AWS Big Data Blog
How Magellan Rx Management used Amazon Redshift ML to predict drug therapeutic conditions
This post is co-written with Karim Prasla and Deepti Bhanti from Magellan Rx Management as the lead authors.
Amazon Redshift ML makes it easy for data scientists, data analysts, and database developers to create, train, and use machine learning (ML) models using familiar SQL commands in Amazon Redshift data warehouses. The ML feature can be used by various personas; in this post we discuss how data analysts at Magellan Rx Management used Redshift ML to predict and classify drugs into various therapeutic conditions.
About Magellan Rx Management
Magellan Rx Management, a division of Magellan Health, Inc., is shaping the future of pharmacy. As a next-generation pharmacy organization, we deliver meaningful solutions to the people we serve. As pioneers in specialty drug management, industry leaders in Medicaid pharmacy programs, and disruptors in pharmacy benefit management, we partner with our customers and members to deliver a best-in-class healthcare experience.
Use case
Magellan Rx Management uses data and analytics to deliver clinical solutions that improve patient care, contain costs, and improve outcomes. We utilize predictive analytics to forecast future drugs costs, identify drugs that will drive future trends, including pipeline medications, and proactively identify patients at risk for becoming non-adherent to their medications.
We develop and deliver these analytics via our MRx Predict solution. This solution utilizes a variety of data, including pharmacy and medical claims, compendia information, census data, and many other sources to optimize the predictive model development, deployment, and most importantly maximize predictive accuracy.
Part of the process involves stratification of drugs and patient population based on therapeutic conditions. These conditions are derived by utilizing compendia drug attributes to come up with a classification system focused on disease categories, such as diabetes, hypertension, spinal muscular atrophy, and many others, and ensuring drugs are appropriately categorized as opposed to being included in the “miscellaneous” bucket, which is the case for many specialty medications. Also, this broader approach to classifying drugs, beyond just mechanism of action, has allowed us to effectively develop downstream reporting solutions, patient segmentation, and outcomes analytics.
Although we use different technologies for predictive analytics, we wanted to use Redshift ML to predict appropriate drug therapeutic conditions, because it would allow us to use this functionality within our Amazon Redshift data warehouse by making the predictions using standard SQL programming. Prior to Redshift ML, we had data analysts and clinicians manually categorize any new drugs into the appropriate therapeutic conditions. The end goal of using Redshift ML was to assess how well we could improve our operational efficiency while maintaining a high level of clinical accuracy.
Redshift ML allowed us to create models using standard SQL without having to use external systems, technologies, or APIs. With data already in Amazon Redshift, our data scientists and analysts, who are skilled in SQL, seamlessly created ML models to effectively predict therapeutic conditions for individual drugs.
“At Magellan Rx Management, we leverage data, analytics, and proactive insights, to help solve complex pharmacy challenges, while focusing on improving clinical and economic outcomes for customers and members,” said Karim Prasla, Vice President of Clinical Outcomes Advanced Analytics and Research at Magellan Rx Management.“We use predictive analytics and machine learning to improve operational and clinical efficiencies and effectiveness. With Redshift ML, we were able to enable our data and outcomes analysts to classify new drugs to market into appropriate therapeutic conditions by creating and utilizing ML models with minimal effort. The efficiency gained through leveraging Redshift ML to support this process improved our productivity and optimized our resources while generating a high degree of predictive accuracy.”
Magellan Rx Management continues to focus on using data analytics to identify opportunities to improve patient care and outcomes, to deliver proactive insights to our customers so sound data-driven decisions can be made, and end-user tools to allow customers and support staff to have readily available insights. By incorporating predictive analytics along with providing descriptive and diagnostic insights, we at Magellan Rx Management are able to partner with our customers to ensure we evaluate the “what,” the “why,” and the “what will” to more effectively manage the pharmacy programs.
Key benefits of using Redshift ML
Redshift ML enables you to train models with a single SQL CREATE MODEL command. The CREATE MODEL command creates a model that Amazon Redshift uses to generate model-based predictions with familiar SQL constructs.
Redshift ML provides simple, optimized, and secure integration between Amazon Redshift and Amazon SageMaker, and enables inference within the Amazon Redshift cluster, making it easy to use predictions generated by ML-based models in queries and applications. An analyst with SQL skills can easily create and train models with no expertise in ML programming languages, algorithms, and APIs.
