AWS Big Data Blog
Protect and Audit PII data in Amazon Redshift with DataSunrise Security
DataSunrise, in their own words: DataSunrise is a database security software company that offers a breadth of security solutions, including data masking (dynamic and static masking), activity monitoring, database firewalls, and sensitive data discovery for various databases. The goal is to protect databases against external and internal threats and vulnerabilities. Customers often choose DataSunrise Database Security because it gives them unified control and a single-user experience when protecting different database engines that run on AWS, including Amazon Redshift, Amazon Aurora, all Amazon RDS database engines, Amazon DynamoDB, and Amazon Athena, among others. DataSunrise Security Suite is a set of tools that can protect and audit PII data in Amazon Redshift.
DataSunrise offers passive security with data auditing in addition to active data and database security. Active security is based on predefined security policies, such as preventing unauthorized access to sensitive data, blocking suspicious SQL queries, preventing SQL-injection attacks, or dynamically masking and obfuscating data in real time. DataSunrise comes with high availability, failover, and automatic scaling.
This post focuses on active security for Amazon Redshift, in particular DataSunrise’s capabilities for masking and access control of personally identifiable information (PII), which you can back with DataSunrise’s passive security offerings such as auditing access of sensitive information. This post discusses DataSunrise security for Amazon Redshift, how it works, and how to get started.
Why you need active security for Amazon Redshift
Amazon Redshift is a massively parallel processing (MPP), fully managed petabyte-scale data warehouse (DW) solution with over 15,000 deployments worldwide. Amazon Redshift provides a database encryption mechanism to protect sensitive data, such as payment information and health insurance. For more information, see Amazon Redshift Database Encryption.
Many organizations store sensitive data, commonly classified as personally identifiable information (PII) or sensitive personal information (SPI). You may need solutions to manage access control to such sensitive information, and want to manage it efficiently and flexibly, preferably using a management tool. DataSunrise is a centralized management tool that masks that data. It resolves the PII and SPI data access control requirement by allowing you to enforce masking policies against all queries against your Amazon Redshift data warehouse.
What DataSunrise masking does
DataSunrise enables masking queries against Amazon Redshift by acting as a proxy layer between your applications and the backend stores of Amazon Redshift, enabling transparent data flow, bindings, and so on, while your end-users receive masked or obfuscated data that allows them to do their job but prevents any risk of revealing PII data unintentionally.
DataSunrise can exempt users who are authorized to access this information by composing policies and choosing from predefined policy templates that would allow those users to bypass masking constraints when needed.
How it works
DataSunrise operates as a proxy between users or applications that connect to the database and the database server. DataSunrise intercepts the traffic for in-depth analysis and filtering. It applies data masking and access control policies to enforce active security policies against your PII data. When the database firewall is enabled and a security policy violation is detected, DataSunrise can block the malicious SQL query and notify administrators via SMTP or SNMP. With real-time alerts, you can maintain continuous database security and streamline compliance.

