AWS Big Data Blog
How Jobcase is using Amazon Redshift ML to recommend job search content at scale
This post is co-written with Clay Martin and Ajay Joshi from Jobcase as the lead authors.
Jobcase is an online community dedicated to empowering and advocating for the world’s workers. We’re the third-largest destination for job search in the United States, and connect millions of Jobcasers to relevant job opportunities, companies, and other resources on a daily basis. Recommendation is central to everything we do.
In this post, Jobcase data scientists discuss how Amazon Redshift ML helped us generate billions of job search recommendations in record time and with improved relevance.
The challenge: Scaling job recommendations
At Jobcase, we have used Amazon Redshift as our primary data warehouse for 8 years. Over the years, we built up a significant amount of historical job seeker and job content interaction data, which is stored in highly optimized compressed tables.
Our recommender system applies machine learning (ML) models to these big datasets, which poses a familiar problem: the data and ML models aren’t colocated on the same compute clusters, which involves moving large amounts of data across networks. In many cases, at batch inference time, data must be shuttled out of—and eventually brought back into—a data warehouse, which can be a time-consuming, expensive, and sometimes error-prone process. This also requires data engineering resources to set up data pipelines, and often becomes a bottleneck for data scientists to perform quick experimentation and drive business value. Until now, this data/model colocation issue has proven to be a big obstacle to applying ML to batch recommendation at scale.
How Amazon Redshift ML helped solve this challenge
Amazon Redshift ML, powered by Amazon SageMaker Autopilot, makes it easy for data analysts and database developers to create, train, and apply ML models using familiar SQL commands in Amazon Redshift data warehouses.
Amazon Redshift ML has proven to be a great solution to some of these problems at Jobcase. With Amazon Redshift ML’s in-database local inference capability, we now perform model inference on billions of records in a matter of minutes, directly in our Amazon Redshift data warehouse. In this post, we talk about our journey to Amazon Redshift ML, our previous attempts to use ML for recommendations, and where we go from here.

What we’re trying to solve
Job search is a unique and challenging domain for recommender system design and implementation. There are extraordinary variables to consider. For instance, many job openings only last for days or weeks, and they must be within a reasonable commute for job seekers. Some jobs require skills that only a subset of our members possess. These constraints don’t necessarily apply to, say, movie recommendations. On the other hand, job preferences are relatively stable; if a member is interested in truck driver jobs on Monday, there’s a good chance they’re still interested on Tuesday.
The Jobcase recommender system is responsible for generating job search content for over 10 million active Jobcasers per day. On average, every day we have about 20–30 million unique job listings in the eligible pool for recommendations. The system runs overnight and generates predictions in batch mode, and is expected to be completed by early morning hours. These recommendations are used throughout the day to engage with Jobcase members through various communication channels like email, SMS, and push notifications.
Our recommendation system
Each communication channel has its own peculiarities and deliverability constraints. To handle these constraints, our recommender system is broken into multiple steps and phases, where the final step is used to fine-tune the model for a particular channel. All of this multi-channel job seeker interaction data resides in our Amazon Redshift cluster.
In phase one, we apply unsupervised learning techniques to reduce the candidate set of items per member. We calculate item-item similarity scores from members’ engagement histories, and use these scores to generate the N most similar items per user. This collaborative filtering phase poses an important design trade-off: filter out too many relevant candidate items, and member engagement drops; filter out too few, and downstream inference remains computationally infeasible.
The second phase is a channel-specific supervised learning phase. It uses the similarity score from the first phase along with other predicted metrics as features and attributes, and tries to directly predict member engagement for that channel. In this example, let’s assume email is the channel and member engagement is captured by the dependent variable email click-through rate (CTR) = email clicks/email sends.
Here we also include job seeker features, such as educational attainment, commute preferences, location, and so on, as well as item or job content features, such as channel-specific historical macro or local engagement rates. Generating predictions for over 10 million job seekers paired to 200–300 items per member requires 2–3 billion predictions for just one channel.
Simplifying ML from within Amazon Redshift without any data movement
Until now, our data/model colocation problem has been challenging to solve from a cost and performance perspective. This is where Amazon Redshift ML has been instrumental in significantly improving the recommender system by enabling billions of non-linear model predictions in just a few minutes.
