AWS Big Data Blog

Get started with the Amazon Redshift Data API
June 2023: This post was reviewed and updated for accuracy. The GitHub repository mentioned in this post is now updated with examples for serverless. Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that enables you to analyze your data at scale. Tens of thousands of customers use Amazon Redshift to […]

Create a custom Amazon S3 Storage Lens metrics dashboard using Amazon QuickSight
Companies use Amazon Simple Storage Service (Amazon S3) for its flexibility, durability, scalability, and ability to perform many things besides storing data. This has led to an exponential rise in the usage of S3 buckets across numerous AWS Regions, across tens or even hundreds of AWS accounts. To optimize costs and analyze security posture, Amazon […]

BIOps: Amazon QuickSight object migration and version control
DevOps is a set of practices that combines software development and IT operations. It aims to shorten the systems development lifecycle and provide continuous delivery with high software quality. Similarly, BIOps (business intelligence and IT operations) can help your Amazon QuickSight admin team automate assets migration and version control. Your team can design the migration […]

How Tophatter improved stability and lowered costs by migrating to Amazon Redshift RA3
This is a guest post co-written by Julien DeFrance of Tophatter and Jordan Myers of Etleap. Tophatter is a mobile discovery marketplace that hosts live auctions for products spanning every major category. Etleap, an AWS Advanced Tier Data & Analytics partner, is an extract, transform, load, and transform (ETLT) service built for AWS. As a […]

Run and debug Apache Spark applications on AWS with Amazon EMR on Amazon EKS
Customers today want to focus more on their core business model and less on the underlying infrastructure and operational burden. As customers migrate to the AWS Cloud, they’re realizing the benefits of being able to innovate faster on their own applications by relying on AWS to handle big data platforms, operations, and automation. Many of […]

Run a Spark SQL-based ETL pipeline with Amazon EMR on Amazon EKS
Increasingly, a business’s success depends on its agility in transforming data into actionable insights, which requires efficient and automated data processes. In the previous post – Build a SQL-based ETL pipeline with Apache Spark on Amazon EKS, we described a common productivity issue in a modern data architecture. To address the challenge, we demonstrated how to utilize a declarative approach as the key enabler to improve efficiency, which resulted in a faster time to value for businesses. Generally speaking, managing applications declaratively in Kubernetes is a widely adopted best practice. You can use the same approach to build and deploy Spark applications with open-source or in-house build frameworks to achieve the same productivity goal.

Build a SQL-based ETL pipeline with Apache Spark on Amazon EKS
Today, the most successful and fastest growing companies are generally data-driven organizations. Taking advantage of data is pivotal to answering many pressing business problems; however, this can prove to be overwhelming and difficult to manage due to data’s increasing diversity, scale, and complexity. One of the most popular technologies that businesses use to overcome these […]

