AWS Big Data Blog
Tag: Amazon Redshift

Amazon Redshift at re:Invent 2019
The annual AWS re:Invent learning conference is an exciting time full of new product and program launches. At the first re:Invent conference in 2012, AWS announced Amazon Redshift. Since then, tens of thousands of customers have started using Amazon Redshift as their cloud data warehouse. In 2019, AWS shared several significant launches and dozens of […]

Maximize data ingestion and reporting performance on Amazon Redshift
This is a guest post from ZS. In their own words, “ZS is a professional services firm that works closely with companies to help develop and deliver products and solutions that drive customer value and company results. ZS engagements involve a blend of technology, consulting, analytics, and operations, and are targeted toward improving the commercial […]

ETL and ELT design patterns for modern data architecture using Amazon Redshift: Part 2
New: Read Amazon Redshift continues its price-performance leadership to learn what analytic workload trends we’re seeing from Amazon Redshift customers, new capabilities we have launched to improve Redshift’s price-performance, and the results from the latest benchmarks. Part 1 of this multi-post series, ETL and ELT design patterns for modern data architecture using Amazon Redshift: Part 1, […]

ETL and ELT design patterns for lake house architecture using Amazon Redshift: Part 1
New: Read Amazon Redshift continues its price-performance leadership to learn what analytic workload trends we’re seeing from Amazon Redshift customers, new capabilities we have launched to improve Redshift’s price-performance, and the results from the latest benchmarks. Part 1 of this multi-post series discusses design best practices for building scalable ETL (extract, transform, load) and ELT (extract, […]
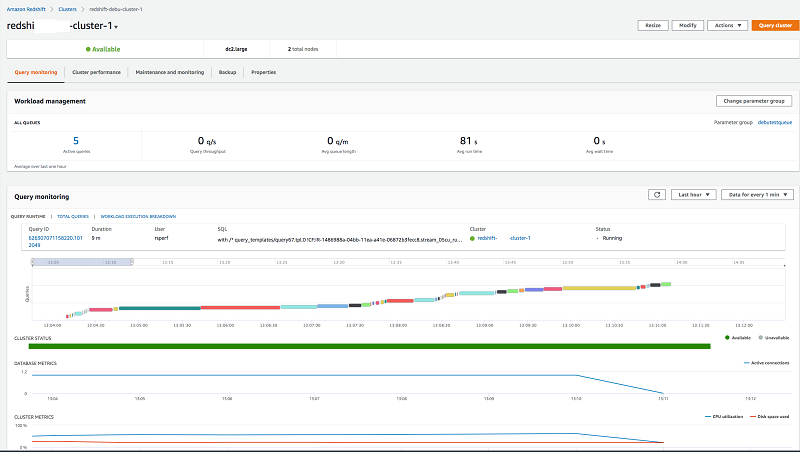
Simplify management of Amazon Redshift clusters with the Redshift console
Amazon Redshift is the most popular and the fastest cloud data warehouse. It includes a console for administrators to create, configure, and manage Amazon Redshift clusters. The new Amazon Redshift console modernizes the user interface and adds several features to improve managing your clusters and workloads running on clusters. The new Amazon Redshift console provides visibility to the health and performance of clusters from a unified dashboard, simplified management of clusters by streamlining several screens and flows, improved mean-time-to-diagnose query performance issues by adding capabilities to monitor user queries and correlate with cluster performance metrics, as well as the ability for non-admin users to use Query Editor.

Orchestrate Amazon Redshift-Based ETL workflows with AWS Step Functions and AWS Glue
In this post, I show how to use AWS Step Functions and AWS Glue Python Shell to orchestrate tasks for those Amazon Redshift-based ETL workflows in a completely serverless fashion. AWS Glue Python Shell is a Python runtime environment for running small to medium-sized ETL tasks, such as submitting SQL queries and waiting for a response. Step Functions lets you coordinate multiple AWS services into workflows so you can easily run and monitor a series of ETL tasks. Both AWS Glue Python Shell and Step Functions are serverless, allowing you to automatically run and scale them in response to events you define, rather than requiring you to provision, scale, and manage servers.

