AWS Big Data Blog
Reduce costs by migrating Apache Spark and Hadoop to Amazon EMR
Apache Spark and Hadoop are popular frameworks to process data for analytics, often at a fraction of the cost of legacy approaches, yet at scale they may still become expensive propositions. This blog post discusses ways to reduce your total costs of ownership, while also improving staff productivity at the same time. This can be accomplished by migrating your on-premises workloads to Amazon EMR, making good architectural choices, and taking advantage of features designed to reduce the resource consumption. The advice included has been learned from hundreds of engagements with customers and many points have been validated by the findings of a recently sponsored business value study conducted by IDC’s Carl Olofson and Harsh Singh in the IDC White Paper, sponsored by Amazon Web Services (AWS), “The Economic Benefits of Migrating Apache Spark and Hadoop to Amazon EMR” (November 2018).
Let’s begin with a few headline statistics to demonstrate the positive economic impact from migrating to Amazon EMR. IDC’s survey of nine Amazon EMR customers found an average 57 percent reduced cost of ownership. This was accompanied by a 342 percent five-year ROI, and eight months to break even on the investment. Those customers varied significantly in the size of their deployments for Spark and Hadoop, and accordingly in their results. However, these are compelling numbers for IT and finance leaders to consider as they set their long-term strategy for big data processing.
Now, how exactly does Amazon EMR save you money over on-premises deployments of Spark and Hadoop? The IDC White Paper identified three common answers, which are detailed in this post.
Reducing physical infrastructure costs
An on-premises deployment inevitably has not fully used its hardware for several reasons. One is the provisioning cycle in which servers are selected, ordered, and installed in anticipation of future needs. Despite the efforts to estimate resource needs, this cycle usually brings a tendency to over-provision. In other words, investing capital in assets that aren’t used immediately. This cycle can also result in reaching the resource capacity limits — limiting the ability to complete needed big data processing in a timely fashion.
This is further magnified by the Spark and Hadoop architecture because of the way distinct resources are provisioned in fixed ratios in servers. Each server has a given number of processors and memory (compute) and a set amount of storage capacity. Some workloads may be storage intensive, with vast quantities of data being retained on servers for possible future use cases. Meanwhile, the purchased compute resources sit idle until the day that data is processed and analyzed. Alternately, some workloads may require large quantities of memory or many processors for complex operations, but otherwise run against relatively small volumes of data. In these cases, the local storage may not be fully used.
Achieving durability in HDFS on premises requires multiple copies of data, which increases the hardware requirement. This is already incorporated into Amazon S3, so decoupling compute and storage also reduces the hardware footprint by removing the need to replicate for durability. Although Spark and Hadoop use commodity hardware, which is far more cost efficient than traditional data warehouse appliances, the on premises approach is inherently wasteful, rigid, and not agile enough to meet varying needs over time.
AWS solutions architect Bruno Faria recently gave a talk at re:Invent 2018 about more sophisticated approaches to “Lower Costs on Amazon EMR: Auto Scaling, Spot Pricing, and Expert Strategies”. Let’s recap those points.
Amazon EMR has several natural advantages over the challenges faced on premises. Customers pay only for the resources they actually consume, and only when they use them. On-demand resources lessen the over- and under-provisioning problem. More advanced customers can decouple their compute and storage resources too. They can store as much data as they need to in Amazon S3 and scale their only costs as data volumes grow, not in advance.
Moreover, they can implement their choice of compute instances that are appropriately sized to the job at hand. They are also on-demand, and charged on a granular “per-second of usage” basis. This brings both more cost savings and more agility. Sometimes, customers “lift and shift” their on-premises workloads to AWS and run in Amazon EC2 without Amazon EMR. However, this doesn’t take advantage of the decoupling effect, and is recommended only as an intermediate step of migration.
Once a customer is running their Spark and Hadoop in AWS, they can further reduce compute costs. They can choose from reserved instances, which means making a payment for an expected baseline at significant discounts. This is complemented by On-demand instances, meaning available at any time and paid per-second, and also Spot instances. Spot instances provide interruptible resources for less sensitive workloads at heavily reduced prices. Instance fleets also include the ability for you to specify:
- A defined duration (Spot block) to keep the Spot Instances running.
- The maximum Spot price that you’re willing to pay.
- A timeout period for provisioning Spot Instances.
To let customers blend these purchasing options for the best results, you should understand the:
- Baseline demand, with predictable SLAs and needs.
- Periodic or unexpected peaks, to exceed SLA at reduced costs.
- Nature of the jobs, whether they are transient or long running.
