AWS Big Data Blog

Dynamically Create Friendly URLs for Your Amazon EMR Web Interfaces
This solution provides a serverless approach to automatically assigning a friendly name for your EMR cluster for easy access to popular notebooks and other web interfaces.

Top 9 Best Practices for High-Performance ETL Processing Using Amazon Redshift
When migrating from a legacy data warehouse to Amazon Redshift, it is tempting to adopt a lift-and-shift approach, but this can result in performance and scale issues long term. This post guides you through the following best practices for ensuring optimal, consistent runtimes for your ETL processes.

Optimize Delivery of Trending, Personalized News Using Amazon Kinesis and Related Services
Gunosy aims to provide people with the content they want without the stress of dealing with a large influx of information. We analyze user attributes, such as gender and age, and past activity logs like click-through rate (CTR). We combine this information with article attributes to provide trending, personalized news articles to users. In this post, I show you how to process user activity logs in real time using Amazon Kinesis Data Firehose, Amazon Kinesis Data Analytics, and related AWS services.

AWS Glue Now Supports Scala Scripts
We are excited to announce AWS Glue support for running ETL (extract, transform, and load) scripts in Scala. Scala lovers can rejoice because they now have one more powerful tool in their arsenal.

Use Kerberos Authentication to Integrate Amazon EMR with Microsoft Active Directory
This post walks you through the process of using AWS CloudFormation to set up a cross-realm trust and extend authentication from an Active Directory network into an Amazon EMR cluster with Kerberos enabled. By establishing a cross-realm trust, Active Directory users can use their Active Directory credentials to access an Amazon EMR cluster and run jobs as themselves.
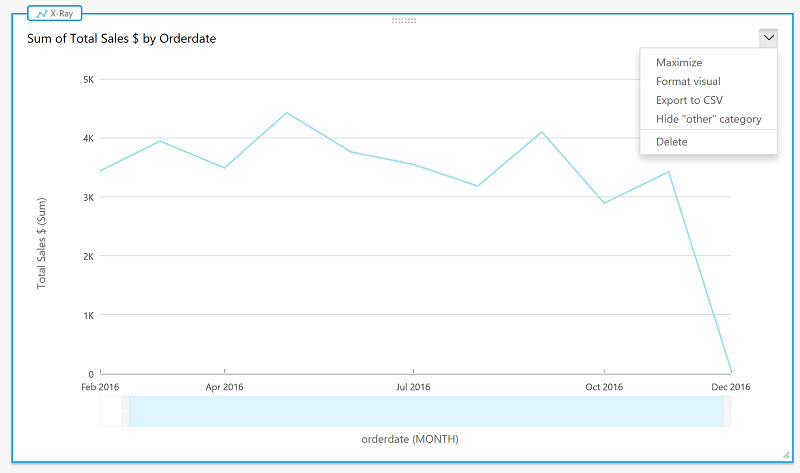
Combine Transactional and Analytical Data Using Amazon Aurora and Amazon Redshift
A few months ago, we published a blog post about capturing data changes in an Amazon Aurora database and sending it to Amazon Athena and Amazon QuickSight for fast analysis and visualization. In this post, I want to demonstrate how easy it can be to take the data in Aurora and combine it with data in Amazon Redshift using Amazon Redshift Spectrum.
Now Available: New Digital Training to Help You Learn About AWS Big Data Services
AWS Training and Certification recently released free digital training courses that will make it easier for you to build your cloud skills and learn about using AWS Big Data services. This training includes courses like Introduction to Amazon EMR and Introduction to Amazon Athena.

Custom Log Presto Query Events on Amazon EMR for Auditing and Performance Insights
In this blog post, we will demonstrate how to implement and install a Presto event listener for purposes of custom logging, debugging and performance analysis for queries executed on an EMR cluster.

Simplify Querying Nested JSON with the AWS Glue Relationalize Transform
AWS Glue has a transform called Relationalize that simplifies the extract, transform, load (ETL) process by converting nested JSON into columns that you can easily import into relational databases. Relationalize transforms the nested JSON into key-value pairs at the outermost level of the JSON document. The transformed data maintains a list of the original keys from the nested JSON separated by periods. Let’s look at how Relationalize can help you with a sample use case.

Genomic Analysis with Hail on Amazon EMR and Amazon Athena
For this task, we use Hail, an open source framework for exploring and analyzing genomic data that uses the Apache Spark framework. In this post, we use Amazon EMR to run Hail. We walk through the setup, configuration, and data processing. Finally, we generate an Apache Parquet–formatted variant dataset and explore it using Amazon Athena.