AWS Big Data Blog
Get started with data integration from Amazon S3 to Amazon Redshift using AWS Glue interactive sessions
Organizations are placing a high priority on data integration, especially to support analytics, machine learning (ML), business intelligence (BI), and application development initiatives. Data is growing exponentially and is generated by increasingly diverse data sources. Data integration becomes challenging when processing data at scale and the inherent heavy lifting associated with infrastructure required to manage it. This is one of the key reasons why organizations are constantly looking for easy-to-use and low maintenance data integration solutions to move data from one location to another or to consolidate their business data from several sources into a centralized location to make strategic business decisions.
Most organizations use Spark for their big data processing needs. If you’re looking to simplify data integration, and don’t want the hassle of spinning up servers, managing resources, or setting up Spark clusters, we have the solution for you.
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. AWS Glue provides both visual and code-based interfaces to make data integration simple and accessible for everyone.
If you prefer a code-based experience and want to interactively author data integration jobs, we recommend interactive sessions. Interactive sessions is a recently launched AWS Glue feature that allows you to interactively develop AWS Glue processes, run and test each step, and view the results.
There are different options to use interactive sessions. You can create and work with interactive sessions through the AWS Command Line Interface (AWS CLI) and API. You can also use Jupyter-compatible notebooks to visually author and test your notebook scripts. Interactive sessions provide a Jupyter kernel that integrates almost anywhere that Jupyter does, including integrating with IDEs such as PyCharm, IntelliJ, and Visual Studio Code. This enables you to author code in your local environment and run it seamlessly on the interactive session backend. You can also start a notebook through AWS Glue Studio; all the configuration steps are done for you so that you can explore your data and start developing your job script after only a few seconds. When the code is ready, you can configure, schedule, and monitor job notebooks as AWS Glue jobs.
If you haven’t tried AWS Glue interactive sessions before, this post is highly recommended. We work through a simple scenario where you might need to incrementally load data from Amazon Simple Storage Service (Amazon S3) into Amazon Redshift or transform and enrich your data before loading into Amazon Redshift. In this post, we use interactive sessions within an AWS Glue Studio notebook to load the NYC Taxi dataset into an Amazon Redshift Serverless cluster, query the loaded dataset, save our Jupyter notebook as a job, and schedule it to run using a cron expression. Let’s get started.
Solution overview
We walk you through the following steps:
- Set up an AWS Glue Jupyter notebook with interactive sessions.
- Use notebook’s magics, including AWS Glue connection and bookmarks.
- Read data from Amazon S3, and transform and load it into Redshift Serverless.
- Save the notebook as an AWS Glue job and schedule it to run.
Prerequisites
For this walkthrough, we must complete the following prerequisites:
- Upload Yellow Taxi Trip Records data and the taxi zone lookup table datasets into Amazon S3. Steps to do that are listed in the next section.
- Prepare the necessary AWS Identity and Access Management (IAM) policies and roles to work with AWS Glue Studio Jupyter notebooks, interactive sessions, and AWS Glue.
- Create the AWS Glue connection for Redshift Serverless.
Upload datasets into Amazon S3
Download Yellow Taxi Trip Records data and taxi zone lookup table data to your local environment. For this post, we download the January 2022 data for yellow taxi trip records data in Parquet format. The taxi zone lookup data is in CSV format. You can also download the data dictionary for the trip record dataset.
- On the Amazon S3 console, create a bucket called
my-first-aws-glue-is-project-<random number>in theus-east-1Region to store the data.S3 bucket names must be unique across all AWS accounts in all the Regions. - Create folders
nyc_yellow_taxiandtaxi_zone_lookupin the bucket you just created and upload the files you downloaded.
Your folder structures should look like the following screenshots.

Prepare IAM policies and role
Let’s prepare the necessary IAM policies and role to work with AWS Glue Studio Jupyter notebooks and interactive sessions. To get started with notebooks in AWS Glue Studio, refer to Getting started with notebooks in AWS Glue Studio.
