AWS Database Blog
Ring’s Billion-Scale Semantic Video Search with Amazon RDS for PostgreSQL and pgvector
When you use Ring’s semantic video search to find specific moments: “a dog in my backyard,” “a package delivery,” or “someone wearing a blue shirt” – you expect instant, accurate results that combine time, space, and events to surface the right footage from days or weeks of recordings. Delivering this kind of semantic video search, where the system understands the meaning of a query rather than relying on exact keyword matches, requires a new approach with PostgreSQL and pgvector optimized for storing and searching video data at billion-scale.
In this post, we share Ring’s billion-scale semantic video search on Amazon RDS for PostgreSQL with pgvector architectural decisions vs alternatives, cost-performance-scale challenges, key lessons, and future directions. The Ring team designed for global scale their vector search architecture to support millions of customers with vector embeddings, the key technology for numerical representations of visual content generated by an AI model. By converting video frames into vectors-arrays of numbers that capture what’s happening (visual content) in each frame – Ring can store these representations in a database and search them using similarity search. When you type “package delivery,” the system converts that text into a vector and finds the video frames whose vectors are most similar-delivering relevant results in under 2 seconds.
Searching video at global scale
Ring’s mission is simple but ambitious: to make neighborhoods safer. For over 12 years, Ring has worked to perfect the clarity and reliability of video technology so neighbors can keep an eye on what matters most-whether its family members arriving home safely from school or a beloved pet that has wandered too far. To accomplish this mission, Ring generates massive volumes of video data daily across millions of devices worldwide.
The video search system operates at massive scale. Across 4 continents and 9 AWS Regions, the solution serves billions of read requests daily while maintaining strict latency requirements for millions of customers.
|
Metric |
Scale |
|
Embeddings Stored |
100–200 billion |
|
Daily New Embeddings |
~2 billion |
|
Data Footprint |
140–150+ TB across 3 PostgreSQL clusters |
|
Latency Target |
<200ms (p50), <2 seconds (worst case) |
|
Read/Write Ratio |
~80% reads, ~20% writes |
|
Global Presence |
4 continents, 9 AWS Regions |
Traditional metadata-based search-relying on tags, timestamps, or manual annotations-could not support natural-language queries. Ring needed a fundamentally different approach capable of similarity search at massive scale, real-time ingestion without degrading query performance, per-user data isolation with strict privacy alignment, and operational resilience across regions to handle event-driven traffic spikes such as Halloween, when doorbell activity surges.
Evaluating alternatives
Before committing to a production architecture, the engineering team ran a structured evaluation across three dimensions: cost, query latency, and operational complexity.
Purpose-built vector databases
Several dedicated vector search solutions made the initial shortlist. On paper, they offered compelling capabilities — purpose-built indexing, managed approximate nearest neighbor (ANN) search, and native embedding workflows. In practice, however, they didn’t fit Ring’s profile. At the query volume and data scale, the cost structure was prohibitive. These systems are optimized for hybrid keyword/vector search patterns; the workload is almost exclusively dense-vector retrieval, making the added complexity difficult to justify.
At Ring’s scale of 100–200 billion embeddings, ~2 billion added daily, purpose-built vector databases were prohibitively expensive. Building on Amazon RDS for PostgreSQL with pgvector avoided significant infrastructure costs while alleviating ongoing index maintenance overhead — freeing engineering teams to focus on features, not operations.
The S3-backed ANN prototype
The team also explored a custom ANN pipeline using Amazon Simple Storage Service (Amazon S3) as the embedding store. The architecture was straightforward: store high-dimensional embedding vectors in S3, pull them down to the compute tier at query time, and run nearest-neighbor search in memory. It worked — but not fast enough. The round-trip latency of fetching embeddings from object storage consistently blew past Ring’s sub-2-second end-to-end service level agreement (SLA). The experiment was valuable precisely because it confirmed a hard architectural constraint: vector data and query execution must be co-located. There’s no way to abstract that away with caching or prefetching to meet the latency requirements.
Why RDS for PostgreSQL with pgvector won
With purpose-built vector database solutions ruled out on cost and fit, and the S3 prototype ruled out on latency, the team converged on RDS for PostgreSQL with the pgvector extension. The decision was pragmatic but well-reasoned.