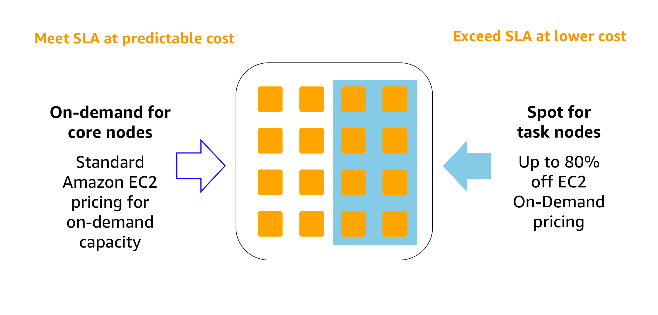
For more information about the instance purchasing options, see Instance Purchasing Options.
The Auto Scaling feature in EMR, available since 2016, can make this even more efficient to implement. It lets the service automatically manage user demand versus resources consumed as this ratio varies over time. For more information, see these best practices for automatic scaling.
Even storage costs can be reduced further. EMRFS, which decouples storage with Amazon S3 provides the ability to scale the clusters’ compute resources independent of storage capacity. In other words, EMRFS alone should already help to reduce costs. Another way to save on storage costs is to partition data to reduce the amount that needs to be scanned for processing and analytics. This is subject to the “Goldilocks” principle, where a customer wants partitions sized to avoid paying for reading unneeded data, but large enough to avoid excess overhead in finding the data needed.
An example of automatic partitioning of Apache Hive external tables is here. Optimizing file sizes can reduce Amazon S3 requests, and compressing data can minimize the bandwidth required to read data into compute instances. Not least, columnar formats for data storage are usually more efficient for big data processing and analytics than row-based layouts.
Applying these recommended methods led to the 57 percent reduction in total cost of ownership, cited earlier in this post.
Capturing these ideas nicely is a quote from the IDC White Paper where an Amazon EMR customer said the following:
“Amazon EMR gave us the best bang for the buck. One of the key factors is that our data is obviously growing. Running our big data operations on [Amazon] EMR increases confidence. It’s really good since we get cheap storage for huge amounts of data. The second thing is that the computation that we need fluctuates highly. Some of the data in our database is only occasionally used by our business or data analysts. We choose EMR because it is the most cost-effective solution as well as providing need-based computational expansion.”
Driving higher IT staff productivity
While infrastructure savings can be the most obvious driver for moving Apache Spark and Amazon EMR to the public cloud, improved IT staff productivity may have a significant benefit also. As Amazon EMR is a managed service, there is no need for a staff to spend time evaluating, purchasing, installing, provisioning, integrating, maintaining, or supporting their hardware infrastructure. Nor do they need to evaluate, install, patch, upgrade, or troubleshoot their software infrastructure, which in the rapidly innovating open-source software world can be a never-ending task.
All that effort and associated “soft” costs go away, as the Amazon EMR environment is managed and kept current for customers. IT staff can instead focus their time on assisting data engineers, data scientists, and business analysts in their strategic endeavors, rather than doing infrastructure administration. The IDC White Paper linked these benefits to a 62 percent reduction in staff time cost per year vs. on premises, along with 54 percent reduction of staff costs for the big data environment managers. Respondents also said it helped them be more agile, improve quality, and develop quicker.
Another customer interviewed by IDC summed this up by saying the following:
“We went with Amazon EMR’s ready-made integration site. It is all about not having to spend time on integration…If we choose another Hadoop technology, then our researchers would have to make that work but if we run into a road block and it doesn’t work, we might learn that the hard way. In a way, we would be doing more testing, which would have meant we needed to hire three more people to do the integration work if we weren’t on Amazon EMR.”
Providing stronger big data environment availability
The third major area of savings cited was improved risk mitigation. Because AWS services are built upon many years of learned lessons in efficient and resilient operations, they deliver against promises of greater than 99.99% availability and durability, often with many more 9’s too. Avoiding unplanned downtime was noted by the IDC study to bring a 99% reduction in lost productivity amongst IT and analytics staff.
A customer noted, “We have made systems much more resilient. It is really all about performance and resiliency.”
There are many other economics benefits of migrating to Amazon EMR. They are often linked to improved staff productivity and delivering not only cost savings, but improved performance and a measurable ROI on analytics. But let’s not spoil the whole IDC White Paper, you can read it for yourself!
About the Author
 Nikki Rouda is the principal product marketing manager for data lakes and big data at AWS. Nikki has spent 20+ years helping enterprises in 40+ countries develop and implement solutions to their analytics and IT infrastructure challenges. Nikki holds an MBA from the University of Cambridge and an ScB in geophysics and math from Brown University.
Nikki Rouda is the principal product marketing manager for data lakes and big data at AWS. Nikki has spent 20+ years helping enterprises in 40+ countries develop and implement solutions to their analytics and IT infrastructure challenges. Nikki holds an MBA from the University of Cambridge and an ScB in geophysics and math from Brown University.