Create IAM policies for the AWS Glue notebook role
Create the policy AWSGlueInteractiveSessionPassRolePolicy with the following permissions:
This policy allows the AWS Glue notebook role to pass to interactive sessions so that the same role can be used in both places. Note that AWSGlueServiceRole-GlueIS is the role that we create for the AWS Glue Studio Jupyter notebook in a later step. Next, create the policy AmazonS3Access-MyFirstGlueISProject with the following permissions:
This policy allows the AWS Glue notebook role to access data in the S3 bucket.
Create an IAM role for the AWS Glue notebook
Create a new AWS Glue role called AWSGlueServiceRole-GlueIS with the following policies attached to it:
- AWSGlueServiceRole
- AwsGlueSessionUserRestrictedNotebookPolicy
- AWSGlueInteractiveSessionPassRolePolicy
- AmazonS3Access-MyFirstGlueISProject
Create the AWS Glue connection for Redshift Serverless
Now we’re ready to configure a Redshift Serverless security group to connect with AWS Glue components.
- On the Redshift Serverless console, open the workgroup you’re using.
You can find all the namespaces and workgroups on the Redshift Serverless dashboard. - Under Data access, choose Network and security.
- Choose the link for the Redshift Serverless VPC security group.
 You’re redirected to the Amazon Elastic Compute Cloud (Amazon EC2) console.
You’re redirected to the Amazon Elastic Compute Cloud (Amazon EC2) console. - In the Redshift Serverless security group details, under Inbound rules, choose Edit inbound rules.
- Add a self-referencing rule to allow AWS Glue components to communicate:
- For Type, choose All TCP.
- For Protocol, choose TCP.
- For Port range, include all ports.
- For Source, use the same security group as the group ID.
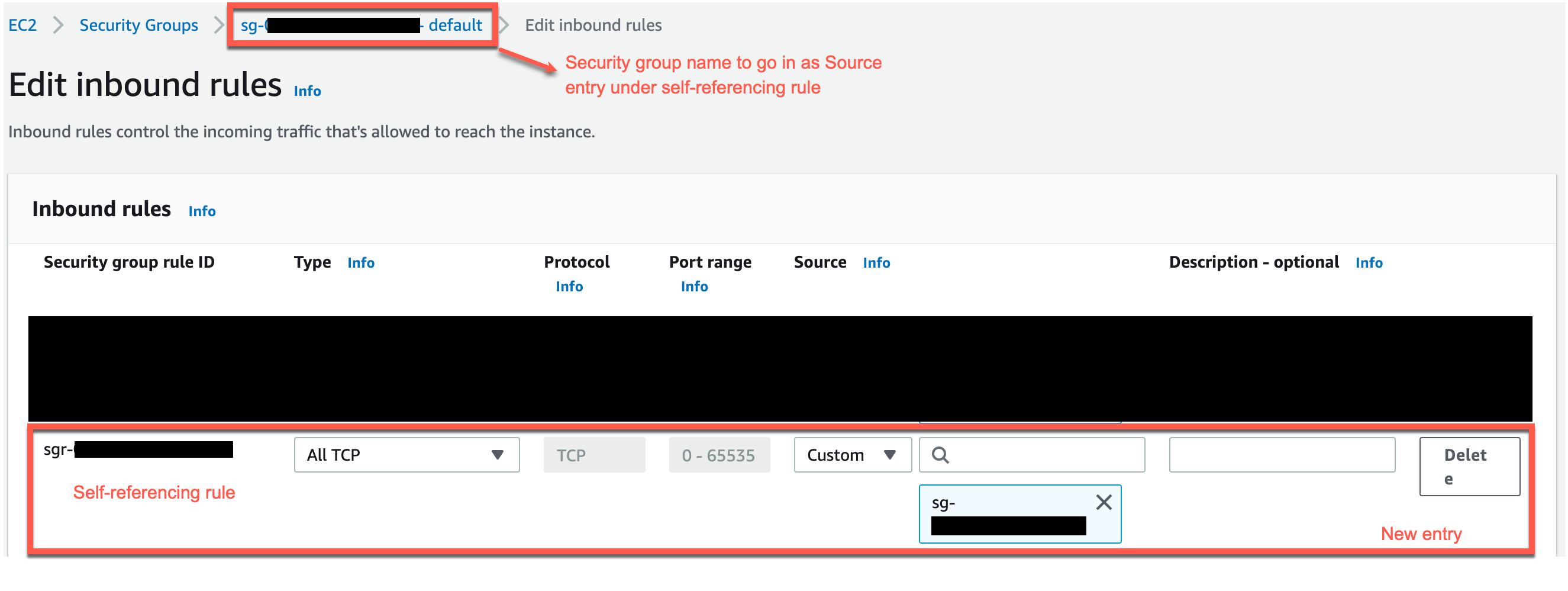
- Similarly, add the following outbound rules:
- A self-referencing rule with Type as All TCP, Protocol as TCP, Port range including all ports, and Destination as the same security group as the group ID.