The engineers already had deep PostgreSQL operational expertise — schema design, query tuning, replication, observability. Introducing a net-new vector database would have meant onboarding an entirely separate system: new failure modes, new operational runbooks, new monitoring gaps. With pgvector, the team got native ANN search — via hierarchical navigable small worlds (HNSW) or Inverted File Flat (IVFFlat) indexing — directly inside the database engine they already trusted and understood.
As Ring’s engineers put it plainly: “We use PostgreSQL as a vector database.” That’s not a workaround. It’s a deliberate architectural choice that consolidates relational and vector workloads into a single, well-understood tier — and one that met every production requirement without adding operational surface area.
By choosing Amazon RDS for PostgreSQL with pgvector, Ring transformed what could have been a costly infrastructure expansion into a capability extension. The architecture consolidates relational and vector workloads into a single, operationally optimized tier—meeting production requirements for cost, latency, and reliability without adding new failure modes or separate database infrastructure. This approach preserves headroom to scale beyond billion embeddings without architectural redesign, proving that the right choice is the one that fits your operational reality.
Solution overview: semantic video search with pgvector
The AI Video Search uses the Contrastive Language-Image Pre-training (CLIP) model to enable you to search video footage using natural-language queries. While CLIP is a model that supports multiple input modalities (text and images), Ring’s implementation specifically uses the model to generate vector embeddings from video frames captured at regular intervals. The system stores embeddings in a database and the embeddings are searched against text-based query embeddings to find the most relevant moments. The architecture uses managed AWS services to process billions of video frames daily while maintaining sub-second query latency.
Video ingestion and embedding generation
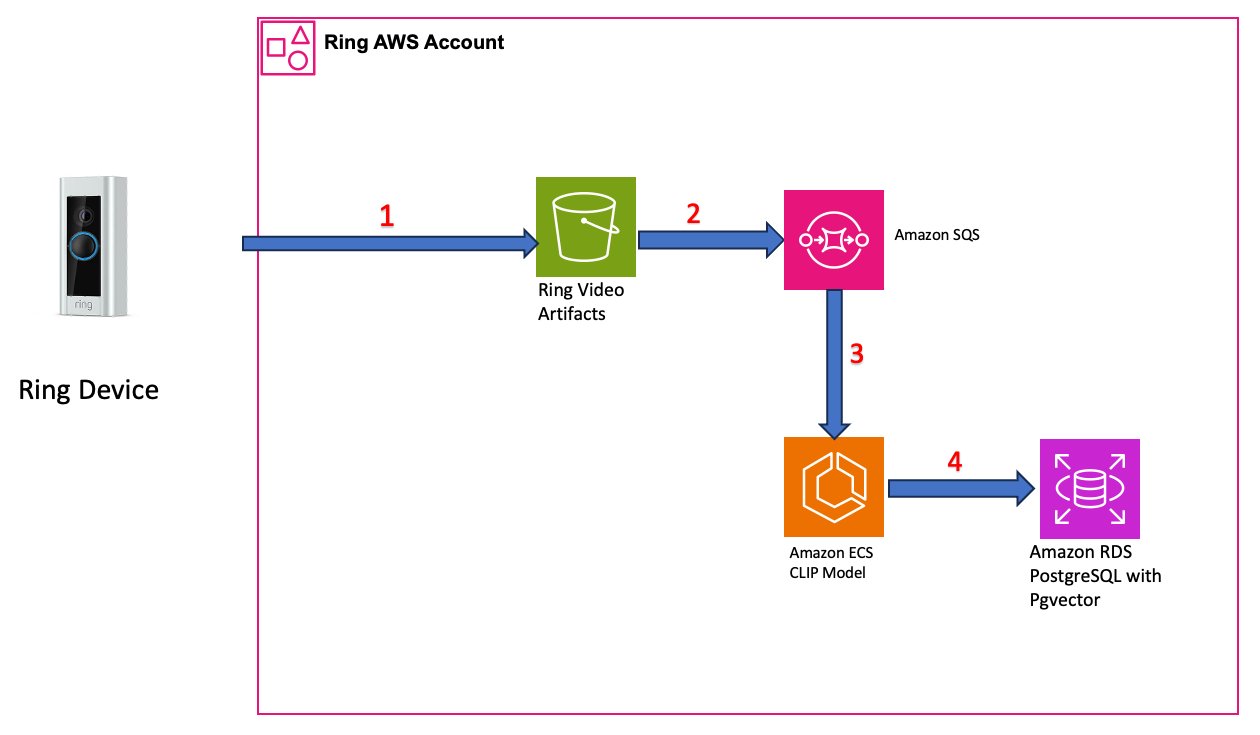
Figure 1: Video ingestion and embedding generation pipeline
- Video capture: Videos from Ring devices are stored in Amazon S3 buckets.
