AWS Big Data Blog
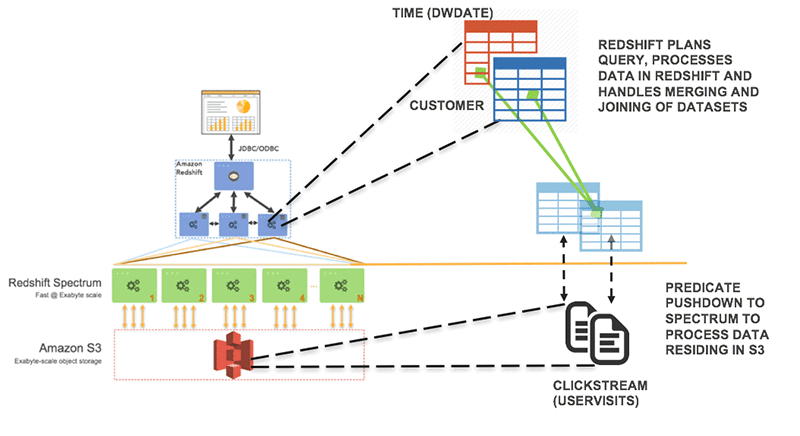
From Data Lake to Data Warehouse: Enhancing Customer 360 with Amazon Redshift Spectrum
Achieving a 360o-view of your customer has become increasingly challenging as companies embrace omni-channel strategies, engaging customers across websites, mobile, call centers, social media, physical sites, and beyond. The promise of a web where online and physical worlds blend makes understanding your customers more challenging, but also more important. Businesses that are successful in this […]
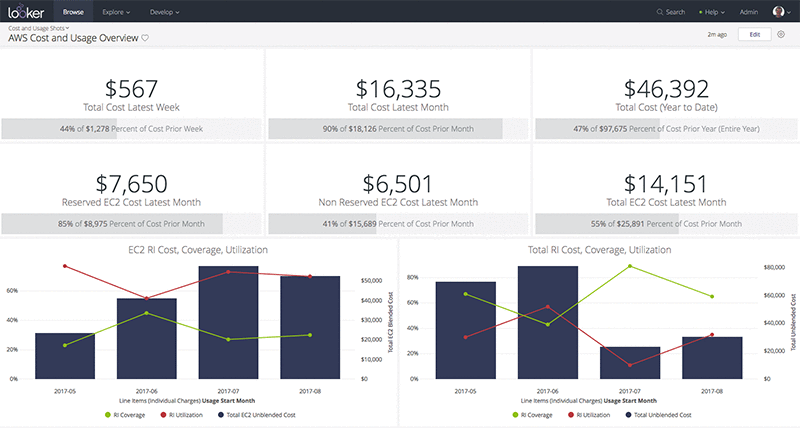
Analyzing AWS Cost and Usage Reports with Looker and Amazon Athena
In the post, I walk through setting up the data pipeline for cost and usage reports, Amazon S3, and Athena, and discuss some of the most common levers for cost savings. I surface tables through Looker, which comes with a host of pre-built data models and dashboards to make analysis of your cost and usage data simple and intuitive.
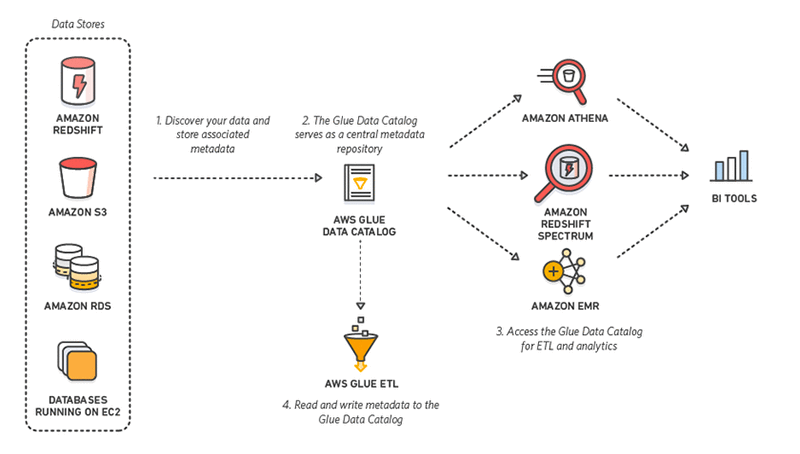
Harmonize, Query, and Visualize Data from Various Providers using AWS Glue, Amazon Athena, and Amazon QuickSight
Have you ever been faced with many different data sources in different formats that need to be analyzed together to drive value and insights? You need to be able to query, analyze, process, and visualize all your data as one canonical dataset, regardless of the data source or original format. In this post, I walk […]