- An HTTPS rule for Amazon S3 access. The
s3-prefix-list-idvalue is required in the security group rule to allow traffic from the VPC to the Amazon S3 VPC endpoint.
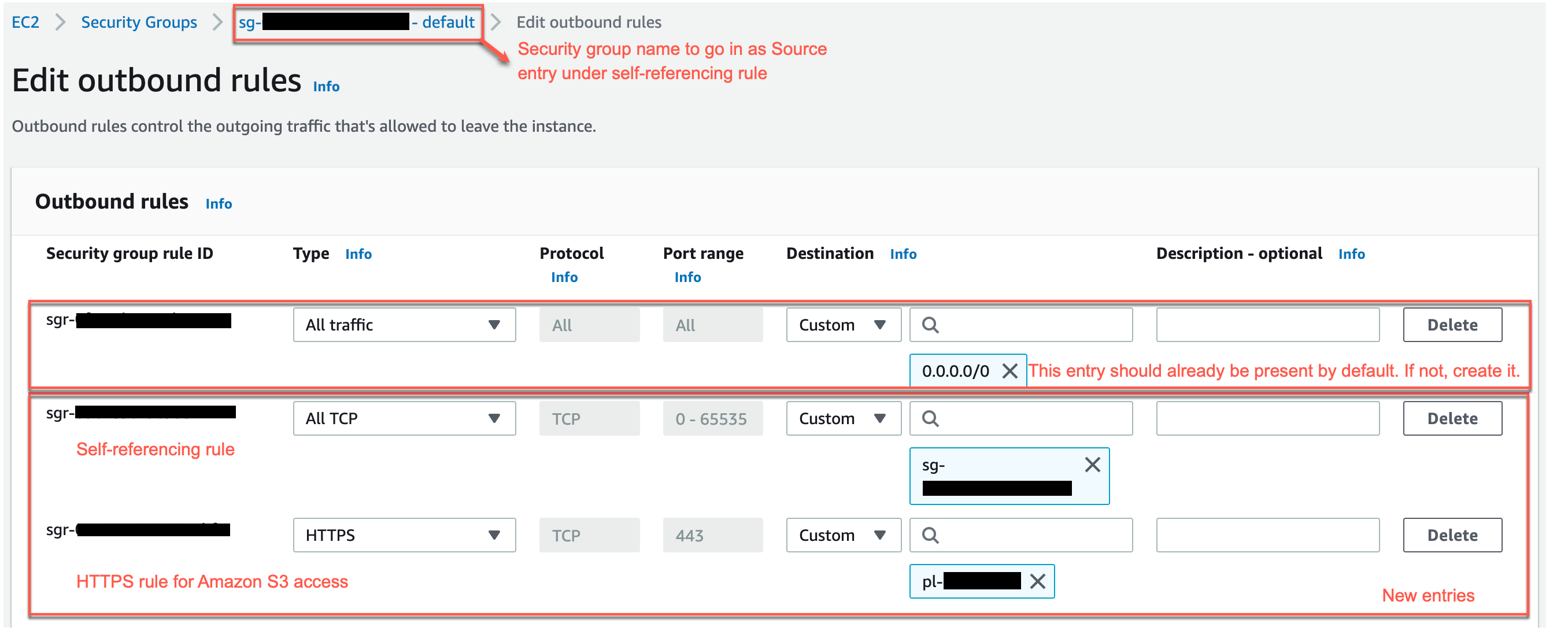
If you don’t have an Amazon S3 VPC endpoint, you can create one on the Amazon Virtual Private Cloud (Amazon VPC) console.