DataSunrise operates as a proxy
Getting started with DataSunrise
You can deploy DataSunrise on a Windows or Linux instance in Amazon EC2. You can download a fully prepared DataSunrise AMI from AWS Marketplace to protect your Amazon Redshift cluster. DataSunrise Database and Data Security are available for both Windows and Linux platforms.
After deploying DataSunrise, you can configure security policies for Amazon Redshift and create data masking and access control security rules. After you configure and activate the security policies, DataSunrise enacts those policies against the user and application traffic that would connect to the database through DataSunrise’s proxy.
DataSunrise customers need to configure the Amazon Redshift cluster security group inbound rule to allow DataSunrise IP. For more information, see Amazon Redshift Cluster Security Group. Additionally, you can include the DataSunrise security group in the cluster security group when it runs on the same AWS VPC. Users can execute queries only through connecting to the DataSunrise endpoint and not to the Amazon Redshift cluster endpoint. All DB users and groups are imported from Amazon Redshift into DataSunrise for authentication and authorization to Amazon Redshift objects.
Creating a dynamic data masking rule
Masking obfuscates part or an entire column value. When a column is masked, the column values are replaced by fake values. It is effected either by replacing some original characters with fake ones or by using some masking functions. DataSunrise has many built-in masking functions for credit card numbers, e-mails, etc. Masking protects sensitive or personally identifiable data such as credit card numbers. This is not the same as encryption or hashing, which applies a sophisticated algorithm to a scalar value to convert it into another value.
You can create dynamic masking rules using object-based filters in DataSunrise’s console. DataSunrise identifies the protected objects during application calls and enforces those security rules against targeted operations, schemas, or objects in general within your Amazon Redshift cluster. Security administrators can enable those rules granularly based on the object level and caller identity. They can allow exemptions when needed by identifying authorized callers.
To perform dynamic masking in DataSunrise, you need to create data masking rules as part of defining such security policies.
Complete the following steps to create those masking policies:
- In the DataSunrise console, choose Masking > Dynamic Masking Rules.
- Choose Add Rule. Add required information.

Create Dynamic Data Masking Rule
Create Dynamic Data Masking Rule
- In the Masking Settings section click Select and navigate to a table in a schema and check the columns you want to mask. See the following screenshot of the Check Columns page:

Redshift columns to enable dynamic masking
Redshift columns to enable dynamic masking
Click Done after you decide which column to protect and choose the masking method and any relevant settings to allow business-oriented outcomes of the masked information.
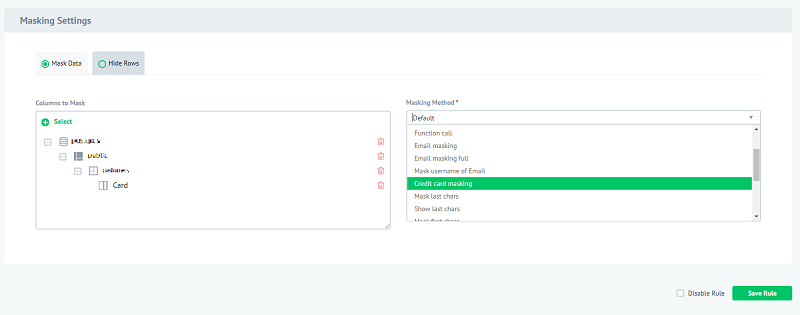
In Add Rule, Filter Sessions, you can choose which users, applications, hosts, and more are affected by this rule.

Creating a static data masking rule
You can mask data permanently with static masking as opposed to dynamic data masking. It stores the objects permanently in a separate schema or database. During static masking, DataSunrise copies each selected table into a separate schema or database. So, static masking may require additional storage space. Some of these tables have columns with masked content stored on the disk. This replicated schema is a fully functional schema in which you can run user queries. The source tables remain untouched and unmasked data can be viewed. In case original data has been changed, it is required to repeat the static masking procedure again. In that case it is necessary to truncate tables with previously masked data.
- From the menu, choose Masking > Static Masking.
- In New Static Masking Task, in Source and Target Instances, choose the source database, schema, and corresponding target destination.See the following screenshot of the New Static Masking Task page:

- In Select Source Tables to Transfer and Columns to Mask, choose the objects to which you wish to apply masking.The following screenshot shows the list of available tables:

DataSunrise also enables you to reschedule recurring static masking jobs so you can refresh your masked records based on your source or production data.
Static data masking under DataSunrise applies to Amazon Redshift local tables. In addition to local tables, Amazon Redshift allows querying external tables in Amazon S3; however, DataSunrise does not support static masking on data stored in Amazon S3 accessed in Amazon Redshift via external tables. For more information, see Using Amazon Redshift Spectrum to Query External Data.
Creating a security/access control rule
While data masking can help in many cases to allow your Amazon Redshift users the appropriate access, you may need further enforcement of access control to filter out any operations that might violate your security strategy. DataSunrise can import database users’ and groups’ metadata from Amazon Redshift, which the DataSunrise administrator can use to configure the security profile. If you already have a set of users defined in your existing Redshift DB you don’t need to additionally recreate the users for DataSunrise. DataSunrise will use this list of users only to configure rules. DataSunrise does not modify any traffic related to the authentication process of database users by default.
- In the DataSunrise console, from the menu, choose Security > Rules.The following screenshot shows the Security Rules page:

- Choose Add Rule.The following screenshot shows the details you can enter to compose this new rule:

DataSunrise also allows you to compose your rule to restrict or allow certain users, applications, hosts, and so on from performing activities that you consider prohibited against particular objects or areas within your Amazon Redshift cluster.
The following screenshot shows the Filter Sessions page:
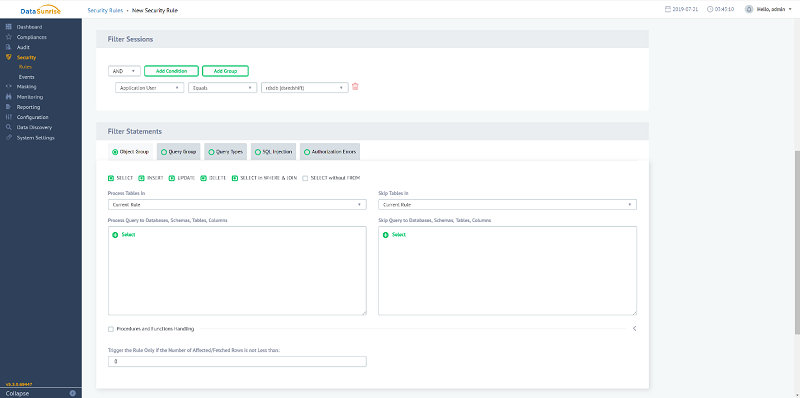
DataSunrise enables you to create rules for specific objects, query groups, query types, and SQL injection activities, and trigger actions when authorization errors occur.
Static masking doesn’t have a direct impact on performance, but if a customer uses the DataSunrise custom function, it could impact performance because custom functions execute on the DataSunrise server.
Using DataSunrise audit and compliance policies
From the console, Compliance > Add Compliance.
In the Compliance orchestrator page, you can initiate a scan of your Amazon Redshift cluster to identify all PII data or sensitive information in general, per your compliance standards. DataSunrise comes bundled with internal scans for HIPAA, GDPR, and other compliance standards, but you can create or amend any of those libraries to accommodate any special requirements that your security strategy mandates. The following screenshot shows the Add Compliance page:
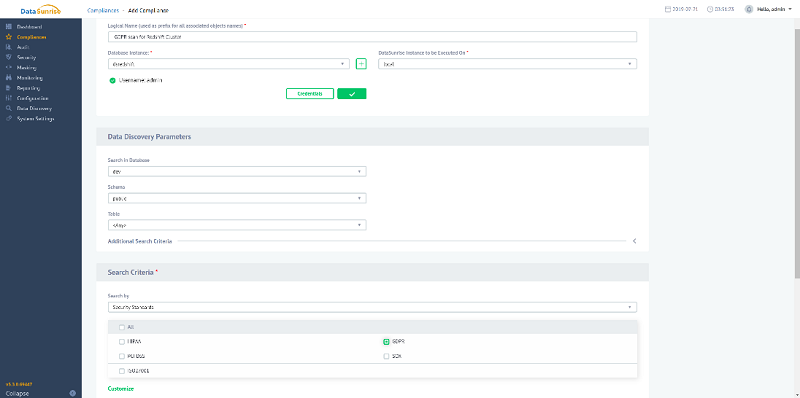
After completing the scan, DataSunrise guides you through the process of composing rules for sensitive information within your Amazon Redshift cluster.
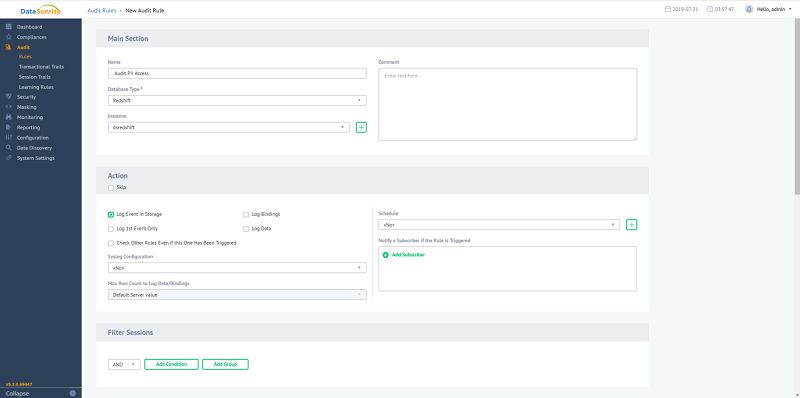
You can also create your audit rules manually. The following screenshot shows the New Audit Rule page:
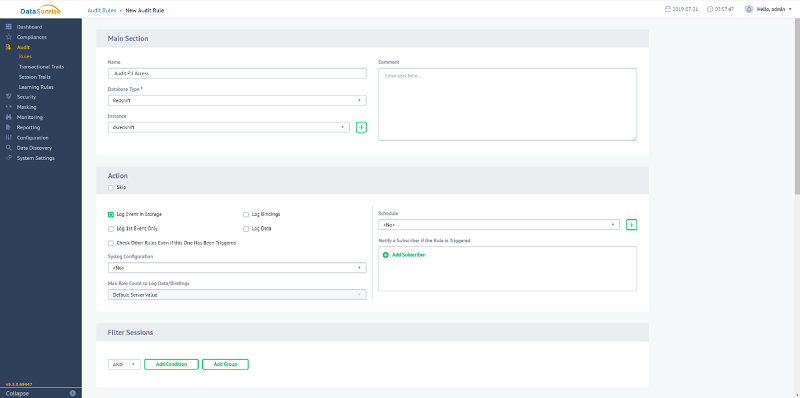
You can set audit rules for any restriction to make sure that transactional trails are only collected when necessary. You can target objects starting from the entire database down to a single column in your Amazon Redshift cluster. See the following screenshot:
Conclusion
DataSunrise’s masking feature allows for descriptive specifications of access control to sensitive columns, in addition to built-in encryption provided by the Amazon Redshift cluster. Its proxy enables more fine-grained access control, auditing, and masking capabilities to better monitor, protect, and comply with regulatory standards that address the ever-increasing needs of securing and protecting data. DataSunrise’s integration with Amazon Redshift addresses those concerns by simplifying and automating the security rules and its applications. Keep your data safe and protected at all times!
To get started with DataSunrise with Amazon Redshift, visit DataSunrise in AWS Marketplace.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
About the Authors
 Saunak Chandra is a senior partner solutions architect for Redshift at AWS.
Saunak likes to experiment with new products in the technology space, alongside his day to day work. He loves exploring the nature in the Pacific Northwest. A short hiking or biking in the trails is his favorite weekend morning routine. He also likes to do yoga when he gets time from his kid.
Saunak Chandra is a senior partner solutions architect for Redshift at AWS.
Saunak likes to experiment with new products in the technology space, alongside his day to day work. He loves exploring the nature in the Pacific Northwest. A short hiking or biking in the trails is his favorite weekend morning routine. He also likes to do yoga when he gets time from his kid.
 Radik Chumaren is an engineering leader at DataSunrise. Radik is specializing in heterogeneous database environments with focus on building database security software in the cloud. He enjoys reading and playing soccer.
Radik Chumaren is an engineering leader at DataSunrise. Radik is specializing in heterogeneous database environments with focus on building database security software in the cloud. He enjoys reading and playing soccer.