With Redshift ML, you don’t have to perform any of the undifferentiated heavy lifting required for integrating with an external ML service. Redshift ML saves you the time to format and move data, manage permission controls, or build custom integrations, workflows, and scripts. You can easily use popular ML algorithms and simplify training needs that require frequent iteration from training to prediction. Amazon Redshift automatically discovers the best algorithm and tunes the best model for your problem. You can simply make predictions and predictive analytics from within your Amazon Redshift cluster without the need to move data out of Amazon Redshift.

Simplifying integration between Amazon Redshift and SageMaker
Before Redshift ML, a data scientist had to go through a series of steps with various tools to arrive at a prediction—identify the appropriate ML algorithms in SageMaker or use Amazon SageMaker Autopilot, export the data from the data warehouse, and prepare the training data to work with these models. When the model is deployed, the scientist goes through various iterations with new data for making predictions (also known as inference). This involves moving data back and forth between Amazon Redshift and SageMaker through a series of manual steps:
- Export training data to Amazon Simple Storage Service (Amazon S3).
- Train the model in SageMaker.
- Export prediction input data to Amazon S3.
- Generate predictions in SageMaker.
- Import targets back into the database.
The following diagram depicts these steps.

This iterative process is time-consuming and prone to errors, and automating the data movement can take weeks or months of custom coding that then needs to be maintained.
Redshift ML enables you to use ML with your data in Amazon Redshift without this complexity. Without movement of data, you don’t have any overhead of additional security and governance of data that you export from your data warehouse.
Prerequisites
To take advantage of Redshift ML, you need an Amazon Redshift cluster with the ML feature enabled.
The cluster needs to have an AWS Identity and Access Management (IAM) role attached with sufficient privileges on Amazon S3 and SageMaker. For more information on setup and an introduction to Redshift ML, see Create, train, and deploy machine learning models in Amazon Redshift using SQL with Amazon Redshift ML. The IAM role is required for Amazon Redshift to interact with SageMaker and Amazon S3. An S3 bucket is also required to export the training dataset and store other ML-related intermediate artifacts.
Setup and data preparation
We use a sample dataset for this use case; the last column mrx_therapeutic_condition is the one we’re going to predict using the multi-classification model. We ingest this health care drug dataset into the Amazon Redshift cluster, and use it to train and test the model.
To get randomness in the training dataset, we used a random record number column (record_nbr), which can be used to separate the training dataset from testing. If your dataset already has a unique or primary key column, you can use it as a predicate to separate the training from testing dataset. The random factor (record_nbr) column was added to this dataset to serve as a WHERE clause predicate to the SELECT statement in the CREATE MODEL command (discussed later in this post). A classic example is if your prediction column is True or False, then you want to make sure that the training dataset has balanced values of both and not just True or False alone. You can achieve this by using a neutral column as a predicate, which in our case is record_nbr. After loading the data, we validated to ensure all column values are uniformly distributed for training the model. A very important factor for getting better accuracy in predictions is to use a balanced dataset for training in which the distribution of all the values is balanced and covers all characteristics.
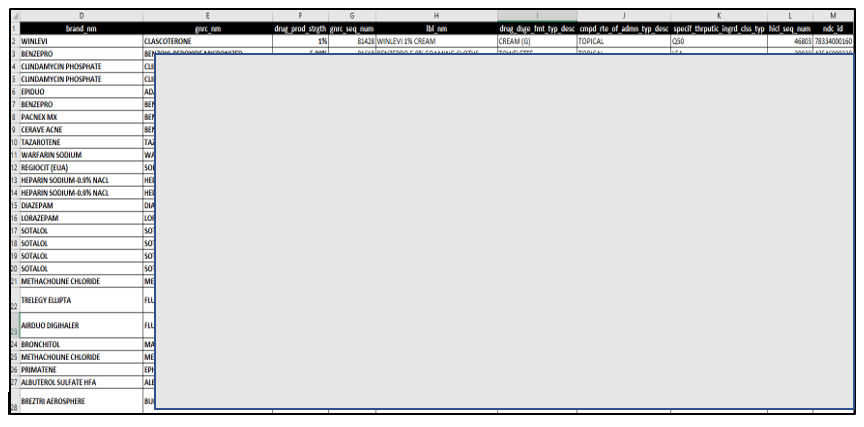
In this example, we have kept the entire data in single table but used the WHERE predicate on the record_nbr column to differentiate the training and testing datasets.
The following is the DDL and COPY commands for this use case.
- Sign in to Amazon Redshift using the query editor or your preferred SQL client (DBeaver, DBVisualizer, SQL WorkbenchJ) to run the SQL statements to create the database tables.