You can check the value for s3-prefix-list-id on the Managed prefix lists page on the Amazon VPC console.

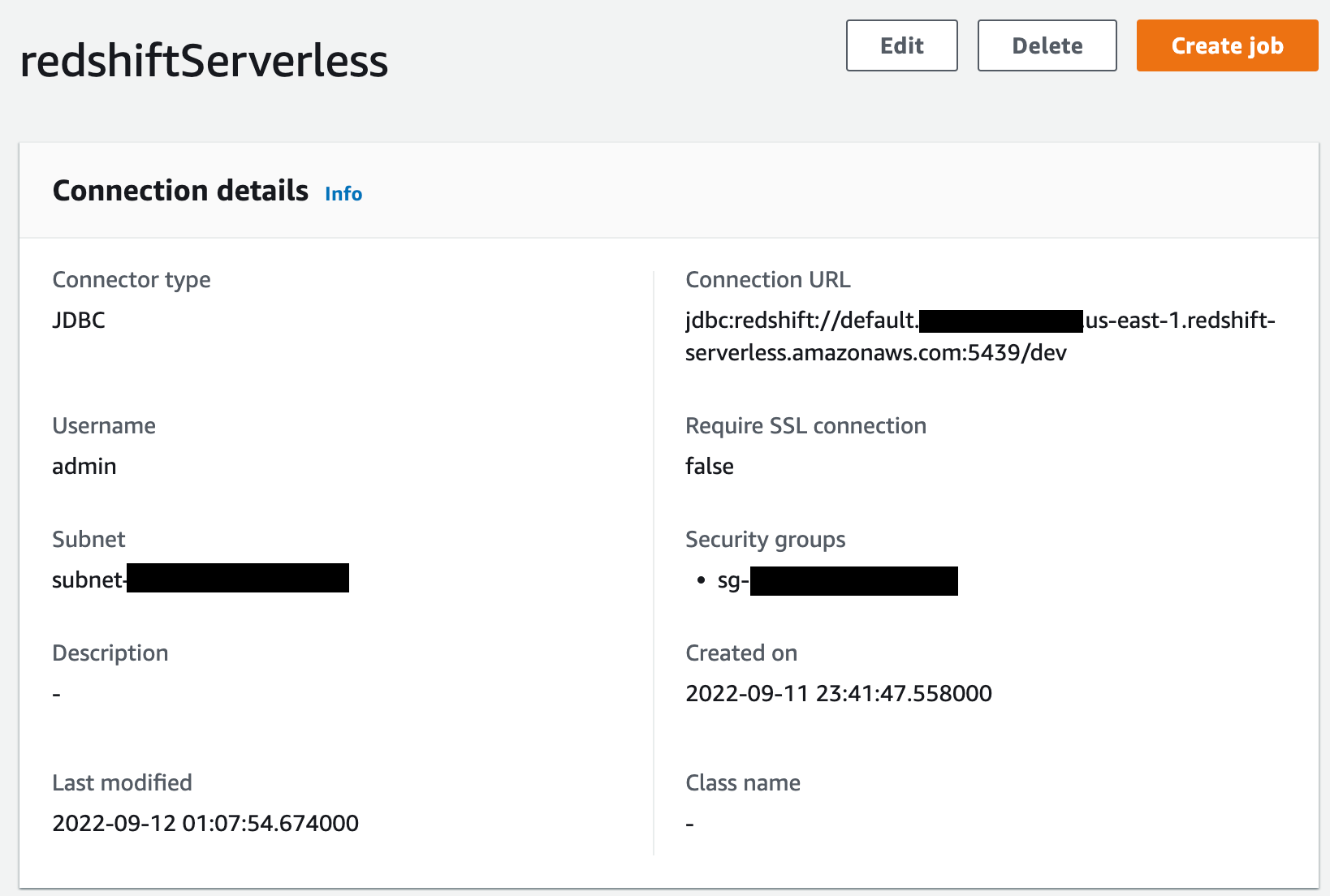
Next, go to the Connectors page on AWS Glue Studio and create a new JDBC connection called redshiftServerless to your Redshift Serverless cluster (unless one already exists). You can find the Redshift Serverless endpoint details under your workgroup’s General Information section. The connection setting looks like the following screenshot.
