AWS Big Data Blog
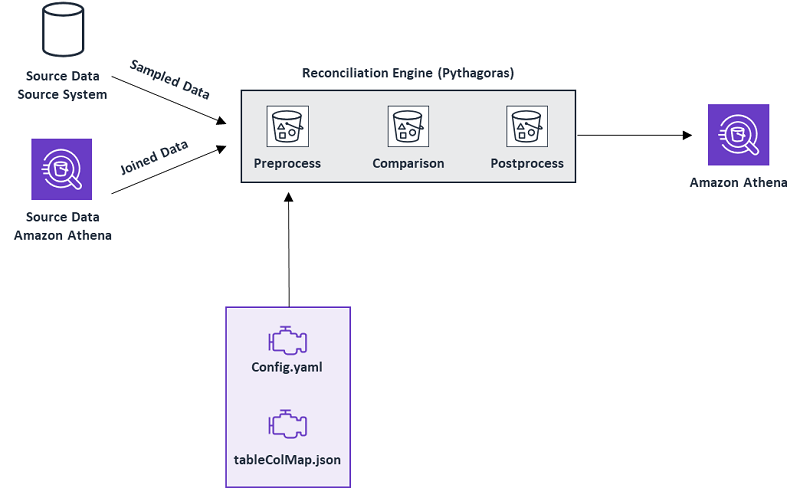
Build a distributed big data reconciliation engine using Amazon EMR and Amazon Athena
This is a guest post by Sara Miller, Head of Data Management and Data Lake, Direct Energy; and Zhouyi Liu, Senior AWS Developer, Direct Energy. Enterprise companies like Direct Energy migrate on-premises data warehouses and services to AWS to achieve fully manageable digital transformation of their organization. Freedom from traditional data warehouse constraints frees up […]

Embed multi-tenant analytics in applications with Amazon QuickSight
Amazon QuickSight recently introduced four new features—embedded authoring, namespaces for multi-tenancy, custom user permissions, and account-level customizations—that, with existing dashboard embedding and API capabilities available in the Enterprise Edition, allow you to integrate advanced dashboarding and analytics capabilities within SaaS applications. Developers and independent software vendors (ISVs) who build these applications can now offer embedded, […]

New Relic drinks straight from the Firehose: Consuming Amazon Kinesis data
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. New Relic can now ingest data directly from Amazon Kinesis Data Firehose, expanding the insights New Relic can give you into your cloud stacks so you can deliver more perfect software. Kinesis […]
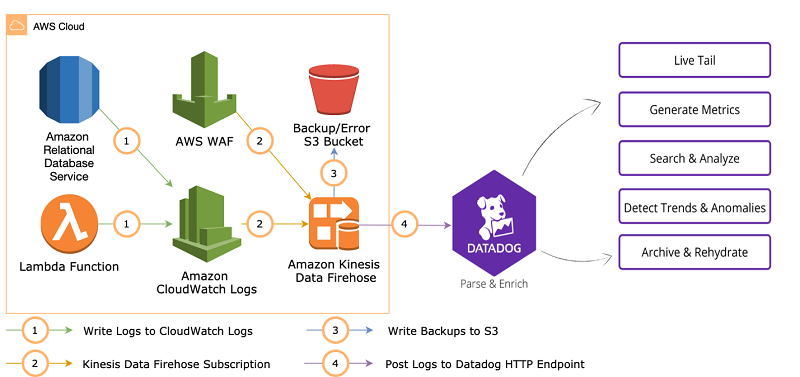
Analyze logs with Datadog using Amazon Kinesis Data Firehose HTTP endpoint delivery
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Amazon Kinesis Data Firehose now provides an easy-to-configure and straightforward process for streaming data to a third-party service for analysis, including logs from AWS services. Due to the varying formats and high […]
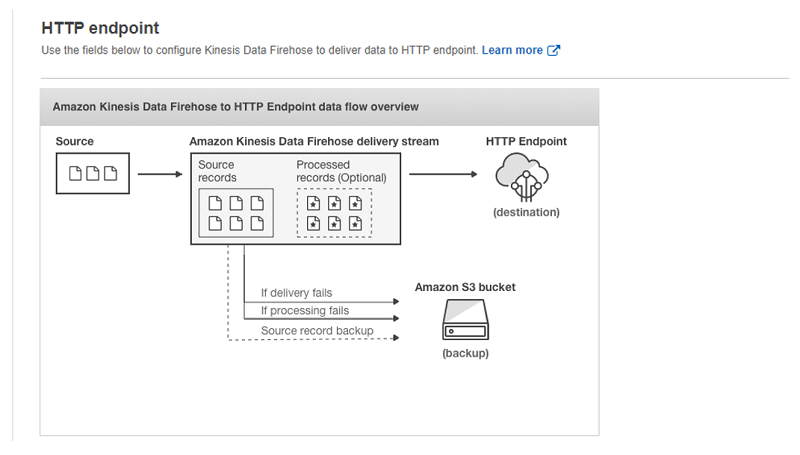
Stream data to an HTTP endpoint with Amazon Data Firehose
November 2024: This post was reviewed and updated for accuracy. The value of data is time sensitive. Streaming data services can help you move data quickly from data sources to new destinations for downstream processing. For example, Amazon Data Firehose can reliably load streaming data into data stores like Amazon Simple Storage Service (Amazon S3), Amazon Redshift, Amazon OpenSearch Service, and […]

