAM Identity Center (successor to AWS Single Sign-On). With this solution, you can manage access to multiple SageMaker environments and SageMaker Studio notebooks using a single set of credentials. Subsequently, Apache Spark jobs created from SageMaker Studio notebooks will access only the data and resources permitted by Apache Ranger policies attached to the AD credentials, inclusive of table and column-level access.

GoDaddy benchmarking results in up to 24% better price-performance for their Spark workloads with AWS Graviton2 on Amazon EMR Serverless
This is a guest post co-written with Mukul Sharma, Software Development Engineer, and Ozcan IIikhan, Director of Engineering from GoDaddy. GoDaddy empowers everyday entrepreneurs by providing all the help and tools to succeed online. With more than 20 million customers worldwide, GoDaddy is the place people come to name their ideas, build a professional website, […]

Enable cost-efficient operational analytics with Amazon OpenSearch Ingestion
As the scale and complexity of microservices and distributed applications continues to expand, customers are seeking guidance for building cost-efficient infrastructure supporting operational analytics use cases. Operational analytics is a popular use case with Amazon OpenSearch Service. A few of the defining characteristics of these use cases are ingesting a high volume of time series […]

Accelerate your data warehouse migration to Amazon Redshift – Part 7
In this post, we describe at a high-level how CDC tasks work in AWS SCT. Then we deep dive into an example of how to configure, start, and manage a CDC migration task. We look briefly at performance and how you can tune a CDC migration, and then conclude with some information about how you can get started on your own migration.

Processing large records with Amazon Kinesis Data Streams
In this post, we show you some different options for handling large records within Kinesis Data Streams and the benefits and disadvantages of each approach. We provide some sample code for each option to help you get started with any of these approaches with your own workloads.

Modernize a legacy real-time analytics application with Amazon Managed Service for Apache Flink
In this post, we discuss challenges with relational databases when used for real-time analytics and ways to mitigate them by modernizing the architecture with serverless AWS solutions. We introduce you to Amazon Managed Service for Apache Flink Studio and get started querying streaming data interactively using Amazon Kinesis Data Streams. We walk through a call center analytics solution that provides insights into the call center’s performance in near-real time through metrics that determine agent efficiency in handling calls in the queue. Key performance indicators (KPIs) of interest for a call center from a near-real-time platform could be calls waiting in the queue, highlighted in a performance dashboard within a few seconds of data ingestion from call center streams.

Define per-team resource limits for big data workloads using Amazon EMR Serverless
Customers face a challenge when distributing cloud resources between different teams running workloads such as development, testing, or production. The resource distribution challenge also occurs when you have different line-of-business users. The objective is not only to ensure sufficient resources be consistently available to production workloads and critical teams, but also to prevent adhoc jobs […]

Apache Iceberg optimization: Solving the small files problem in Amazon EMR
Currently, Iceberg provides a compaction utility that compacts small files at a table or partition level. But this approach requires you to implement the compaction job using your preferred job scheduler or manually triggering the compaction job. In this post, we discuss the new Iceberg feature that you can use to automatically compact small files while writing data into Iceberg tables using Spark on Amazon EMR or Amazon Athena.