- Event-driven processing: S3 event notifications trigger processing workflows via Amazon Simple Queue Service (Amazon SQS) queues, which buffer incoming requests and decouple ingestion from processing-critical for handling traffic spikes during high-activity periods.
- Embedding generation: The CLIP model, running on GPU-accelerated Amazon Elastic Container Service (Amazon ECS) instances, extracts frames at regular intervals from video recordings and generates 768-dimension vector embeddings for each frame. Each embedding captures the visual content of that moment in a format suitable for similarity search.
- Vector storage: Amazon RDS for PostgreSQL using the pgvector extension stores embeddings. Each video frame becomes a searchable record to find specific moments across weeks of footage.
Search query flow
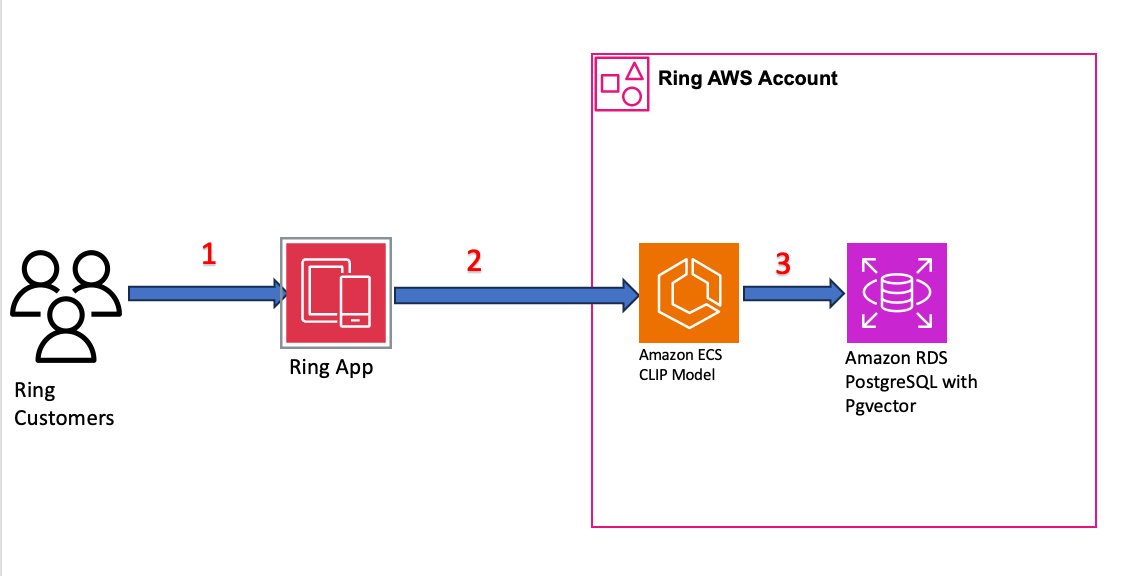
Figure 2: Search query flow from user request to ranked results
- Natural-language query: A Ring user enters a search query such as “dog in my backyard” or “package delivery.”
- Query embedding: The query text is converted into a 768-dimension embedding using the same CLIP model used during ingestion.
- Similarity search: RDS for PostgreSQL performs similarity search using pgvector’s dot-product (inner product) distance operator across the user’s stored embeddings. Ring selected the dot-product operator for its computational efficiency with normalized embedding vectors.
- Ranked results: The database returns the most relevant video segments ranked by similarity score, delivering results to you in under 2 seconds.
Deep dive: architectural decisions
The architecture reflects several unconventional decisions that proved critical to achieving performance at this scale. Each was informed by extensive testing and the unique characteristics of video search workloads.
User-based table partitioning
The most impactful architectural decision was implementing table partitioning by user. Rather than storing embeddings in a single massive table, Ring creates a dedicated partition for each user’s data. The partition identifier combines user ID, device ID, and model version. Adding the model version supports straightforward upgrades when the embedding model changes.
