AWS Big Data Blog

Introducing AWS Glue 3.0 with optimized Apache Spark 3.1 runtime for faster data integration
May 2022: This post was reviewed for accuracy. In August 2020, we announced the availability of AWS Glue 2.0. AWS Glue 2.0 reduced job startup times by 10x, enabling customers to realize an average of 45% cost savings on their extract, transform, and load (ETL) jobs. The fast start time allows customers to easily adopt […]

Query SAP HANA using Athena Federated Query and join with data in your Amazon S3 data lake
This post was last reviewed and updated July, 2022 with updates in Athena federation connector. If you use data lakes in Amazon Simple Storage Service (Amazon S3) and use SAP HANA as your transactional data store, you may need to join the data in your data lake with SAP HANA in the cloud, SAP HANA […]

Implement row-level security using a complete LDAP hierarchical organization structure in Amazon QuickSight
In a world where data security is a crucial concern, it’s very important to secure data even within an organization. Amazon QuickSight provides a sophisticated way of implementing data security by applying row-level security so you can restrict data access for visualizations. An entire organization may need access to the same dashboard, but may also […]

Power your Kafka Streams application with Amazon MSK and AWS Fargate
November 2024: This post was reviewed and updated for accuracy. Today, companies of all sizes across all verticals design and build event-driven architectures centered around real-time streaming and stream processing. Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a fully managed service that makes it easy for you to build and run applications that […]

How Magellan Rx Management used Amazon Redshift ML to predict drug therapeutic conditions
This post is co-written with Karim Prasla and Deepti Bhanti from Magellan Rx Management as the lead authors. Amazon Redshift ML makes it easy for data scientists, data analysts, and database developers to create, train, and use machine learning (ML) models using familiar SQL commands in Amazon Redshift data warehouses. The ML feature can be […]

Easily manage your data lake at scale using AWS Lake Formation Tag-based access control
Thousands of customers are building petabyte-scale data lakes on AWS. Many of these customers use AWS Lake Formation to easily build and share their data lakes across the organization. As the number of tables and users increase, data stewards and administrators are looking for ways to manage permissions on data lakes easily at scale. Customers […]

Bolster security with role-based access control in Amazon MWAA
Amazon Studios invests in content that drives global growth of Amazon Prime Video and IMDb TV. Amazon Studios has a number of internal-facing applications that aim to streamline end-to-end business processes and information workflows for the entire content creation lifecycle. The Amazon Studios Data Infrastructure (ASDI) is a centralized, curated, and secure data lake that […]

How Comcast uses AWS to rapidly store and analyze large-scale telemetry data
This blog post is co-written by Russell Harlin from Comcast Corporation. Comcast Corporation creates incredible technology and entertainment that connects millions of people to the moments and experiences that matter most. At the core of this is Comcast’s high-speed data network, providing tens of millions of customers across the country with reliable internet connectivity. This […]
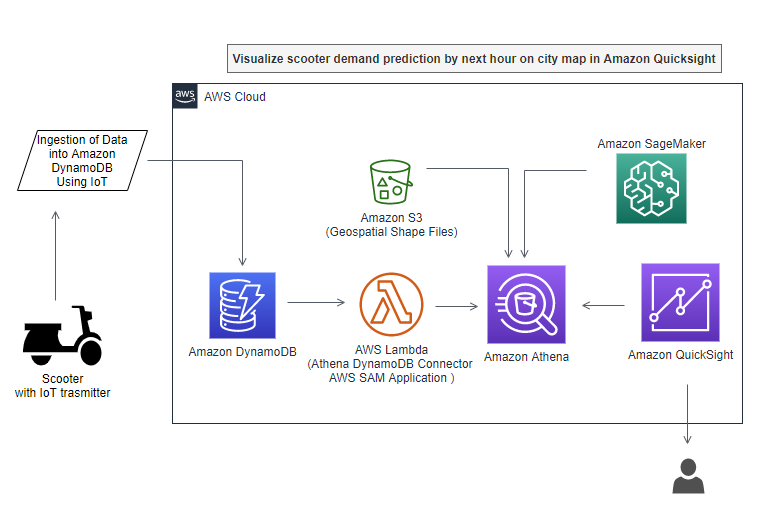
Use ML predictions over Amazon DynamoDB data with Amazon Athena ML
Today’s modern applications use multiple purpose-built database engines, including relational, key-value, document, and in-memory databases. This purpose-built approach improves the way applications use data by providing better performance and reducing cost. However, the approach raises some challenges for data teams that need to provide a holistic view on top of these database engines, and especially […]

Secure connectivity patterns to access Amazon MSK across AWS Regions
August 2023: Amazon MSK now offers a managed feature called multi-VPC private connectivity to simplify connectivity of your Kafka clients to your brokers. Refer this blog to learn more. AWS customers often segment their workloads across accounts and Amazon Virtual Private Cloud (Amazon VPC) to streamline access management while being able to expand their footprint. […]