Write interactive code on an AWS Glue Studio Jupyter notebook powered by interactive sessions
Now you can get started with writing interactive code using AWS Glue Studio Jupyter notebook powered by interactive sessions. Note that it’s a good practice to keep saving the notebook at regular intervals while you work through it.
- On the AWS Glue Studio console, create a new job.
- Select Jupyter Notebook and select Create a new notebook from scratch.
- Choose Create.

- For Job name, enter a name (for example,
myFirstGlueISProject). - For IAM Role, choose the role you created (
AWSGlueServiceRole-GlueIS). - Choose Start notebook job.
 After the notebook is initialized, you can see some of the available magics and a cell with boilerplate code. To view all the magics of interactive sessions, run
After the notebook is initialized, you can see some of the available magics and a cell with boilerplate code. To view all the magics of interactive sessions, run %helpin a cell to print a full list. With the exception of%%sql, running a cell of only magics doesn’t start a session, but sets the configuration for the session that starts when you run your first cell of code. For this post, we configure AWS Glue with version 3.0, three G.1X workers, idle timeout, and an Amazon Redshift connection with the help of available magics.
For this post, we configure AWS Glue with version 3.0, three G.1X workers, idle timeout, and an Amazon Redshift connection with the help of available magics. - Let’s enter the following magics into our first cell and run it:
We get the following response:
- Let’s run our first code cell (boilerplate code) to start an interactive notebook session within a few seconds:
We get the following response:
- Next, read the NYC yellow taxi data from the S3 bucket into an AWS Glue dynamic frame:
Let’s count the number of rows, look at the schema and a few rows of the dataset.
- Count the rows with the following code:
We get the following response:
- View the schema with the following code:
We get the following response:
- View a few rows of the dataset with the following code:
We get the following response:
- Now, read the taxi zone lookup data from the S3 bucket into an AWS Glue dynamic frame:
Let’s count the number of rows, look at the schema and a few rows of the dataset.
- Count the rows with the following code:
We get the following response:
- View the schema with the following code:
We get the following response:
- View a few rows with the following code:
We get the following response:
- Based on the data dictionary, lets recalibrate the data types of attributes in dynamic frames corresponding to both dynamic frames:
- Now let’s check their schema:
We get the following response:
We get the following response:
- Let’s add the column