The schema for each partition:
This partitioning strategy provides several benefits:
- Query performance: The PostgreSQL query optimizer uses partition constraints to skip irrelevant data, scanning only the target user’s partition (~1 GB) rather than the full dataset.
- Data isolation: Each user’s data is logically separated, supporting privacy and avoiding noisy-neighbor effects.
- Lifecycle management: Partitions can be created during user onboarding and dropped instantly when features are disabled or subscriptions expire-no expensive DELETE operations required.
- Model versioning: Including the model version in the partition identifier allows Ring to maintain embeddings from different model generations side by side, enabling gradual rollouts of improved CLIP models without re-embedding historical data.
Brute-force parallel search with dot-product distance: no vector indexes
In one of the most counterintuitive decisions in the architecture, Ring chose to avoid traditional vector indexes entirely. Instead of using pgvector’s built-in approximate nearest-neighbor (ANN) index methods like HNSW or IVFFlat, the team relies on brute-force parallel sequential scans within each user partition, using pgvector’s dot-product (inner product) distance operator to rank results.
The team evaluated ANN indexes early in development but dropped the approach without pursuing a deep comparison. The reason was straightforward: the video search use case demands 100% recall rate. When a user searches for “dog in my backyard,” every matching moment must be found. ANN indexes improve speed at the cost of recall — a compromise Ring’s video search use case simply could not accept, as loss in accuracy would directly degrade the user experience.This approach works because of several factors working in concert:
- Small partition size: Each user’s partition is approximately 1 GB-small enough to scan efficiently with parallel workers.
- Aggressive parallelism: Setting
max_parallel_workers_per_gather = 16enables PostgreSQL to spawn enough workers to fully utilize Amazon Elastic Block Store (Amazon EBS) bandwidth during partition scans. - Zero index maintenance: With ~2 billion new embeddings ingested daily, avoiding index builds and maintenance alleviates a significant operational burden and avoids write amplification.
- 100% recall: Brute-force search makes sure that every relevant result is returned-critical for a feature where missing a specific moment degrades user trust.
Multi-cluster routing strategy
Ring distributes data across 4 PostgreSQL clusters per Region using an assignment-based routing strategy. When a device is onboarded to the video search service, a weighted algorithm assigns it to a cluster based on current cluster size and capacity. This assignment is stored in Amazon DynamoDB – chosen for its single-digit millisecond read latency and global availability-and remains fixed for the device’s lifetime, making sure the queries for a given user route to the same cluster that holds their data.
This approach provides natural horizontal scaling: as the user base grows, new clusters can be added and the weighting algorithm adjusted to direct new devices to clusters with available capacity. Data is partitioned across clusters so that if an entire cluster becomes unavailable, the impact is limited to only the subset of users served by that cluster.
EBS-optimized instance selection
Through extensive testing, Ring determined that EBS throughput was the primary bottleneck for their scan-heavy workload. The team tested across multiple instance families and sizes within the r6id family. A key finding was that the EBS-optimized instances delivered comparable I/O throughput, regardless of instance size. The performance differences between sizes were primarily driven by CPU and RAM (which affects buffer cache hit rates), not raw EBS capability. This counterintuitive result confirmed that EBS-optimized networking-not instance size-was the critical factor.
|
Instance Type |
EBS Throughput (MB/s) |
EBS IOPS |
Avg Query Latency (ms) |
| db.r6id.4xlarge | 489 | 3,861 | 1,504 |
| db.r6id.8xlarge | 566 | 4,465 | 1,292 |
| db.r6id.16xlarge | 529 | 4,208 | 1,359 |
Table: EBS performance across instance types (687 MB per partition, no vector indexes). Note that the 16xlarge instance did not outperform the 8xlarge-confirming that EBS throughput, not instance size, is the determining factor for this workload.
This insight allowed Ring to right-size instances for cost efficiency rather than over-provisioning to larger instance types that would not yield proportional performance gains.
Performance challenges and solutions
Ring encountered two major performance challenges during production rollout that required architectural refinements to maintain sub-second query latency at global scale.
Challenge 1: Cold-start latency
Initial proof-of-concept (PoC) testing showed excellent sub-2-second performance. However, after 2 months in production serving customer traffic, latencies spiked to over 10 seconds for certain queries. Investigation revealed that PoC testing had inadvertently relied on cached data, masking a critical architectural reality: RDS for PostgreSQL stores data on Amazon EBS volumes, not on local instance storage.