- Create the schema and tables using the following DDL statements:
- Use the COPY commands to prepare and load data for model training:
Create model
Now that the data setup part is done, let’s create the model in Redshift ML. Then CREATE MODEL runs in the background and you can track progress using SHOW MODEL model_name;.
For a data analyst who is not quite conversant with machine learning, the CREATE MODEL statement is a powerhouse that offers flexibility in the number of options used to create the model. In our current use case, we haven’t passed the model type as a multi-classification model or any other options but based on the input data. The Redshift ML CREATE MODEL statement can select the correct problem type and other associated parameters using Autopilot. Multi-class classification is a problem type that predicts one of many outcomes, such as predicting a rating a customer might give for a product. In our example, we predict therapeutic conditions such as acne, anti-clotting therapy, asthma, or COPD for different patients. Data scientists and ML experts can use it to perform supervised learning to tackle problems ranging from forecasting, personalization, or customer churn prediction. See the following code:
The target (label) in the preceding code is the mrx_therapeutic_condition column, which is used for prediction, and the function that is created out of this CREATE MODEL command is named predict_drug_therapeutic_condition.
The training data comes from the table ml_drug_data, and Autopilot automatically detects the multi-classification value model type based on input data.
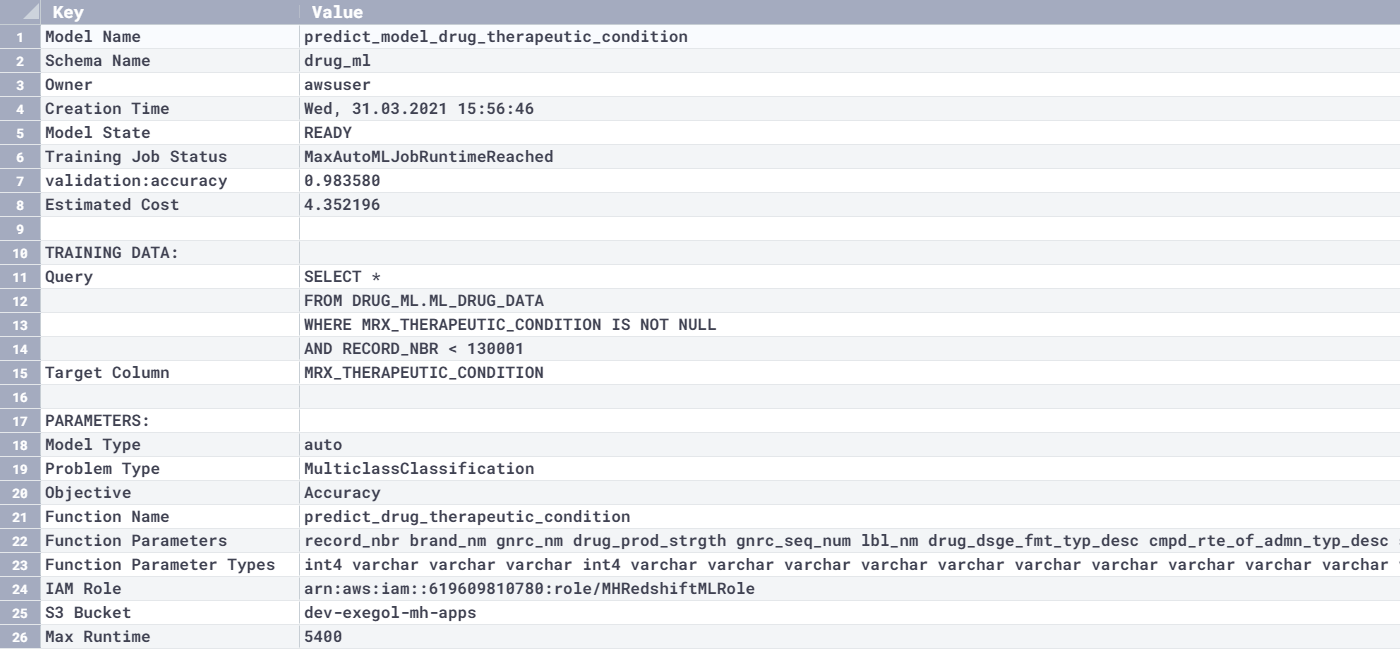
Show model
The command show model model_name; is used to track the progress and also to get more details about a model (see the following example code). This section contains a representative output from SHOW MODEL after CREATE MODEL is complete. It has the inputs used in the CREATE MODEL statement with more information like model state (TRAINING, READY, FAILED) and the maximum estimated runtime it will take to finish. For better accuracy for predictions, we recommend letting the model finish to completion by increasing the default timeout value (the default is actually short for better accuracy). There is also an option to use CREATE MODEL, which lets the user limit the maximum runtime to a lower number, but the more runtime you have for CREATE MODEL, more it gets to train and iterate using multiple options before settling in on the best model.