How MEDHOST’s cardiac risk prediction successfully leveraged AWS analytic services
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. MEDHOST has been providing products and services to healthcare facilities of all types and sizes for over 35 years. Today, more than 1,000 healthcare facilities are partnering with MEDHOST and enhancing their […]
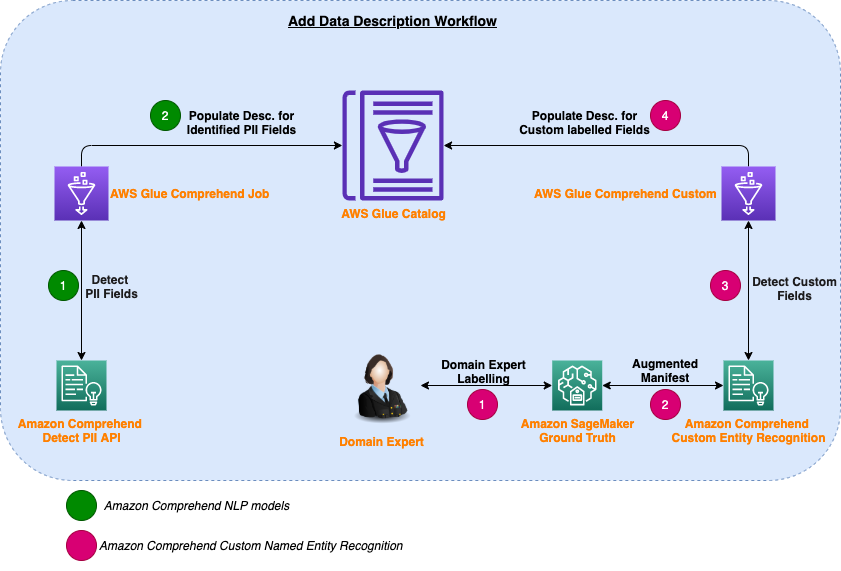
Simplify data discovery for business users by adding data descriptions in the AWS Glue Data Catalog
In this post, we discuss how to use AWS Glue Data Catalog to simplify the process for adding data descriptions and allow data analysts to access, search, and discover this cataloged metadata with BI tools. In this solution, we use AWS Glue Data Catalog, to break the silos between cross-functional data producer teams, sometimes also known […]
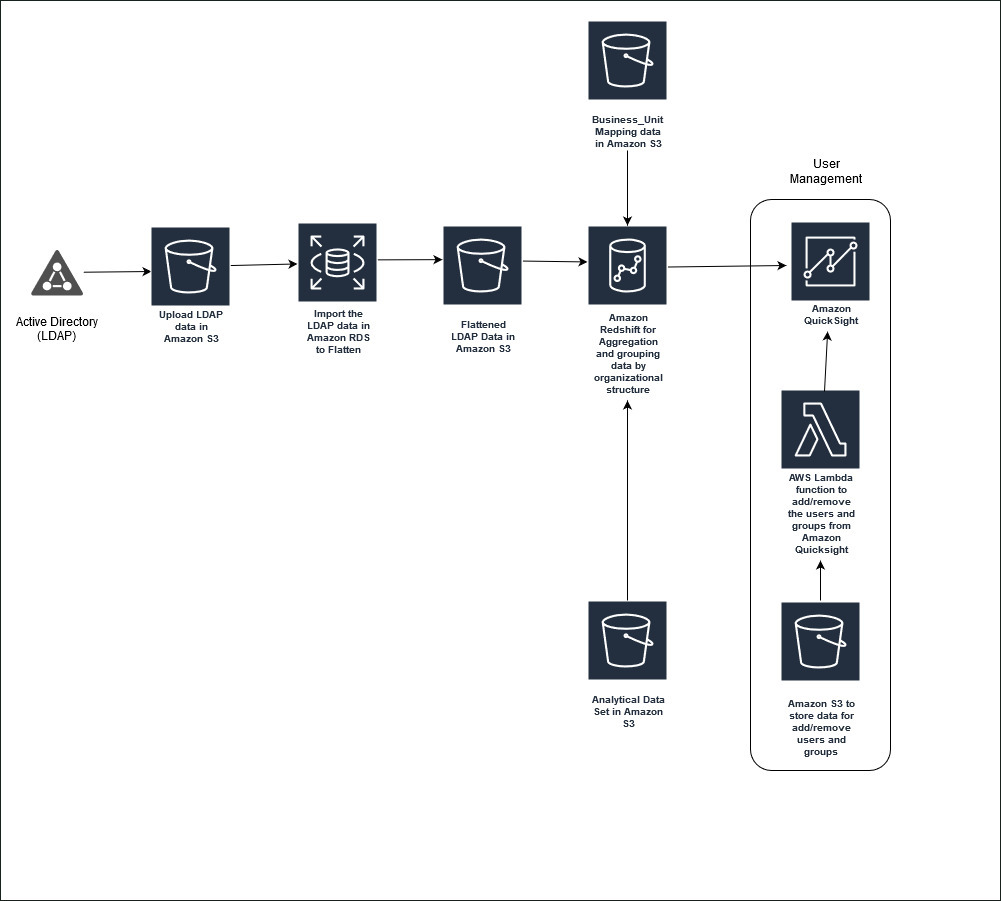
Automate Amazon QuickSight user and group management using LDAP data for row-level security
In any business intelligence system, securing and restricting access to the data is important. For example, you might want a particular dashboard to only be viewed by the users with whom the dashboard has been shared, yet customize the data displayed on that dashboard per user by implementing row-level security. With row-level security, you can […]