When data was not resident in PostgreSQL’s shared buffer cache, queries required EBS I/O roundtrips, introducing significant latency. PostgreSQL allocates 25% of instance RAM to shared buffers by default, meaning data beyond this threshold had to be fetched from EBS on first access. This behavior was especially pronounced on read replicas and after failover events, where instances started with completely cold caches.
Solution: pg_prewarm, read optimized instances, and buffer management
The team implemented a multi-layered approach to address cold-start latency. First, they deployed automated pg_prewarm scripts that preload frequently accessed user partitions into shared buffers during read replica initialization and after failover events. Additionally, Ring relies on RDS Read Optimized Instances (r6id family with local NVMe storage), which provide a local storage tier that complements EBS and helps reduce read latency for frequently accessed data. Combined with their custom buffer management strategy, this approach trades startup time for consistent query performance:
|
Scenario |
Query Latency |
|
Cold instance (no buffer cache) |
~10,500 ms |
|
After pg_prewarm |
<300 ms |
|
Sustained (subsequent queries, same user) |
Sub-second |
The 35x improvement from cold to warmed instances underscores the importance of buffer management for EBS-backed PostgreSQL deployments at this scale.
Challenge 2: Under-utilized EBS bandwidth
Performance testing revealed that single-threaded queries achieved only ~50 MB/s throughput against db.r6id instances capable of 500+ MB/s-leaving over 90% of available EBS bandwidth unused. The root cause was PostgreSQL’s default query execution: the optimizer typically spawned only 2–4 parallel workers, which could not generate enough concurrent I/O operations to optimally utilize the available EBS bandwidth.
Solution: Aggressive Parallel Execution
The team configured max_parallel_workers_per_gather = 16, enabling PostgreSQL to spawn enough parallel workers to fully utilize available EBS bandwidth. Combined with user-based partitioning (which avoided the need for index-driven query plans that prevented parallelism), this configuration allowed parallel sequential scans to drive EBS throughput from ~50 MB/s to 489–590 MB/s.
This optimization was only possible because Ring had deliberately removed traditional indexes from their partitions. With indexes present, PostgreSQL’s query optimizer preferred index scans over parallel sequential scans, inadvertently limiting I/O concurrency. Removing indexes forced the optimizer to choose parallel scans-a counterintuitive decision that unlocked an order-of-magnitude improvement in throughput.
Production performance
In production, the architecture delivers consistent low-latency performance across its global deployment:
|
Percentile |
Target |
Actual |
|
P50 |
<200 ms |
~200 ms |
|
P95 |
<2,000 ms |
~600 ms |
|
P99 |
<2,000 ms |
~600 ms (occasional spikes to 7–8s) |
The workload is heavily read-dominant (~80% reads, ~20% writes), with peak search traffic of approximately 300 requests per minute. Read and write latencies are not directly comparable: read operations scan a user’s entire embedding history, while writes involve storing individual video event embeddings. The system currently uses halfvec for storage optimization.
Reliability and operations
The reliability strategy centers on Amazon RDS Multi-AZ deployments at the cluster level for automated failover. Each PostgreSQL cluster operates as an independent unit with its own set of user partitions. Data is distributed across clusters so that a single cluster failure limits the impact to only those who are assigned to that cluster, rather than causing a global outage.
For monitoring, the team uses Amazon CloudWatch with a combination of built-in RDS metrics and custom application metrics, backed by CloudWatch alarms for automated alerting. Key metrics tracked include EBS throughput and IOPS utilization, query latency distributions, buffer cache hit rates, and cluster-level connection counts.
ML and embedding pipeline
Ring’s embedding pipeline is powered by the Contrastive Language-Image Pre-training (CLIP) model, which generates 768-dimension vector representations of video frames. CLIP was a natural fit for the use case because it produces aligned embeddings for both images and text in the same vector space – meaning a text query like “dog in my backyard” and a video frame showing a dog in a yard will produce vectors that are close together in 768-dimensional space. The 768 dimensions are inherent to the CLIP model architecture rather than a tunable parameter and provide a rich representation that balances accuracy with storage efficiency at scale.