Manage and control your cost with Amazon Redshift Concurrency Scaling and Spectrum
This post shares the simple steps you can take to use the new Amazon Redshift usage controls feature to monitor and control your usage and associated cost for Amazon Redshift Spectrum and Concurrency Scaling features. Redshift Spectrum enables you to power a lake house architecture to directly query and join data across your data warehouse and data lake, and Concurrency Scaling enables you to support thousands of concurrent users and queries with consistently fast query performance.

Federate access to your Amazon Redshift cluster with Active Directory Federation Services (AD FS): Part 2
In the first post of this series, Federating access to your Amazon Redshift cluster with Active Directory: Part 1, you set up Microsoft Active Directory Federation Services (AD FS) and Security Assertion Markup Language (SAML) based authentication and tested the SAML federation using a web browser. In Part 2, you learn to set up an […]

Federate access to your Amazon Redshift cluster with Active Directory Federation Services (AD FS): Part 1
This blog post was reviewed and updated May 2022, to include and comply with recently published Part 3 from this series. Many customers request detailed steps to set up federated single sign-on (SSO) using Microsoft Active Directory Federation Services (AD FS) for Amazon Redshift. In this two-part series, you will find detailed steps to achieve […]
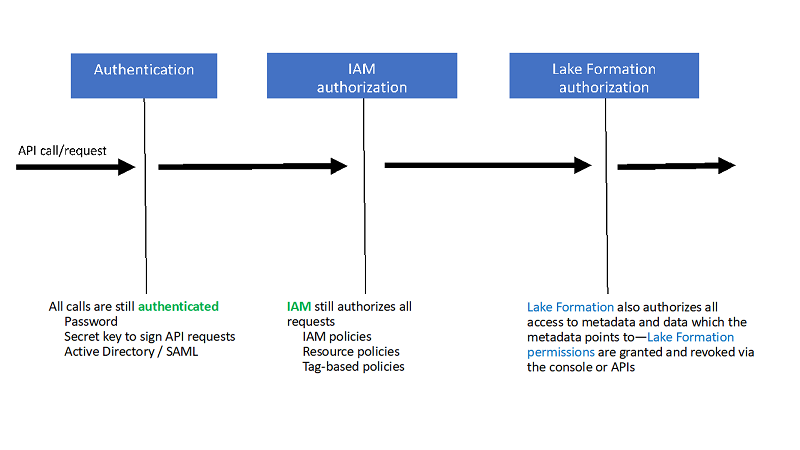
Enable fine-grained data access in Zeppelin Notebook with AWS Lake Formation
This post explores how you can use AWS Lake Formation integration with Amazon EMR (still in beta) to implement fine-grained column-level access controls while using Spark in a Zeppelin Notebook. My previous post Extract Salesforce.com data using AWS Glue and analyzing with Amazon Athena showed you a simple use case for extracting any Salesforce object data using AWS Glue and Apache Spark, saving it to Amazon Simple Storage Service (Amazon S3), cataloging the data using the Data Catalog in Glue, and querying it using Amazon Athena.
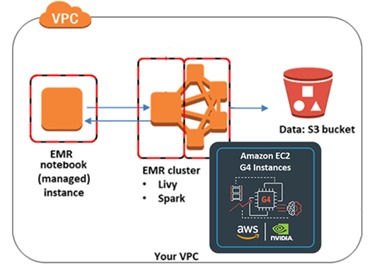
Improving RAPIDS XGBoost performance and reducing costs with Amazon EMR running Amazon EC2 G4 instances
This is a guest post by Kong Zhao, Solution Architect at NVIDIA Corporation This post shares how NVIDIA sped up RAPIDS XGBoost performance up to 4.5 times faster and reduced costs up to 5.4 times less by using Amazon EMR running Amazon Elastic Compute Cloud (Amazon EC2) G4 instances. Gradient boosting is a powerful machine […]