trip_durationto calculate the duration of each trip in minutes to the taxi trip dynamic frame:Let’s count the number of rows, look at the schema and a few rows of the dataset after applying the above transformation.
- Get a record count with the following code:
We get the following response:
- View the schema with the following code:
We get the following response:
- View a few rows with the following code:
We get the following response:
- Next, load both the dynamic frames into our Amazon Redshift Serverless cluster:
Now let’s validate the data loaded in Amazon Redshift Serverless cluster by running a few queries in Amazon Redshift query editor v2. You can also use your preferred query editor.
- First, we count the number of records and select a few rows in both the target tables (
f_nyc_yellow_taxi_tripandd_nyc_taxi_zone_lookup):
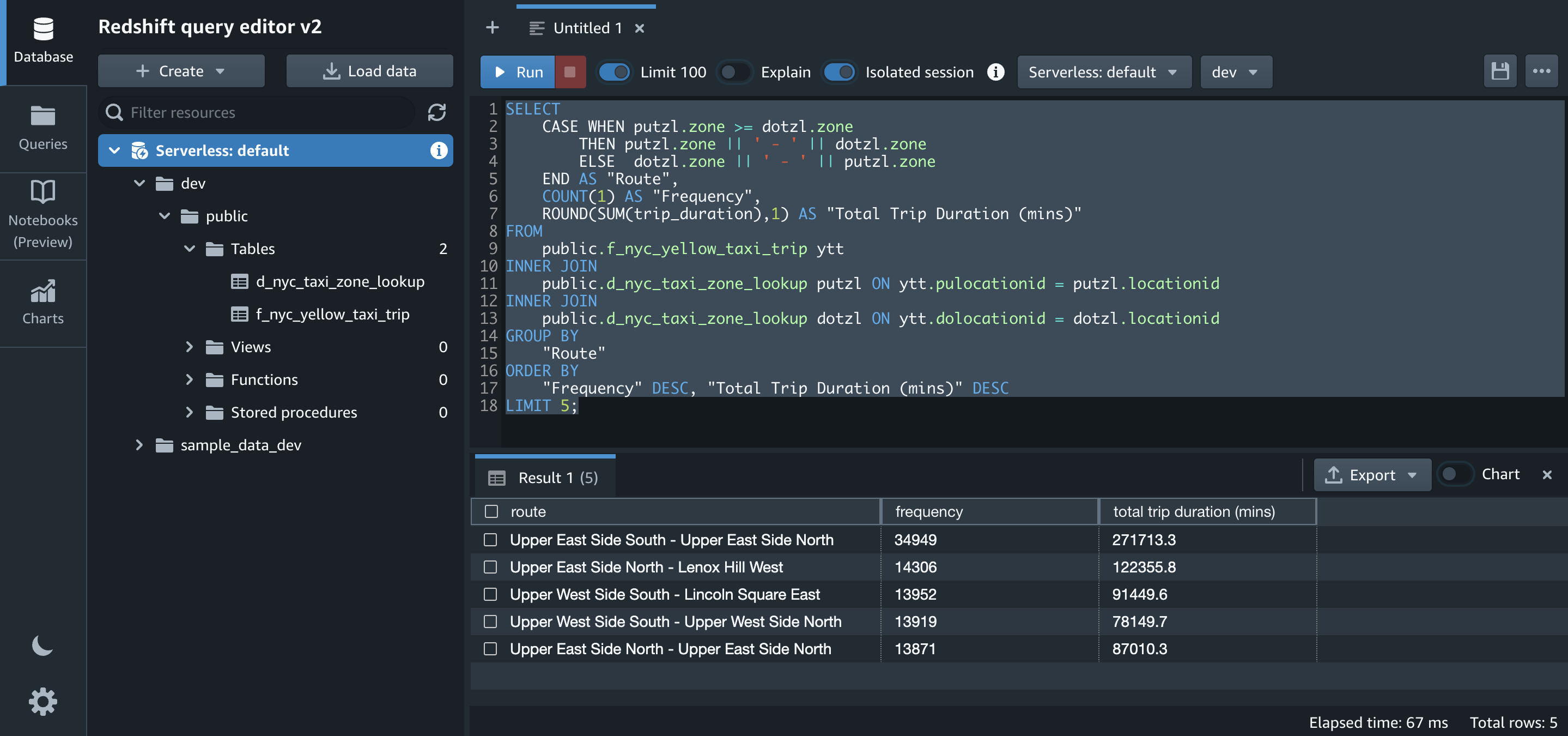
The number of records in
f_nyc_yellow_taxi_trip(2,463,931) andd_nyc_taxi_zone_lookup(265) match the number of records in our input dynamic frame. This validates that all records from files in Amazon S3 have been successfully loaded into Amazon Redshift.You can view some of the records for each table with the following commands:

- One of the insights that we want to generate from the datasets is to get the top five routes with their trip duration. Let’s run the SQL for that on Amazon Redshift:
Transform the notebook into an AWS Glue job and schedule it
Now that we have authored the code and tested its functionality, let’s save it as a job and schedule it.
Let’s first enable job bookmarks. Job bookmarks help AWS Glue maintain state information and prevent the reprocessing of old data. With job bookmarks, you can process new data when rerunning on a scheduled interval.
- Add the following magic command after the first cell that contains other magic commands initialized during authoring the code:
To initialize job bookmarks, we run the following code with the name of the job as the default argument (
myFirstGlueISProjectfor this post). Job bookmarks store the states for a job. You should always havejob.init()in the beginning of the script and thejob.commit()at the end of the script. These two functions are used to initialize the bookmark service and update the state change to the service. Bookmarks won’t work without calling them. - Add the following piece of code after the boilerplate code:
- Then comment out all the lines of code that were authored to verify the desired outcome and aren’t necessary for the job to deliver its purpose:
- Save the notebook.

You can check the corresponding script on the Script tab. Note that
Note that job.commit()is automatically added at the end of the script.Let’s run the notebook as a job. - First, truncate
f_nyc_yellow_taxi_tripandd_nyc_taxi_zone_lookuptables in Amazon Redshift using the query editor v2 so that we don’t have duplicates in both the tables: - Choose Run to run the job.