The following table shows our results.
Inference
For binary and multi-class classification problems, we compute the accuracy as the model metric. We use the following formula to determine the accuracy:
We use the newly created function predict_drug_therapeutic_condition for the prediction and use the columns other than the target (label) as the input:
The inference query output (0.9923 *100 = 99.23 %) matches the output from the show model command.
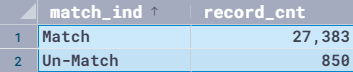
Let’s run the prediction query on therapeutic condition to get the count of original vs. ML-predicted values for accuracy comparison:
The following table shows our output.
Conclusion
Redshift ML allows us to develop greater efficiency and enhanced ability to generate MRx therapeutic conditions, especially when new drugs come to market. Redshift ML provides an easy and seamless platform for database users to create, train, and tune models using a SQL interface. ML capabilities empower Amazon Redshift users to create models and deploy them locally on large datasets, which was an arduous task before. Different user personas, from data analysts to advanced data science and ML experts, can take advantage of Redshift ML for machine learning based predictions and gain valuable business insights.
About the Authors
 Karim Prasla, Pharm D, MS, BCPS, is a clinician and a health economist focused on optimizing use of data, analytics, and insights to improve patient care and drive positive clinical and economic outcomes. Karim leads a talented team of clinicians, economists, health outcomes scientists, and data analysts at Magellan Rx Management who are passionate about leveraging data analytics to develop products and solutions that provide proactive insights to deliver value to clinicians, customers, and members.
Karim Prasla, Pharm D, MS, BCPS, is a clinician and a health economist focused on optimizing use of data, analytics, and insights to improve patient care and drive positive clinical and economic outcomes. Karim leads a talented team of clinicians, economists, health outcomes scientists, and data analysts at Magellan Rx Management who are passionate about leveraging data analytics to develop products and solutions that provide proactive insights to deliver value to clinicians, customers, and members.
 Deepti Bhanti, PhD, is an IT leader at Magellan Rx Management with a focus on delivering big data solutions to meet the data and analytics needs for our customers. Deepti leads a full stack team of IT engineers who are passionate about architecting and building scalable solutions while driving business value and market differentiation through technological innovations.
Deepti Bhanti, PhD, is an IT leader at Magellan Rx Management with a focus on delivering big data solutions to meet the data and analytics needs for our customers. Deepti leads a full stack team of IT engineers who are passionate about architecting and building scalable solutions while driving business value and market differentiation through technological innovations.
 Srinivasulu Ponnada is a Sr. Data Architect at AWS, with a passion for data warehouse development and big data solutions. Srini worked with Magellan Rx Management business users to help architect, build, and scale applications to achieve their business goals.
Srinivasulu Ponnada is a Sr. Data Architect at AWS, with a passion for data warehouse development and big data solutions. Srini worked with Magellan Rx Management business users to help architect, build, and scale applications to achieve their business goals.
 Rajesh Francis is a Sr. Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and works with customers to build scalable analytic solutions. Rajesh worked with Magellan Rx Management to help implement a lake house architecture and leverage Redshift ML for various use cases.
Rajesh Francis is a Sr. Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and works with customers to build scalable analytic solutions. Rajesh worked with Magellan Rx Management to help implement a lake house architecture and leverage Redshift ML for various use cases.
 Satish Sathiya is a Senior Product Engineer at Amazon Redshift. He is an avid big data enthusiast who collaborates with customers around the globe to achieve success and meet their data warehousing and data lake architecture needs. Satish worked with Magellan Rx Management to help jump start ML adoption.
Satish Sathiya is a Senior Product Engineer at Amazon Redshift. He is an avid big data enthusiast who collaborates with customers around the globe to achieve success and meet their data warehousing and data lake architecture needs. Satish worked with Magellan Rx Management to help jump start ML adoption.
 Debu Panda, a principal product manager at AWS, is an industry leader in analytics, application platform, and database technologies and has more than 25 years of experience in the IT world. He was responsible for driving the Amazon Redshift ML feature and working closely with Magellan Rx Management and other customers to incorporate their feedback into the service.
Debu Panda, a principal product manager at AWS, is an industry leader in analytics, application platform, and database technologies and has more than 25 years of experience in the IT world. He was responsible for driving the Amazon Redshift ML feature and working closely with Magellan Rx Management and other customers to incorporate their feedback into the service.