The implementation uses the model’s image encoding capabilities to process video frames at regular intervals – extracting one frame from every few frames of video and generating an embedding for each. These embeddings capture the visual content of each moment in a format optimized for similarity search. The partition schema includes a model_version field, which allows Ring to maintain embeddings from different CLIP model generations side by side. This design allows gradual rollouts of improved models without requiring bulk re-embedding of historical data – new embeddings are simply written to new model-versioned partitions while older partitions continue to serve queries until retired.
Lessons learned
The journey to billion-scale vector search revealed several key insights about PostgreSQL performance at extreme scale.
- Design for EBS behavior from day one. RDS for PostgreSQL stores data on Amazon EBS. Understanding throughput limits, buffer cache behavior, and cold-start latency characteristics should inform architecture decisions before the first line of code is written-not after production issues surface.
- Partition strategically for your access pattern. User-based partitioning was the single most impactful optimization. It simultaneously improved query performance, simplified data lifecycle management, supported model versioning, and-crucially-unlocked parallel query execution by alleviating the need for traditional indexes.
- Test with cold caches. PoC results that rely on warmed buffer caches can misrepresent production behavior. Validate performance with cold instances and realistic data distributions to avoid surprises after launch.
- Challenge conventional indexing wisdom. For workloads requiring 100% recall rate on bounded per-user datasets, brute-force parallel scans can outperform ANN indexes while alleviating index maintenance overhead. This is especially true when combined with aggressive parallelism and EBS-optimized instances.
- Validate I/O throughput for your specific workload. EBS-optimized instances vary in their ability to utilize available bandwidth. Testing across instance families and tuning PostgreSQL’s parallel worker configuration can unlock order-of-magnitude throughput improvements.
What’s next?
Ring continues to evaluate next-generation AWS capabilities and architectural improvements to further optimize their solution:
- Amazon Aurora PostgreSQL-Compatible Edition: During the initial evaluation, we tested both, Amazon Aurora for PostgreSQL and Amazon RDS for PostgreSQL. Based on their specific workload characteristics at the time, particularly cold-data access patterns that favored provisioned IOPS on RDS, the team selected RDS for PostgreSQL. As Aurora PostgreSQL and pgvector capabilities have continued to evolve significantly, Ring is actively evaluating Aurora to optimize operations and reduce the overhead of managing multiple RDS clusters. As the team noted, “The solution works well and within key performance indicators (KPIs) but launching new clusters and operating them is not very efficient.” The automatic sharding and horizontal scaling capabilities of Aurora could simplify Ring’s multi-cluster architecture significantly.
- Caching and performance optimization: Ring is exploring additional caching strategies, including evaluating Amazon ElastiCache, to complement their pg_prewarm approach and further reduce latency for frequently accessed user data.
- Next-generation vector indexing: As pgvector continues to mature with improved HNSW and IVFFlat implementations, Ring plans to re-evaluate whether hybrid approaches (indexed pre-filtering with brute-force final ranking) could further reduce latency while maintaining recall assurances.
- Improved ingestion pipelines: Handling event-driven spikes more efficiently, particularly during high-activity periods like Halloween when doorbell activity surges.
- Lower tail latency: Reducing P99 latency spikes to consistently meet the sub-2-second SLA.
- Next-generation embedding models: Ring continues to evaluate improved embedding models that may offer higher accuracy, smaller dimensions, or better performance characteristics for video search workloads.
Conclusion
By combining PostgreSQL, pgvector, and AWS managed database services, Ring built a large-scale production vector search solution in the industry-powering real-time semantic video search for millions of users across 9 AWS Regions. Their architecture demonstrates that careful decisions around partitioning, parallel execution, and buffer management can allow PostgreSQL to scale to hundreds of billions of vectors while maintaining sub-second query performance.
The willingness to challenge conventional wisdom-removing vector indexes in favor of brute-force parallel search, partitioning by user rather than using a monolithic table, and deeply understanding EBS storage behavior-resulted in a system that is both simpler to operate and higher performing than approaches relying on specialized vector databases or complex ANN indexing strategies.
For teams evaluating vector search at scale on AWS, Ring’s journey offers a powerful lesson: PostgreSQL with pgvector can handle some of the most demanding vector workloads in production when paired with thoughtful architectural decisions and deep understanding of the underlying storage and compute infrastructure. Start by evaluating your vector search requirements with a cold-cache baseline benchmark.