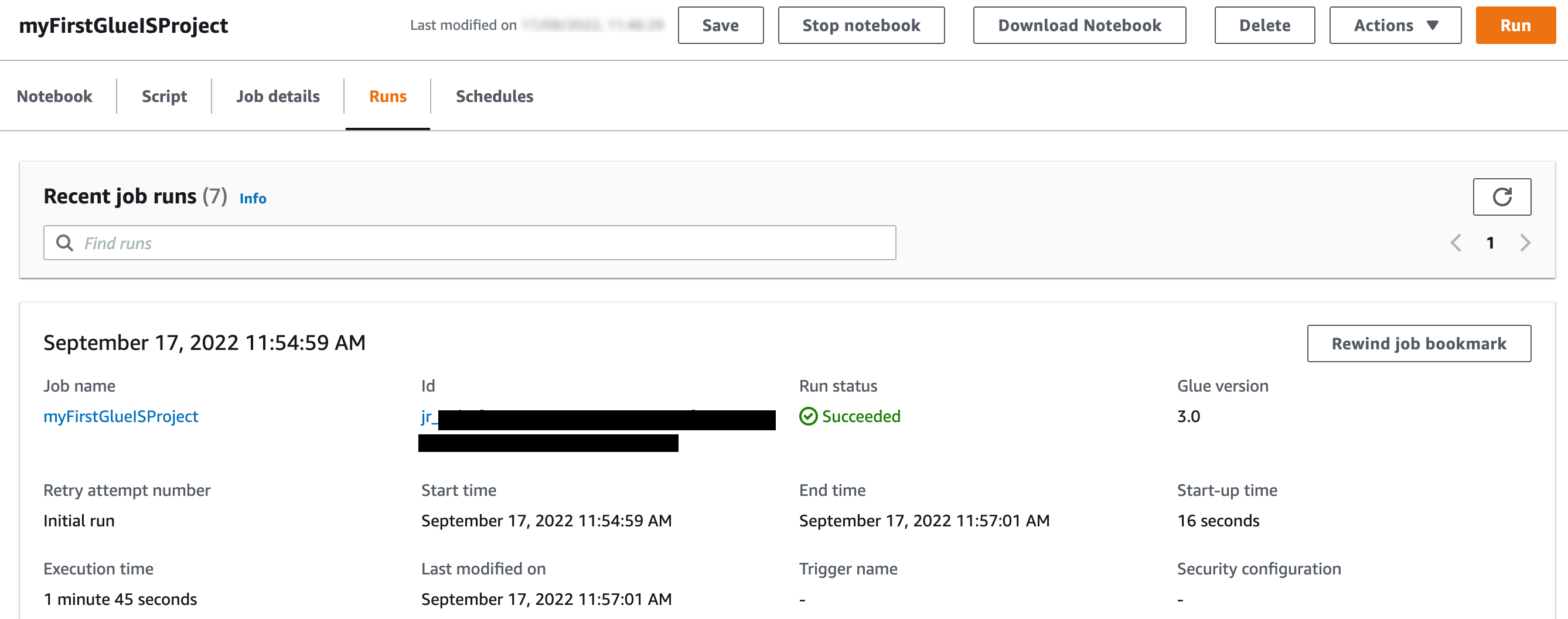
 You can check its status on the Runs tab.
You can check its status on the Runs tab. The job completed in less than 5 minutes with G1.x 3 DPUs.
The job completed in less than 5 minutes with G1.x 3 DPUs. - Let’s check the count of records in
f_nyc_yellow_taxi_tripandd_nyc_taxi_zone_lookuptables in Amazon Redshift:
With job bookmarks enabled, even if you run the job again with no new files in corresponding folders in the S3 bucket, it doesn’t process the same files again. The following screenshot shows a subsequent job run in my environment, which completed in less than 2 minutes because there were no new files to process.
Now let’s schedule the job.
- On the Schedules tab, choose Create schedule.

- For Name¸ enter a name (for example,
myFirstGlueISProject-testSchedule). - For Frequency, choose Custom.
