AWS Big Data Blog
Category: *Post Types

Integral Ad Science secures self-service data lake using AWS Lake Formation
This post is co-written with Mat Sharpe, Technical Lead, AWS & Systems Engineering from Integral Ad Science. Integral Ad Science (IAS) is a global leader in digital media quality. The company’s mission is to be the global benchmark for trust and transparency in digital media quality for the world’s leading brands, publishers, and platforms. IAS […]

How Rapid7 built multi-tenant analytics with Amazon Redshift using near-real-time datasets
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. This is a guest post co-written by Rahul Monga, Principal Software Engineer at Rapid7. Rapid7 InsightVM is a vulnerability assessment and management product that provides visibility into the risks present across an […]

How MOIA built a fully automated GDPR compliant data lake using AWS Lake Formation, AWS Glue, and AWS CodePipeline
This is a guest blog post co-written by Leonardo Pêpe, a Data Engineer at MOIA. MOIA is an independent company of the Volkswagen Group with locations in Berlin and Hamburg, and operates its own ride pooling services in Hamburg and Hanover. The company was founded in 2016 and develops mobility services independently or in partnership […]

Create a custom Amazon S3 Storage Lens metrics dashboard using Amazon QuickSight
Companies use Amazon Simple Storage Service (Amazon S3) for its flexibility, durability, scalability, and ability to perform many things besides storing data. This has led to an exponential rise in the usage of S3 buckets across numerous AWS Regions, across tens or even hundreds of AWS accounts. To optimize costs and analyze security posture, Amazon […]

How Magellan Rx Management used Amazon Redshift ML to predict drug therapeutic conditions
This post is co-written with Karim Prasla and Deepti Bhanti from Magellan Rx Management as the lead authors. Amazon Redshift ML makes it easy for data scientists, data analysts, and database developers to create, train, and use machine learning (ML) models using familiar SQL commands in Amazon Redshift data warehouses. The ML feature can be […]

How Comcast uses AWS to rapidly store and analyze large-scale telemetry data
This blog post is co-written by Russell Harlin from Comcast Corporation. Comcast Corporation creates incredible technology and entertainment that connects millions of people to the moments and experiences that matter most. At the core of this is Comcast’s high-speed data network, providing tens of millions of customers across the country with reliable internet connectivity. This […]

How GE Healthcare modernized their data platform using a Lake House Architecture
GE Healthcare (GEHC) operates as a subsidiary of General Electric. The company is headquartered in the US and serves customers in over 160 countries. As a leading global medical technology, diagnostics, and digital solutions innovator, GE Healthcare enables clinicians to make faster, more informed decisions through intelligent devices, data analytics, applications, and services, supported by […]

Synchronize and control your Amazon Redshift clusters maintenance windows
Amazon Redshift is a data warehouse that can expand to exabyte-scale. Today, tens of thousands of AWS customers (including NTT DOCOMO, Finra, and Johnson & Johnson) use Amazon Redshift to run mission-critical business intelligence dashboards, analyze real-time streaming data, and run predictive analytics jobs. Amazon Redshift powers analytical workloads for Fortune 500 companies, startups, and […]

How Takeda uses the GraphQL API with AWS AppSync to support data scientists
This is a guest blog post by Michael Song and Rajesh Mikkilineni at Takeda. In their own words, “Takeda is a global, values-based, R&D-driven biopharmaceutical leader committed to discover and deliver life-transforming treatments, guided by our commitment to patients, our people and the planet. Takeda’s R&D data engineering team aspires to build a robust and […]
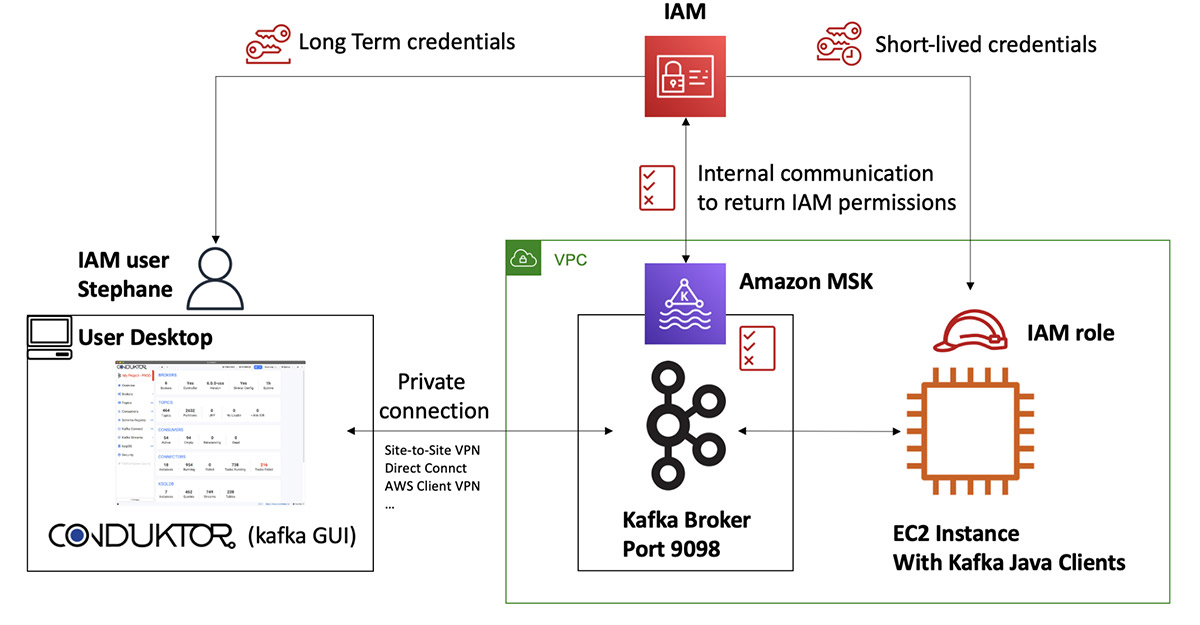
Securing Apache Kafka is easy and familiar with IAM Access Control for Amazon MSK
September 2025: This post was reviewed and updated for accuracy. AWS launched IAM Access Control for Amazon MSK, which is a security option offered at no additional cost that simplifies cluster authentication and Apache Kafka API authorization using AWS Identity and Access Management (IAM) roles or user policies to control access. This eliminates the need […]