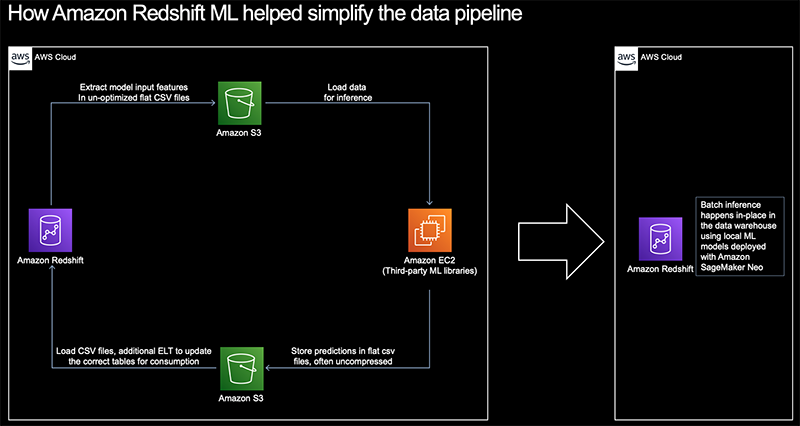
Before Amazon Redshift ML, we needed to write custom data pipelines to get data out of the data warehouse to Amazon Simple Storage Service (Amazon S3), then to ML inference instances, and finally pipe predictions back into the data warehouse for consumption. This added additional time delays and cost. Historically, it has been a challenge to improve this phase, and we had to rely on relatively simple linear models, optimized via A/B testing and hard-coded into SQL statements.
With Amazon Redshift ML, we were able to bring cutting-edge model classes with in-database local inference capabilities directly into our data warehouse. Therefore, the expressive power of the models that we could fit vastly increased. The following architecture diagram shows how we simplified our data pipeline with Amazon Redshift ML.
Our success story with Amazon Redshift ML
We have previously attempted to move one or both phases of our system out of Amazon Redshift. To improve our collaborative filtering phase, we tried using open-source libraries on Amazon Elastic Compute Cloud (Amazon EC2) instances that implement matrix factorization algorithms and natural language processing (NLP) inspired techniques such as Global Vectors (GloVe), which are distributed word representations. None of these solutions generated enough improvement in terms of member engagement to justify the increased data pipeline complexity, operational time delays, and operational expense. Pipelines to improve supervised user-item scoring had similar difficulties.
When Amazon Redshift ML was released in preview mode December 2020, we spun up a small Amazon Redshift cluster to test its capabilities against our use cases. We were immediately struck by the fact that Amazon Redshift ML makes fitting an XGBoost model or feed-forward neural network as easy as writing a SQL query. When Amazon Redshift ML became GA at the end of May 2021, we set it up in production within a day, and deployed a production model within a week. The following is a sample model that we trained and predicted with Amazon Redshift ML.
The following is the training code:
The following is the prediction code:
Now we have several models in production, each performing billions of predictions in Amazon Redshift. The following are some of the key benefits we realized with Amazon Redshift ML:
- Running model predictions at scale, performing billions of predictions in minutes, which we couldn’t achieve before implementing Amazon Redshift ML
- Significant reduction in the model development cycle by eliminating the data pipelines
- Significant reduction in model testing cycles by testing bigger cohort sizes, which helped reach our desired statistical significance quickly
- Reduced cost by using Amazon Redshift ML’s local in-database inference capability, which saved cost on external ML frameworks and compute cost
- 5–10% improvement in member engagement rates across several different email template types, resulting in increased revenue
Conclusion
In this post, we described how Amazon Redshift ML helped Jobcase effectively match millions of jobs to over 10 million active Jobcase members on a daily basis.
If you’re an Amazon Redshift user, Amazon Redshift ML provides an immediate and significant value add, with local in-database inference at no additional cost. It gives data scientists the ability to experiment quickly without data engineering dependencies. Amazon Redshift ML currently supports regression and classification model types, but is still able to achieve a great balance between speed, accuracy, complexity, and cost.
About Authors
 Clay Martin is a Data Scientist at Jobcase Inc. He designs recommender systems to connect Jobcase members with the most relevant job content.
Clay Martin is a Data Scientist at Jobcase Inc. He designs recommender systems to connect Jobcase members with the most relevant job content.
 Ajay Joshi is Senior Software Engineer at Jobcase Inc. Ajay supports the data analytics and machine learning infrastructure at Jobcase and helps them design and maintain data warehouses powered by Amazon Redshift, Amazon SageMaker, and other AWS services.
Ajay Joshi is Senior Software Engineer at Jobcase Inc. Ajay supports the data analytics and machine learning infrastructure at Jobcase and helps them design and maintain data warehouses powered by Amazon Redshift, Amazon SageMaker, and other AWS services.
 Manash Deb is a Senior Analytics Specialist Solutions Architect at AWS. He has worked on building end-to-end data-driven solutions in different database and data warehousing technologies for over 15 years. He loves to learn new technologies and solving, automating, and simplifying customer problems with easy-to-use cloud data solutions on AWS.
Manash Deb is a Senior Analytics Specialist Solutions Architect at AWS. He has worked on building end-to-end data-driven solutions in different database and data warehousing technologies for over 15 years. He loves to learn new technologies and solving, automating, and simplifying customer problems with easy-to-use cloud data solutions on AWS.
 Debu Panda, a Principal Product Manager at AWS, is an industry leader in analytics, application platform, and database technologies, and has more than 25 years of experience in the IT world.
Debu Panda, a Principal Product Manager at AWS, is an industry leader in analytics, application platform, and database technologies, and has more than 25 years of experience in the IT world.