- Enter a cron expression so the job runs every Monday at 6:00 AM.
- Add an optional description.
- Choose Create schedule.

The schedule has been saved and activated. You can edit, pause, resume, or delete the schedule from the Actions menu.

Clean up
To avoid incurring future charges, delete the AWS resources you created.
- Delete the AWS Glue job (
myFirstGlueISProjectfor this post). - Delete the Amazon S3 objects and bucket (
my-first-aws-glue-is-project-<random number>for this post). - Delete the AWS IAM policies and roles (
AWSGlueInteractiveSessionPassRolePolicy,AmazonS3Access-MyFirstGlueISProjectandAWSGlueServiceRole-GlueIS). - Delete the Amazon Redshift tables (
f_nyc_yellow_taxi_tripandd_nyc_taxi_zone_lookup). - Delete the AWS Glue JDBC Connection (
redshiftServerless). - Also delete the self-referencing Redshift Serverless security group, and Amazon S3 endpoint (if you created it while following the steps for this post).
Conclusion
In this post, we demonstrated how to do the following:
- Set up an AWS Glue Jupyter notebook with interactive sessions
- Use the notebook’s magics, including the AWS Glue connection onboarding and bookmarks
- Read the data from Amazon S3, and transform and load it into Amazon Redshift Serverless
- Configure magics to enable job bookmarks, save the notebook as an AWS Glue job, and schedule it using a cron expression
The goal of this post is to give you step-by-step fundamentals to get you going with AWS Glue Studio Jupyter notebooks and interactive sessions. You can set up an AWS Glue Jupyter notebook in minutes, start an interactive session in seconds, and greatly improve the development experience with AWS Glue jobs. Interactive sessions have a 1-minute billing minimum with cost control features that reduce the cost of developing data preparation applications. You can build and test applications from the environment of your choice, even on your local environment, using the interactive sessions backend.
Interactive sessions provide a faster, cheaper, and more flexible way to build and run data preparation and analytics applications. To learn more about interactive sessions, refer to Job development (interactive sessions), and start exploring a whole new development experience with AWS Glue. Additionally, check out the following posts to walk through more examples of using interactive sessions with different options:
- Introducing AWS Glue interactive sessions for Jupyter
- Author AWS Glue jobs with PyCharm using AWS Glue interactive sessions
- Interactively develop your AWS Glue streaming ETL jobs using AWS Glue Studio notebooks
- Prepare data at scale in Amazon SageMaker Studio using serverless AWS Glue interactive sessions
About the Authors
 Vikas Omer is a principal analytics specialist solutions architect at Amazon Web Services. Vikas has a strong background in analytics, customer experience management (CEM), and data monetization, with over 13 years of experience in the industry globally. With six AWS Certifications, including Analytics Specialty, he is a trusted analytics advocate to AWS customers and partners. He loves traveling, meeting customers, and helping them become successful in what they do.
Vikas Omer is a principal analytics specialist solutions architect at Amazon Web Services. Vikas has a strong background in analytics, customer experience management (CEM), and data monetization, with over 13 years of experience in the industry globally. With six AWS Certifications, including Analytics Specialty, he is a trusted analytics advocate to AWS customers and partners. He loves traveling, meeting customers, and helping them become successful in what they do.
 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He enjoys collaborating with different teams to deliver results like this post. In his spare time, he enjoys playing video games with his family.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He enjoys collaborating with different teams to deliver results like this post. In his spare time, he enjoys playing video games with his family.
 Gal Heyne is a Product Manager for AWS Glue and has over 15 years of experience as a product manager, data engineer and data architect. She is passionate about developing a deep understanding of customers’ business needs and collaborating with engineers to design elegant, powerful and easy to use data products. Gal has a Master’s degree in Data Science from UC Berkeley and she enjoys traveling, playing board games and going to music concerts.
Gal Heyne is a Product Manager for AWS Glue and has over 15 years of experience as a product manager, data engineer and data architect. She is passionate about developing a deep understanding of customers’ business needs and collaborating with engineers to design elegant, powerful and easy to use data products. Gal has a Master’s degree in Data Science from UC Berkeley and she enjoys traveling, playing board games and going to music concerts.