AWS Big Data Blog
Tag: AWS Lake Formation
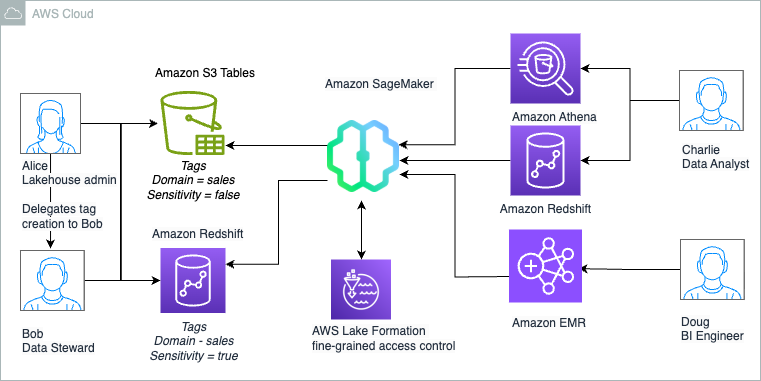
The Amazon SageMaker Lakehouse Architecture now supports Tag-Based Access Control for federated catalogs
We are now announcing support for Lake Formation tag-based access control (LF-TBAC) to federated catalogs of S3 Tables, Redshift data warehouses, and federated data sources such as Amazon DynamoDB, MySQL, PostgreSQL, SQL Server, Oracle, Amazon DocumentDB, Google BigQuery, and Snowflake. In this post, we illustrate how to manage S3 Tables and Redshift tables in the lakehouse using a single fine-grained access control mechanism of LF-TBAC. We also show how to access these lakehouse tables using your choice of analytics services, such as Athena, Redshift, and Apache Spark in Amazon EMR Serverless.

Configure cross-account access of Amazon SageMaker Lakehouse multi-catalog tables using AWS Glue 5.0 Spark
In this post, we show you how to share an Amazon Redshift table and Amazon S3 based Iceberg table from the account that owns the data to another account that consumes the data. In the recipient account, we run a join query on the shared data lake and data warehouse tables using Spark in AWS Glue 5.0. We walk you through the complete cross-account setup and provide the Spark configuration in a Python notebook.

Read and write Apache Iceberg tables using AWS Lake Formation hybrid access mode
In this post, we demonstrate how to use Lake Formation for read access while continuing to use AWS Identity and Access Management (IAM) policy-based permissions for write workloads that update the schema and upsert (insert and update combined) data records into the Iceberg tables.