Protect and Audit PII data in Amazon Redshift with DataSunrise Security
This post focuses on active security for Amazon Redshift, in particular DataSunrise’s capabilities for masking and access control of personally identifiable information (PII), which you can back with DataSunrise’s passive security offerings such as auditing access of sensitive information. This post discusses DataSunrise security for Amazon Redshift, how it works, and how to get started.

Automate Amazon Redshift cluster creation using AWS CloudFormation
In this post, I explain how to automate the deployment of an Amazon Redshift cluster in an AWS account. AWS best practices for security and high availability drive the cluster’s configuration, and you can create it quickly by using AWS CloudFormation. I walk you through a set of sample CloudFormation templates, which you can customize as per your needs.
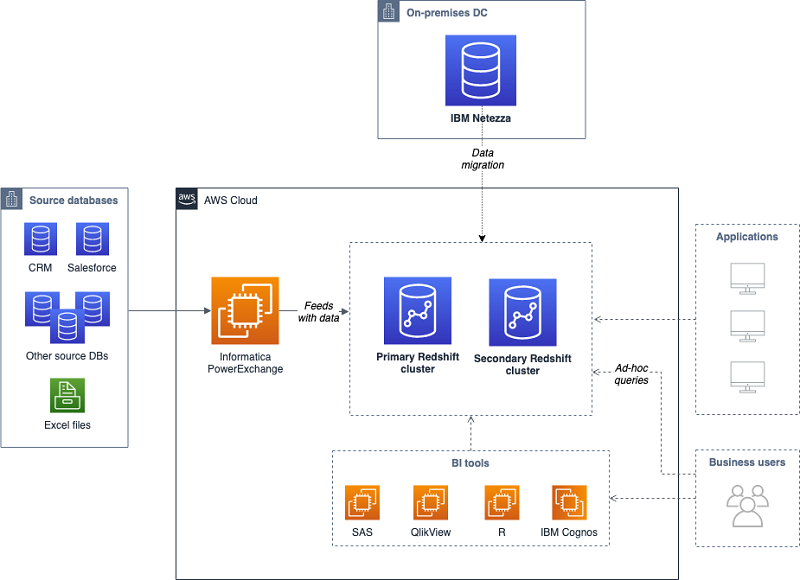
How to migrate a large data warehouse from IBM Netezza to Amazon Redshift with no downtime
In this article, we explain how this customer performed a large-scale data warehouse migration from IBM Netezza to Amazon Redshift without downtime, by following a thoroughly planned migration process, and leveraging AWS Schema Conversion Tool (SCT) and Amazon Redshift best practices.
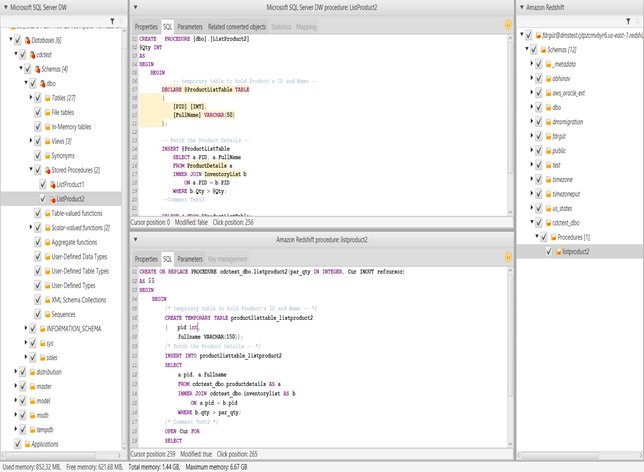
Bringing your stored procedures to Amazon Redshift
Amazon always works backwards from the customer’s needs. Customers have made strong requests that they want stored procedures in Amazon Redshift, to make it easier to migrate their existing workloads from legacy, on-premises data warehouses.
With that primary goal in mind, AWS chose to implement PL/pqSQL stored procedure to maximize compatibility with existing procedures and simplify migrations. In this post, we discuss how and where to use stored procedures to improve operational efficiency and security. We also explain how to use stored procedures with AWS Schema Conversion Tool.