AWS Big Data Blog
Tag: AWS Lake Formation
Build an AWS Well-Architected environment with the Analytics Lens
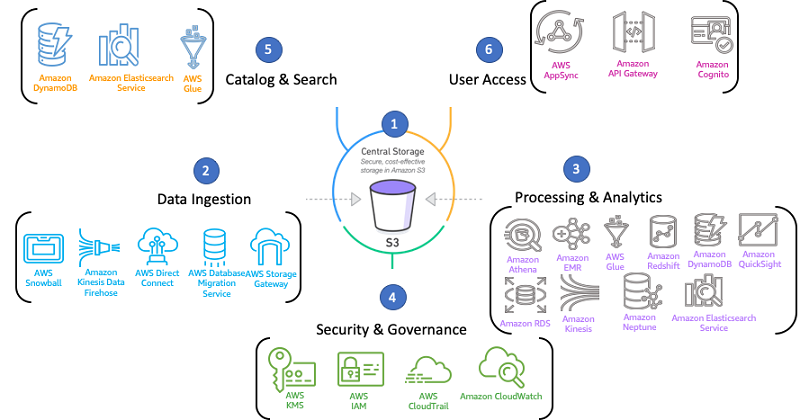
Building a modern data platform on AWS enables you to collect data of all types, store it in a central, secure repository, and analyze it with purpose-built tools. Yet you may be unsure of how to get started and the impact of certain design decisions. To address the need to provide advice tailored to specific technology and application domains, AWS added the concept of well-architected lenses 2017. AWS now is happy to announce the Analytics Lens for the AWS Well-Architected Framework. This post provides an introduction of its purpose, topics covered, common scenarios, and services included.

A public data lake for analysis of COVID-19 data
April 2024: This post was reviewed for accuracy. As the COVID-19 pandemic continues to threaten and take lives around the world, we must work together across organizations and scientific disciplines to fight this disease. Innumerable healthcare workers, medical researchers, scientists, and public health officials are already on the front lines caring for patients, searching for […]
Matching patient records with the AWS Lake Formation FindMatches transform
Patient matching is a major obstacle in achieving healthcare interoperability. Mismatched patient records and inability to retrieve patient history can cause significant barriers to informed clinical decision-making and result in missed diagnoses or delayed treatments. Additionally, healthcare providers often invest in patient data deduplication, especially when the number of patient records is growing rapidly in […]
Provisioning the Intuit Data Lake with Amazon EMR, Amazon SageMaker, and AWS Service Catalog
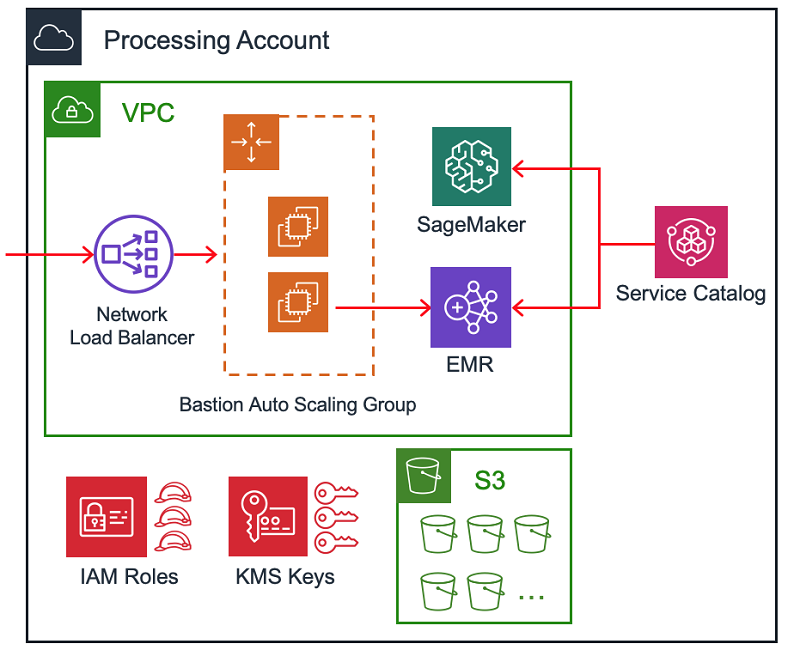
This post outlines the approach taken by Intuit, though it is important to remember that there are many ways to build a data lake (for example, AWS Lake Formation). We’ll cover the technologies and processes involved in creating the Intuit Data Lake at a high level, including the overall structure and the automation used in provisioning accounts and resources. Watch this space in the future for more detailed blog posts on specific aspects of the system, from the other teams and engineers who worked together to build the Intuit Data Lake.

Access and manage data from multiple accounts from a central AWS Lake Formation account
his post shows how to access and manage data in multiple accounts from a central AWS Lake Formation account. The walkthrough demonstrates a centralized catalog residing in the master Lake Formation account, with data residing in the different accounts. The post shows how to grant access permissions from the Lake Formation service to read, write and update the catalog and access data in different accounts.

Discover metadata with AWS Lake Formation: Part 2
In this post, you will learn how to use the metadata search capabilities of Lake Formation. By defining specific user permissions, Lake Formation allows you to grant and revoke access to metadata in the Data Catalog as well as the underlying data stored in S3.

Discovering metadata with AWS Lake Formation: Part 1
In this post, you will create and edit your first data lake using the Lake Formation. You will use the service to secure and ingest data into an S3 data lake, catalog the data, and customize the metadata of the data sources. In part 2 of this series, we will show you how to discover your data by using the metadata search capabilities of Lake Formation.

Getting started with AWS Lake Formation
June 2024: This post was reviewed and updated for accuracy. AWS Lake Formation enables you to set up a secure data lake. A data lake is a centralized, curated, and secured repository storing all your structured and unstructured data, at any scale. You can store your data as-is, without having first to structure it. And […]
Build, secure, and manage data lakes with AWS Lake Formation
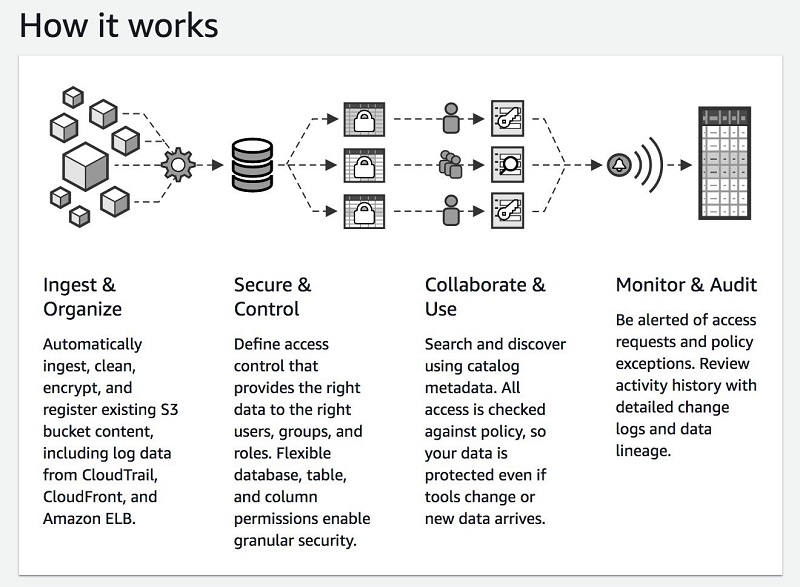
A data lake is a centralized store of a variety of data types for analysis by multiple analytics approaches and groups. Many organizations are moving their data into a data lake. In this post, we explore how you can use AWS Lake Formation to build, secure, and manage data lakes.