Upsert into Amazon Redshift using AWS Glue and SneaQL
This is a guest post by Jeremy Winters and Ritu Mishra, Solution Architects at Full 360. In their own words, “Full 360 is a cloud first, cloud native integrator, and true believers in the cloud since inception in 2007, our focus has been on helping customers with their journey into the cloud. Our practice areas […]

Deploy a Data Warehouse Quickly with Amazon Redshift, Amazon RDS for PostgreSQL and Tableau Server
One of the benefits of a data warehouse environment using both Amazon Redshift and Amazon RDS for PostgreSQL is that you can leverage the advantages of each service. Amazon Redshift is a high performance, petabyte-scale data warehouse service optimized for the online analytical processing (OLAP) queries typical of analytic reporting and business intelligence applications. On […]

Building a Real World Evidence Platform on AWS
Deriving insights from large datasets is central to nearly every industry, and life sciences is no exception. To combat the rising cost of bringing drugs to market, pharmaceutical companies are looking for ways to optimize their drug development processes. They are turning to big data analytics to better quantify the effect that their drug compounds […]

Turbocharge your Apache Hive Queries on Amazon EMR using LLAP
NOTE: Starting from emr-6.0.0 release, Hive LLAP is officially supported as a YARN service. So setting up LLAP using the instructions from this blog post (using a bootstrap action script) is not needed for releases emr-6.0.0 and onward. ——————————- Apache Hive is one of the most popular tools for analyzing large datasets stored in a Hadoop […]

Amazon QuickSight Now Supports Amazon Athena in EU (Ireland), Count Distinct, and Week Aggregation
With this release, we expanded connectivity options by adding Amazon Athena support in the EU (Ireland) Region. Additionally, you can now use Count Distinct on your dimensions and metrics in the visualizations and aggregate date fields by week for SPICE data sets.

AWS CloudFormation Supports Amazon Kinesis Analytics Applications
You can now provision and manage resources for Amazon Kinesis Analytics applications using AWS CloudFormation. Kinesis Analytics is the easiest way to process streaming data in real time with standard SQL, without having to learn new programming languages or processing frameworks.
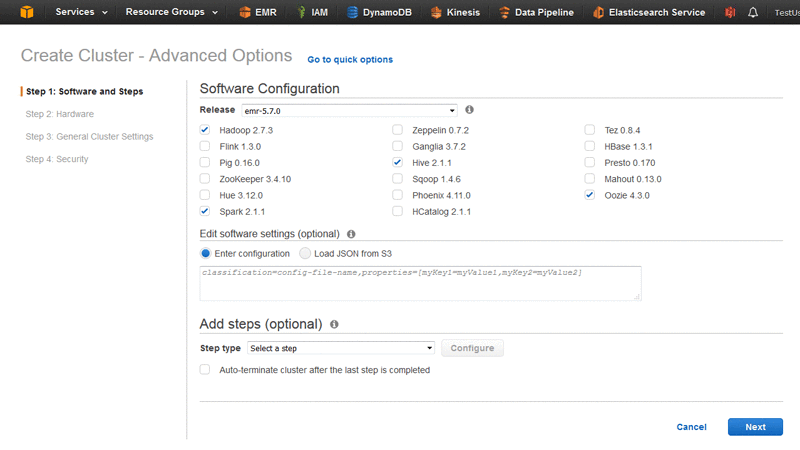
Run Common Data Science Packages on Anaconda and Oozie with Amazon EMR
In the world of data science, users must often sacrifice cluster set-up time to allow for complex usability scenarios. Amazon EMR allows data scientists to spin up complex cluster configurations easily, and to be up and running with complex queries in a matter of minutes. Data scientists often use scheduling applications such as Oozie to […]