The AWS Glue Data Catalog now supports storage optimization of Apache Iceberg tables
The AWS Glue Data Catalog now enhances managed table optimization of Apache Iceberg tables by automatically removing data files that are no longer needed. Along with the Glue Data Catalog’s automated compaction feature, these storage optimizations can help you reduce metadata overhead, control storage costs, and improve query performance. Iceberg creates a new version called […]
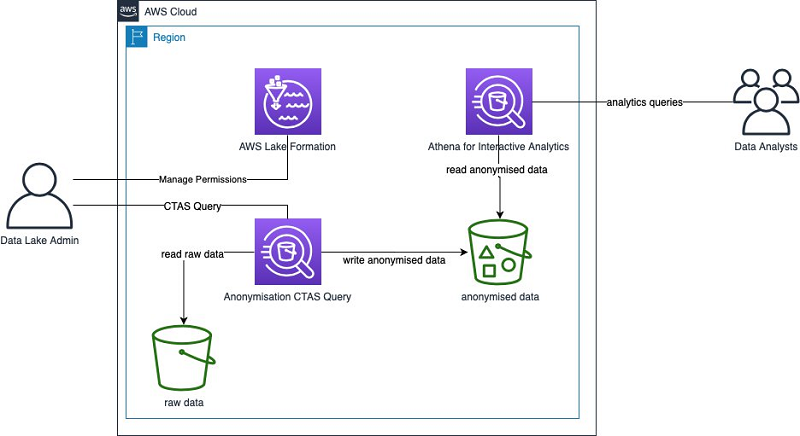
Anonymize and manage data in your data lake with Amazon Athena and AWS Lake Formation
Most organizations have to comply with regulations when dealing with their customer data. For that reason, datasets that contain personally identifiable information (PII) is often anonymized. A common example of PII can be tables and columns that contain personal information about an individual (such as first name and last name) or tables with columns that, if joined with another table, can trace back to an individual. You can use AWS Analytics services to anonymize your datasets. In this post, I describe how to use Amazon Athena to anonymize a dataset. You can then use AWS Lake Formation to provide the right access to the right personas.
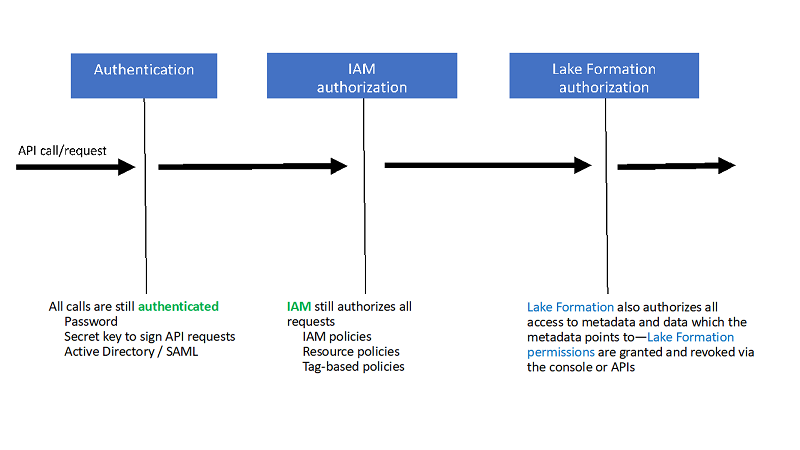
Enable fine-grained data access in Zeppelin Notebook with AWS Lake Formation
This post explores how you can use AWS Lake Formation integration with Amazon EMR (still in beta) to implement fine-grained column-level access controls while using Spark in a Zeppelin Notebook. My previous post Extract Salesforce.com data using AWS Glue and analyzing with Amazon Athena showed you a simple use case for extracting any Salesforce object data using AWS Glue and Apache Spark, saving it to Amazon Simple Storage Service (Amazon S3), cataloging the data using the Data Catalog in Glue, and querying it using Amazon Athena.
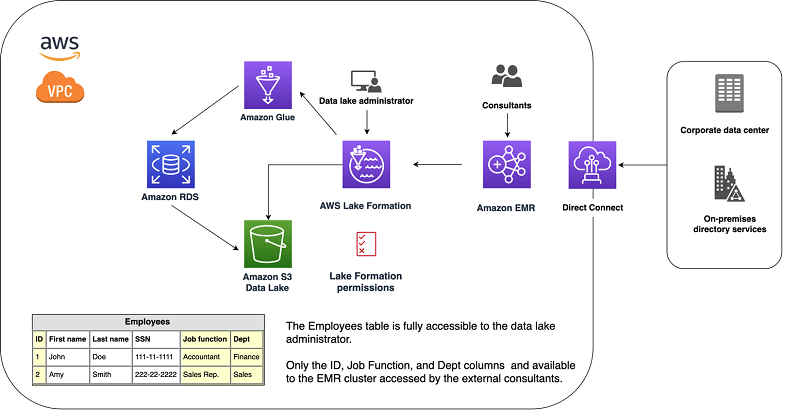
Control data access and permissions with AWS Lake Formation and Amazon EMR
What if you could control the access to your data lake centrally? Would it be more convenient to share specific data securely with internal and external customers? With AWS Lake Formation and its integration with Amazon EMR, you can easily perform these administrative tasks. This post goes through a use case and reviews the steps to control the data access and permissions of your existing data lake.

Enable fine-grained permissions for Amazon QuickSight authors in AWS Lake Formation
This post demonstrates how to extend the Lake Formation security model to QuickSight users and groups, which allows data lake administrators to manage data catalog resource permissions centrally from one console. As organizations embark on the journey to secure their data lakes with Lake Formation, having the ability to centrally manage fine-grained permissions for QuickSight authors can extend the data governance and enforcement of security controls at the data consumption (business intelligence) layer. You can enable these fine-grained permissions for QuickSight users and groups at the database, table, or column level, and they’re reflected in the Athena dataset in QuickSight.

Enforce column-level authorization with Amazon QuickSight and AWS Lake Formation
Amazon QuickSight is a fast, cloud-powered, business intelligence service that makes it easy to deliver insights and integrates seamlessly with your data lake built on Amazon Simple Storage Service (Amazon S3). QuickSight users in your organization often need access to only a subset of columns for compliance and security reasons. Without having a proper solution […]
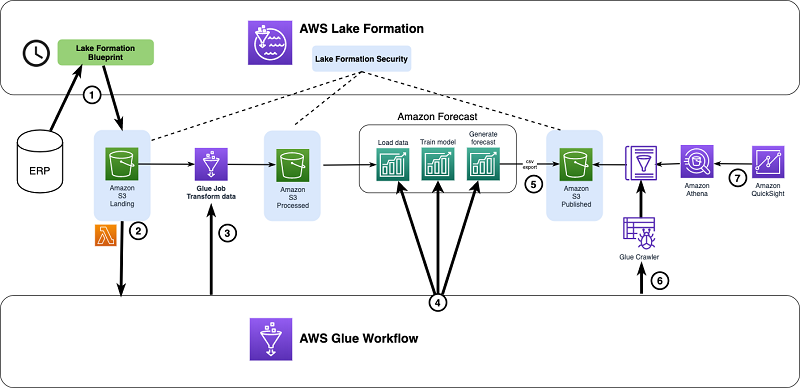
Build an end to end, automated inventory forecasting capability with AWS Lake Formation and Amazon Forecast
This post demonstrates how you can automate the data extraction, transformation, and use of Forecast for the use case of a retailer that requires recurring replenishment of inventory. You achieve this by using AWS Lake Formation to build a secure data lake and ingest data into it, orchestrate the data transformation using an AWS Glue workflow, and visualize the forecast results in Amazon QuickSight.